
私自身について少し:私は初心者の開発者でもあり、「Python開発者」のコースを受講しています。この資料は、リモートセンシングの結果としてではなく、自己開発の順序で編集されました。私のコードはかなりナイーブかもしれませんので、コメントにコメントを残してください。私がまだあなたを怖がらせていないのなら、カットの下でお願いします:)
重複データを含むフラットテーブルを3NFの状態(第3正規形)に正規化する実際的な例を分析します。
この表から:
データ表

そのようなデータベースを作りましょう:
DB接続図
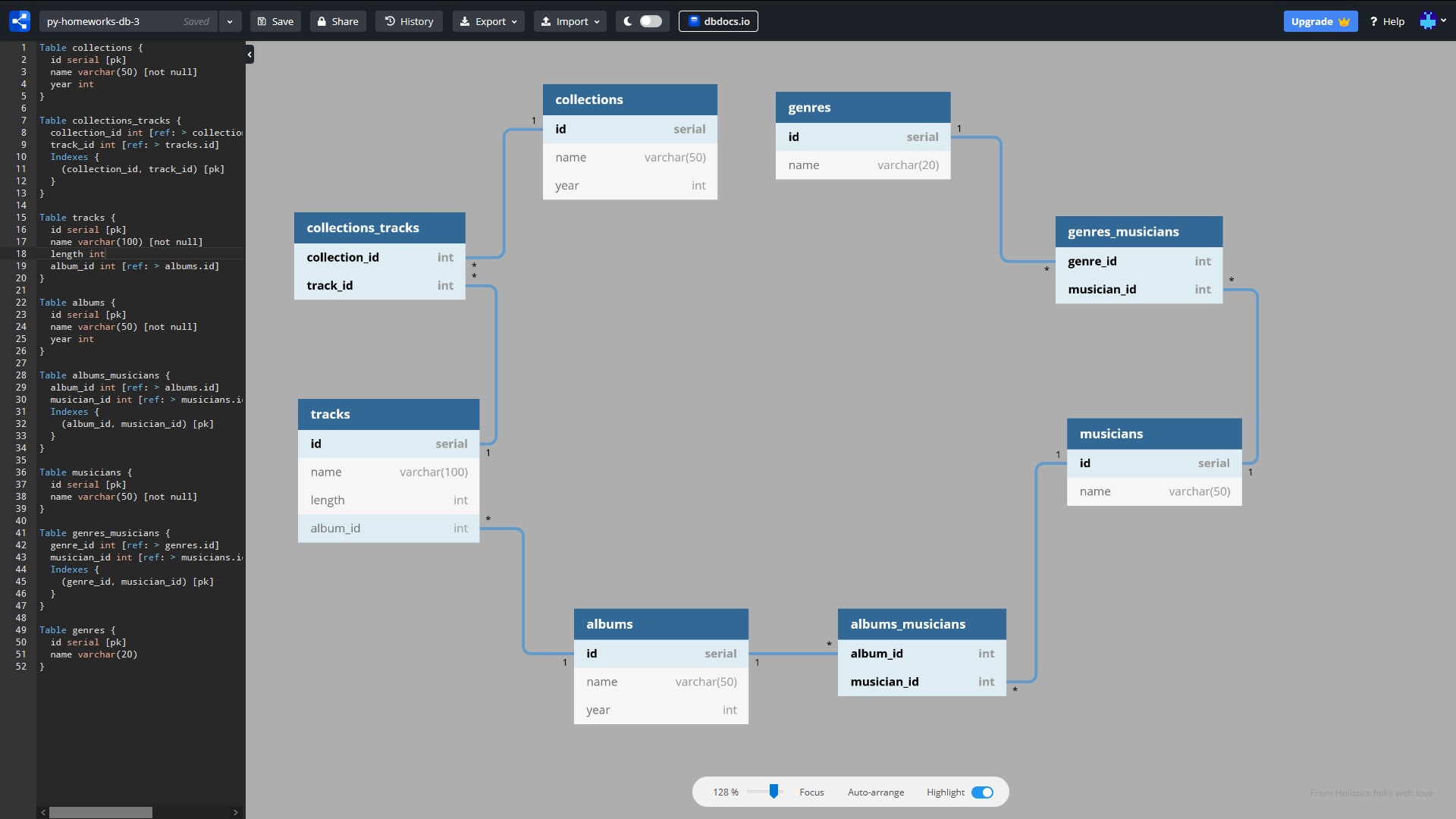
せっかちな人のために:実行する準備ができているコードはこのリポジトリにあります。インタラクティブDBスキーマはこちら。ORMクエリを作成するためのチートシートは記事の最後にあります。
記事のテキストでは、「関係」の代わりに「テーブル」という単語を使用し、「属性」の代わりに「フィールド」という単語を使用することに同意しましょう。割り当て時に、データの冗長性を排除しながら、データベースに音楽ファイルを含むテーブルを配置する必要があります。元のテーブル(CSV形式)には、次のフィールド(track、genre、musician、album、length、album_year、collection、collection_year)が含まれています。それらの間の接続は次のとおりです。
- 各ミュージシャンは複数のジャンルで歌うことができ、複数のミュージシャンは1つのジャンルで演奏することができます(多対多の関係)
- 1人または複数のミュージシャンがアルバムの作成に参加できます(多対多の関係)
- トラックは1つのアルバムにのみ属します(1対多の関係)
- トラックはいくつかのコレクションに含めることができます(多対多の関係)
- トラックをコレクションに含めることはできません。
簡単にするために、ジャンル名、アーティスト名、アルバム名、コレクション名は繰り返されていないとしましょう。トラック名は繰り返すことができます。データベースに8つのテーブルを設計しました。
- ジャンル(ジャンル)
- genres_musicians(ステージングテーブル)
- ミュージシャン(ミュージシャン)
- albums_musicians(中間テーブル)
- アルバム(アルバム)
- トラック
- collections_tracks(ステージングテーブル)
- コレクション(コレクション)
*このスキームは、DZの1つから取得したテストであり、いくつかの欠点があります。たとえば、トラックとミュージシャン、およびトラックとジャンルの間に接続がありません。しかし、これは学習に不可欠ではないため、この欠点は省略します。
テストのために、ローカルのPostgresに「TestSQL」と「TestORM」の2つのデータベースを作成し、それらにアクセスします。ログインとパスワードのテストです。いよいよコードを書いてみましょう!
接続とテーブルを作成する
データベースへの接続を作成します
* read_data関数とclear_db関数のコードはリポジトリにあります。
DSN_SQL = 'postgresql://test:test@localhost:5432/TestSQL'
DSN_ORM = 'postgresql://test:test@localhost:5432/TestORM'
# CSV .
DATA = read_data('data/demo-data.csv')
print('Connecting to DB\'s...')
# , .
engine_orm = sa.create_engine(DSN_ORM)
Session_ORM = sessionmaker(bind=engine_orm)
session_orm = Session_ORM()
engine_sql = sa.create_engine(DSN_SQL)
Session_SQL = sessionmaker(bind=engine_sql)
session_sql = Session_SQL()
print('Clearing the bases...')
# . .
clear_db(sa, engine_sql)
clear_db(sa, engine_orm)
SQLを使用して従来の方法でテーブルを作成します
* read_query . .
print('\nPreparing data for SQL job...')
print('Creating empty tables...')
session_sql.execute(read_query('queries/create-tables.sql'))
session_sql.commit()
print('\nAdding musicians...')
query = read_query('queries/insert-musicians.sql')
res = session_sql.execute(query.format(','.join({f"('{x['musician']}')" for x in DATA})))
print(f'Inserted {res.rowcount} musicians.')
print('\nAdding genres...')
query = read_query('queries/insert-genres.sql')
res = session_sql.execute(query.format(','.join({f"('{x['genre']}')" for x in DATA})))
print(f'Inserted {res.rowcount} genres.')
print('\nLinking musicians with genres...')
# assume that musician + genre has to be unique
genres_musicians = {x['musician'] + x['genre']: [x['musician'], x['genre']] for x in DATA}
query = read_query('queries/insert-genre-musician.sql')
# this query can't be run in batch, so execute one by one
res = 0
for key, value in genres_musicians.items():
res += session_sql.execute(query.format(value[1], value[0])).rowcount
print(f'Inserted {res} connections.')
print('\nAdding albums...')
# assume that albums has to be unique
albums = {x['album']: x['album_year'] for x in DATA}
query = read_query('queries/insert-albums.sql')
res = session_sql.execute(query.format(','.join({f"('{x}', '{y}')" for x, y in albums.items()})))
print(f'Inserted {res.rowcount} albums.')
print('\nLinking musicians with albums...')
# assume that musicians + album has to be unique
albums_musicians = {x['musician'] + x['album']: [x['musician'], x['album']] for x in DATA}
query = read_query('queries/insert-album-musician.sql')
# this query can't be run in batch, so execute one by one
res = 0
for key, values in albums_musicians.items():
res += session_sql.execute(query.format(values[1], values[0])).rowcount
print(f'Inserted {res} connections.')
print('\nAdding tracks...')
query = read_query('queries/insert-track.sql')
# this query can't be run in batch, so execute one by one
res = 0
for item in DATA:
res += session_sql.execute(query.format(item['track'], item['length'], item['album'])).rowcount
print(f'Inserted {res} tracks.')
print('\nAdding collections...')
query = read_query('queries/insert-collections.sql')
res = session_sql.execute(query.format(','.join({f"('{x['collection']}', {x['collection_year']})" for x in DATA if x['collection'] and x['collection_year']})))
print(f'Inserted {res.rowcount} collections.')
print('\nLinking collections with tracks...')
query = read_query('queries/insert-collection-track.sql')
# this query can't be run in batch, so execute one by one
res = 0
for item in DATA:
res += session_sql.execute(query.format(item['collection'], item['track'])).rowcount
print(f'Inserted {res} connections.')
session_sql.commit()
実際、パッケージ(ジャンル、ミュージシャン、アルバム、コレクション)にディレクトリを作成し、ループで残りのデータをリンクして、手動で中間テーブルを作成します。コードを実行して、データベースが作成されたことを確認します。重要なことは、セッションでcommit()を呼び出すことを忘れないことです。
今、私たちは同じことをしようとしていますが、ORMアプローチを使用しています。ORMを使用するには、データクラスを記述する必要があります。このために、8つのクラス(テーブルごとに1つ)を作成します。
DBクラスのリスト
.
Base = declarative_base()
class Genre(Base):
__tablename__ = 'genres'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(20), unique=True)
# Musician genres_musicians
musicians = relationship("Musician", secondary='genres_musicians')
class Musician(Base):
__tablename__ = 'musicians'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50), unique=True)
# Genre genres_musicians
genres = relationship("Genre", secondary='genres_musicians')
# Album albums_musicians
albums = relationship("Album", secondary='albums_musicians')
class GenreMusician(Base):
__tablename__ = 'genres_musicians'
# ,
__table_args__ = (PrimaryKeyConstraint('genre_id', 'musician_id'),)
#
genre_id = sa.Column(sa.Integer, sa.ForeignKey('genres.id'))
musician_id = sa.Column(sa.Integer, sa.ForeignKey('musicians.id'))
class Album(Base):
__tablename__ = 'albums'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50), unique=True)
year = sa.Column(sa.Integer)
# Musician albums_musicians
musicians = relationship("Musician", secondary='albums_musicians')
class AlbumMusician(Base):
__tablename__ = 'albums_musicians'
# ,
__table_args__ = (PrimaryKeyConstraint('album_id', 'musician_id'),)
#
album_id = sa.Column(sa.Integer, sa.ForeignKey('albums.id'))
musician_id = sa.Column(sa.Integer, sa.ForeignKey('musicians.id'))
class Track(Base):
__tablename__ = 'tracks'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(100))
length = sa.Column(sa.Integer)
# album_id ,
album_id = sa.Column(sa.Integer, ForeignKey('albums.id'))
# Collection collections_tracks
collections = relationship("Collection", secondary='collections_tracks')
class Collection(Base):
__tablename__ = 'collections'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50))
year = sa.Column(sa.Integer)
# Track collections_tracks
tracks = relationship("Track", secondary='collections_tracks')
class CollectionTrack(Base):
__tablename__ = 'collections_tracks'
# ,
__table_args__ = (PrimaryKeyConstraint('collection_id', 'track_id'),)
#
collection_id = sa.Column(sa.Integer, sa.ForeignKey('collections.id'))
track_id = sa.Column(sa.Integer, sa.ForeignKey('tracks.id'))
テーブルを記述する宣言スタイルの基本クラスBaseを作成し、そこから継承する必要があります。テーブルリレーションシップのすべての魔法は、リレーションシップとForeignKeyの正しい使用にあります。コードは、どの場合にどの関係を作成するかを示します。重要なことは、多対多の関係の両側で関係を登録することを忘れないことです。
ORMアプローチを使用してテーブルを直接作成するには、次のコマンドを呼び出します。
Base.metadata.create_all(engine_orm)
そして、これが魔法の出番です。文字通り、Baseからの継承によってコードで宣言されたすべてのクラスがテーブルになります。すぐに、どのクラスを今作成し、どのクラスを後で作成するために延期するか(たとえば、別のデータベース)のインスタンスを指定する方法がわかりませんでした。確かにそのような方法はありますが、私たちのコードでは、Baseから継承するすべてのクラスが一度にインスタンス化されます。これを覚えておいてください。
ORMアプローチを使用したテーブルの入力は、次のようになります。
ORMを介してテーブルにデータを入力する
print('\nPreparing data for ORM job...')
for item in DATA:
#
genre = session_orm.query(Genre).filter_by(name=item['genre']).scalar()
if not genre:
genre = Genre(name=item['genre'])
session_orm.add(genre)
#
musician = session_orm.query(Musician).filter_by(name=item['musician']).scalar()
if not musician:
musician = Musician(name=item['musician'])
musician.genres.append(genre)
session_orm.add(musician)
#
album = session_orm.query(Album).filter_by(name=item['album']).scalar()
if not album:
album = Album(name=item['album'], year=item['album_year'])
album.musicians.append(musician)
session_orm.add(album)
#
# ,
#
track = session_orm.query(Track).join(Album).filter(and_(Track.name == item['track'],
Album.name == item['album'])).scalar()
if not track:
track = Track(name=item['track'], length=item['length'])
track.album_id = album.id
session_orm.add(track)
# ,
if item['collection']:
collection = session_orm.query(Collection).filter_by(name=item['collection']).scalar()
if not collection:
collection = Collection(name=item['collection'], year=item['collection_year'])
collection.tracks.append(track)
session_orm.add(collection)
session_orm.commit()
各リファレンスブック(ジャンル、ミュージシャン、アルバム、コレクション)に作品ごとに記入する必要があります。SQLクエリの場合、バッチデータ追加を生成することが可能でした。ただし、中間テーブルを明示的に作成する必要はありません。SQLAlchemyの内部メカニズムがこれを担当します。
データベースクエリ
割り当て時に、SQLとORMの両方の手法を使用して15のクエリを作成する必要があります。難易度の高い順に提起された質問のリストは次のとおりです。
- 2018年にリリースされたアルバムのタイトルとリリース年。
- 最長のトラックのタイトルと長さ。
- トラックの名前。所要時間は3.5分以上です。
- 2018年から2020年までの期間に発行されたコレクションのタイトル。
- 名前が1語で構成されているパフォーマー。
- 「私」という言葉を含むトラックの名前。
- 各ジャンルのパフォーマーの数。
- 2019-2020アルバムに含まれるトラックの数。
- 各アルバムの平均トラック長。
- 2020年にアルバムをリリースしていないすべてのアーティスト。
- 特定のアーティストが参加しているコレクションのタイトル。
- 複数のジャンルのパフォーマーがいるアルバムの名前。
- コレクションに含まれていないトラックの名前。
- 最短のトラックを書いたアーティスト(理論的には、そのようなトラックがいくつか存在する可能性があります)。
- トラック数が最も少ないアルバムの名前。
ご覧のとおり、上記の質問は、単純な選択とテーブルの結合の両方、および集計関数の使用を意味します。
以下に、2つのオプション(SQLとORMを使用)での15のクエリのそれぞれに対するソリューションを示します。コードでは、要求はペアで送信され、コンソール出力で結果が同一であることを示しています。
リクエストとその簡単な説明
print('\n1. All albums from 2018:')
query = read_query('queries/select-album-by-year.sql').format(2018)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album).filter_by(year=2018):
print(item.name)
print('\n2. Longest track:')
query = read_query('queries/select-longest-track.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).order_by(Track.length.desc()).slice(0, 1):
print(f'{item.name}, {item.length}')
print('\n3. Tracks with length not less 3.5min:')
query = read_query('queries/select-tracks-over-length.sql').format(310)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).filter(310 <= Track.length).order_by(Track.length.desc()):
print(f'{item.name}, {item.length}')
print('\n4. Collections between 2018 and 2020 years (inclusive):')
query = read_query('queries/select-collections-by-year.sql').format(2018, 2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Collection).filter(2018 <= Collection.year,
Collection.year <= 2020):
print(item.name)
print('\n5. Musicians with name that contains not more 1 word:')
query = read_query('queries/select-musicians-by-name.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Musician).filter(Musician.name.notlike('%% %%')):
print(item.name)
print('\n6. Tracks that contains word "me" in name:')
query = read_query('queries/select-tracks-by-name.sql').format('me')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).filter(Track.name.like('%%me%%')):
print(item.name)
print('Ok, let\'s start serious work')
print('\n7. How many musicians plays in each genres:')
query = read_query('queries/count-musicians-by-genres.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Genre).join(Genre.musicians).order_by(func.count(Musician.id).desc()).group_by(
Genre.id):
print(f'{item.name}, {len(item.musicians)}')
print('\n8. How many tracks in all albums 2019-2020:')
query = read_query('queries/count-tracks-in-albums-by-year.sql').format(2019, 2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track, Album).join(Album).filter(2019 <= Album.year, Album.year <= 2020):
print(f'{item[0].name}, {item[1].year}')
print('\n9. Average track length in each album:')
query = read_query('queries/count-average-tracks-by-album.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album, func.avg(Track.length)).join(Track).order_by(func.avg(Track.length)).group_by(
Album.id):
print(f'{item[0].name}, {item[1]}')
print('\n10. All musicians that have no albums in 2020:')
query = read_query('queries/select-musicians-by-album-year.sql').format(2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery = session_orm.query(distinct(Musician.name)).join(Musician.albums).filter(Album.year == 2020)
for item in session_orm.query(distinct(Musician.name)).filter(~Musician.name.in_(subquery)).order_by(
Musician.name.asc()):
print(f'{item}')
print('\n11. All collections with musician Steve:')
query = read_query('queries/select-collection-by-musician.sql').format('Steve')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Collection).join(Collection.tracks).join(Album).join(Album.musicians).filter(
Musician.name == 'Steve').order_by(Collection.name):
print(f'{item.name}')
print('\n12. Albums with musicians that play in more than 1 genre:')
query = read_query('queries/select-albums-by-genres.sql').format(1)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album).join(Album.musicians).join(Musician.genres).having(func.count(distinct(
Genre.name)) > 1).group_by(Album.id).order_by(Album.name):
print(f'{item.name}')
print('\n13. Tracks that not included in any collections:')
query = read_query('queries/select-absence-tracks-in-collections.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
# Important! Despite the warning, following expression does not work: "Collection.id is None"
for item in session_orm.query(Track).outerjoin(Track.collections).filter(Collection.id == None):
print(f'{item.name}')
print('\n14. Musicians with shortest track length:')
query = read_query('queries/select-musicians-min-track-length.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery = session_orm.query(func.min(Track.length))
for item in session_orm.query(Musician, Track.length).join(Musician.albums).join(Track).group_by(
Musician.id, Track.length).having(Track.length == subquery).order_by(Musician.name):
print(f'{item[0].name}, {item[1]}')
print('\n15. Albums with minimum number of tracks:')
query = read_query('queries/select-albums-with-minimum-tracks.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery1 = session_orm.query(func.count(Track.id)).group_by(Track.album_id).order_by(func.count(Track.id)).limit(1)
subquery2 = session_orm.query(Track.album_id).group_by(Track.album_id).having(func.count(Track.id) == subquery1)
for item in session_orm.query(Album).join(Track).filter(Track.album_id.in_(subquery2)).order_by(Album.name):
print(f'{item.name}')
コードを読みたくない人のために、「生の」SQLがどのように見えるかとORM式でのその代替を示してみましょう。
SQLクエリとORM式を照合するためのチートシート
1。2018年のアルバムのタイトルとリリース年:
SQL
select name
from albums
where year=2018
ORM
session_orm.query(Album).filter_by(year=2018)
2.最長トラックのタイトルと期間:
SQL
select name, length
from tracks
order by length DESC
limit 1
ORM
session_orm.query(Track).order_by(Track.length.desc()).slice(0, 1)
3.持続時間が3.5分以上のトラックの名前:
SQL
select name, length
from tracks
where length >= 310
order by length DESC
ORM
session_orm.query(Track).filter(310 <= Track.length).order_by(Track.length.desc())
4. 2018年から2020年までの期間に公開されたコレクションの名前:
SQL
select name
from collections
where (year >= 2018) and (year <= 2020)
ORM
session_orm.query(Collection).filter(2018 <= Collection.year, Collection.year <= 2020)
*以降、フィルタリングはfilter_byを使用せず、filterを使用して指定されることに注意してください。
5.名前が1ワードで構成される実行者:
SQL
select name
from musicians
where not name like '%% %%'
ORM
session_orm.query(Musician).filter(Musician.name.notlike('%% %%'))
6.「私」という単語を含むトラックの名前:
SQL
select name
from tracks
where name like '%%me%%'
ORM
session_orm.query(Track).filter(Track.name.like('%%me%%'))
7.各ジャンルの出演者数:
SQL
select g.name, count(m.name)
from genres as g
left join genres_musicians as gm on g.id = gm.genre_id
left join musicians as m on gm.musician_id = m.id
group by g.name
order by count(m.id) DESC
ORM
session_orm.query(Genre).join(Genre.musicians).order_by(func.count(Musician.id).desc()).group_by(Genre.id)
8. 2019-2020アルバムに含まれるトラック数:
SQL
select t.name, a.year
from albums as a
left join tracks as t on t.album_id = a.id
where (a.year >= 2019) and (a.year <= 2020)
ORM
session_orm.query(Track, Album).join(Album).filter(2019 <= Album.year, Album.year <= 2020)
9.各アルバムの平均トラック長:
SQL
select a.name, AVG(t.length)
from albums as a
left join tracks as t on t.album_id = a.id
group by a.name
order by AVG(t.length)
ORM
session_orm.query(Album, func.avg(Track.length)).join(Track).order_by(func.avg(Track.length)).group_by(Album.id)
10. 2020年にアルバムをリリースしていないすべてのアーティスト:
SQL
select distinct m.name
from musicians as m
where m.name not in (
select distinct m.name
from musicians as m
left join albums_musicians as am on m.id = am.musician_id
left join albums as a on a.id = am.album_id
where a.year = 2020
)
order by m.name
ORM
subquery = session_orm.query(distinct(Musician.name)).join(Musician.albums).filter(Album.year == 2020)
session_orm.query(distinct(Musician.name)).filter(~Musician.name.in_(subquery)).order_by(Musician.name.asc())
11.特定のアーティスト(スティーブ)が存在するコンピレーションの名前:
SQL
select distinct c.name
from collections as c
left join collections_tracks as ct on c.id = ct.collection_id
left join tracks as t on t.id = ct.track_id
left join albums as a on a.id = t.album_id
left join albums_musicians as am on am.album_id = a.id
left join musicians as m on m.id = am.musician_id
where m.name like '%%Steve%%'
order by c.name
ORM
session_orm.query(Collection).join(Collection.tracks).join(Album).join(Album.musicians).filter(Musician.name == 'Steve').order_by(Collection.name)
12.複数のジャンルのアーティストが参加しているアルバムの名前:
SQL
select a.name
from albums as a
left join albums_musicians as am on a.id = am.album_id
left join musicians as m on m.id = am.musician_id
left join genres_musicians as gm on m.id = gm.musician_id
left join genres as g on g.id = gm.genre_id
group by a.name
having count(distinct g.name) > 1
order by a.name
ORM
session_orm.query(Album).join(Album.musicians).join(Musician.genres).having(func.count(distinct(Genre.name)) > 1).group_by(Album.id).order_by(Album.name)
13.コレクションに含まれていないトラックの名前:
SQL
select t.name
from tracks as t
left join collections_tracks as ct on t.id = ct.track_id
where ct.track_id is null
ORM
session_orm.query(Track).outerjoin(Track.collections).filter(Collection.id == None)
* PyCharmでの警告にもかかわらず、この方法でフィルタリング条件を作成する必要があることに注意してください。IDEの提案に従って作成すると(「Collection.idはNone」)、機能しません。
14.最短のトラックを書いたアーティスト(理論的には、そのようなトラックがいくつか存在する可能性があります):
SQL
select m.name, t.length
from tracks as t
left join albums as a on a.id = t.album_id
left join albums_musicians as am on am.album_id = a.id
left join musicians as m on m.id = am.musician_id
group by m.name, t.length
having t.length = (select min(length) from tracks)
order by m.name
ORM
subquery = session_orm.query(func.min(Track.length)) session_orm.query(Musician, Track.length).join(Musician.albums).join(Track).group_by(Musician.id, Track.length).having(Track.length == subquery).order_by(Musician.name)
15.トラック数が最も少ないアルバムの名前:
SQL
select distinct a.name
from albums as a
left join tracks as t on t.album_id = a.id
where t.album_id in (
select album_id
from tracks
group by album_id
having count(id) = (
select count(id)
from tracks
group by album_id
order by count
limit 1
)
)
order by a.name
ORM
subquery1 = session_orm.query(func.count(Track.id)).group_by(Track.album_id).order_by(func.count(Track.id)).limit(1)
subquery2 = session_orm.query(Track.album_id).group_by(Track.album_id).having(func.count(Track.id) == subquery1)
session_orm.query(Album).join(Track).filter(Track.album_id.in_(subquery2)).order_by(Album.name)
ご覧のとおり、上記の質問は、単純な選択とテーブルの結合の両方、および集計関数とサブクエリの使用を意味します。これはすべて、SQLモードとORMモードの両方でSQLAlchemyを使用して実行できます。さまざまな演算子とメソッドを使用すると、複雑なクエリを実行できます。
この資料が、初心者がすばやく効率的にクエリを書き始めるのに役立つことを願っています。