- 研究論文
- Pytorch:YOLOv4-CSP、YOLOv4-P5、YOLOv4-P6、YOLOv4-P7(メインリポジトリ-結果の再現に使用)
YOLOv4-
CSPYOLOv4-小さい
YOLOv4-大きい
- ダークネット:YOLOv4-tiny、YOLOv4-CSP、YOLOv4x-MISH
- YOLOv4-CSP構造
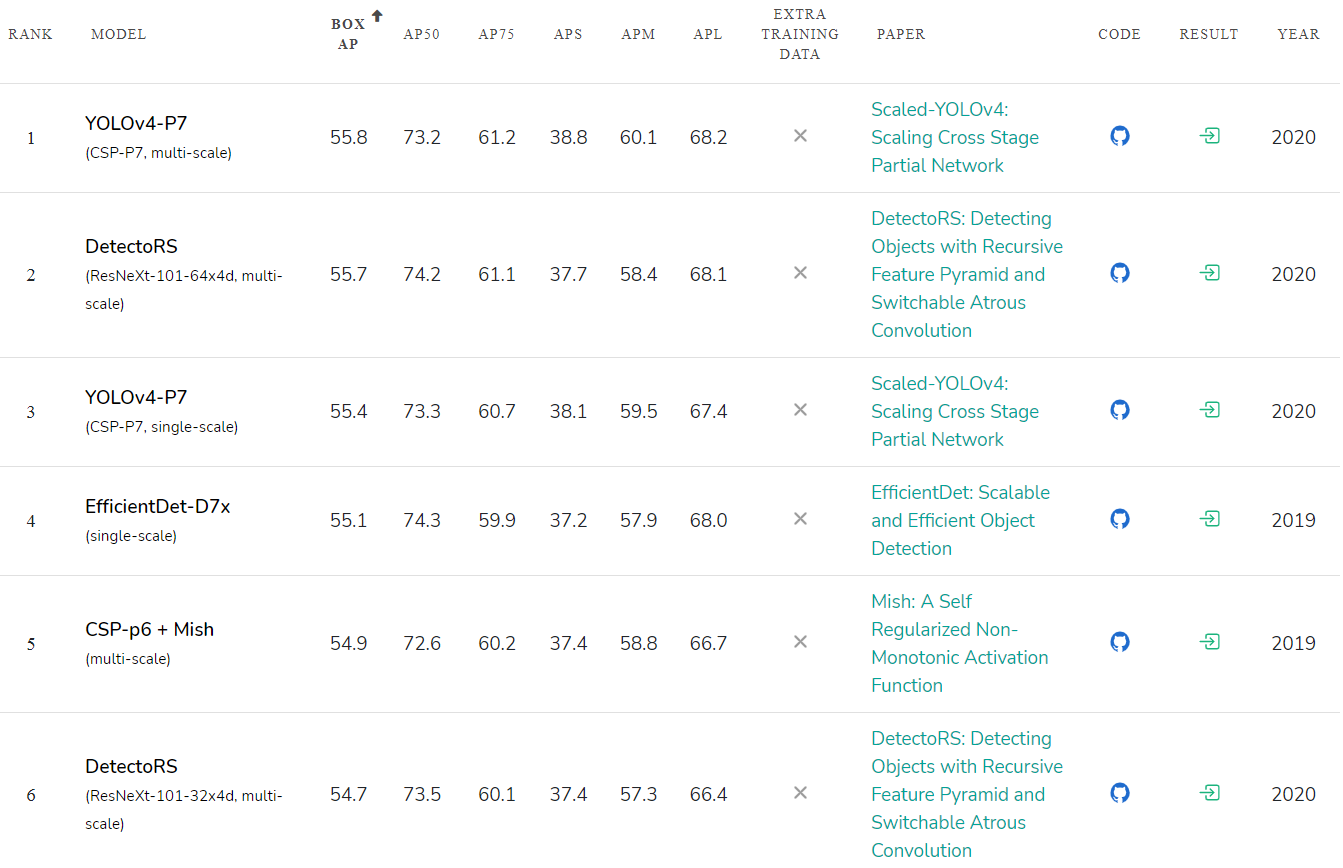
スケーリングされたYOLOv4は、これまでに公開されたニューラルネットワークのMicrosoft COCOデータセットで最も正確なニューラルネットワーク( 55.8%AP)です。また、15FPSから1774FPSまでの精度と速度の全範囲で、速度と精度の比率の点でも最高 です。現時点では、オブジェクト検出用のトップ1ニューラルネットワークです。
スケーリングされたYOLOv4は、ニューラルネットワークよりも正確に優れています。
- Google EfficientDet D7x / DetectoRSまたはSpineNet-190(追加データで自己トレーニング)
- アマゾンカスケード-RCNNResNest200
- Microsoft RepPoints v2
- Facebook RetinaNet SpineNet-190
YOLOおよびCross-Stage-Partial(CSP)ネットワークのアプローチが、絶対精度と精度と速度の比率の両方の点で最適であることを示します。
TensorRTを使用しないバッチ= 1のGPUTesla V100(Volta)での精度(垂直軸)とレイテンシー(水平軸)のグラフ:
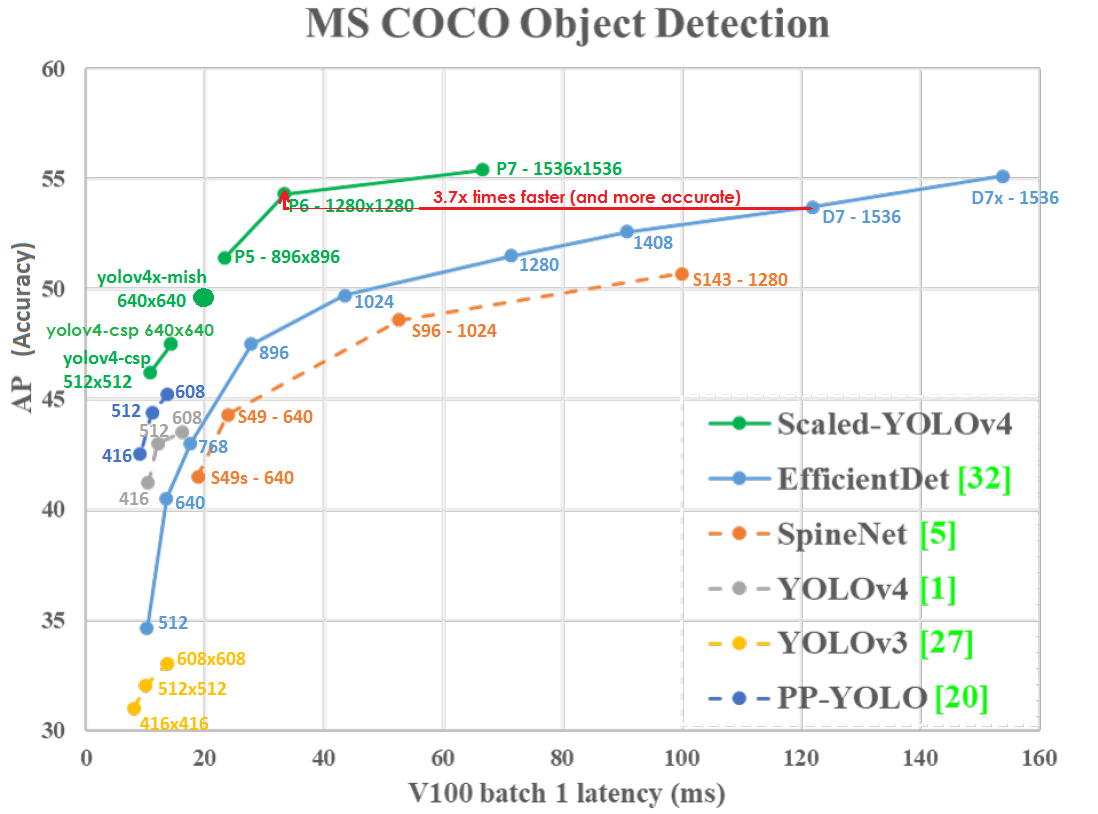
ネットワーク解像度が低くても、Scaled-YOLOv4-P6(1280x1280)30 FPSは、EfficientDetD7(1536x1536)8.2 FPSよりもわずかに正確で、3.7倍高速です。それら。YOLOv4は、ネットワーク解像度をより有効に活用します。
スケーリングされたYOLOv4は、パレート最適性曲線 上にあります。他にどのようなニューラルネットワークを使用する場合でも、同じ速度でより正確であるか、同じ精度でより高速であるようなYOLOv4ネットワークが常に存在します。YOLOv4は速度と精度の点で最高です。
スケーリングされたYOLOv4は、ニューラルネットワークよりも正確で高速です。
- Google EfficientDet D0-D7x
- Google SpineNetS49s-S143
- Baiduパドル-パドルPPYOLO
- そして他の多く
スケーリングされたYOLOv4は、改良されスケーリングされたYOLOv4ネットワークから構築された一連のニューラルネットワークです。私たちのニューラルネットワークは、事前にトレーニングされたウェイト(Imagenetまたはその他)を使用せずにゼロからトレーニングされました。
公開されたニューラルネットワークの精度評価: paperswithcode.com/sota/object-detection-on-coco:
YOLOv4-TensorRT + tkDNN(バッチ= 4、FP16)を使用すると、ゲーム用GPU RTX2080Tiで小さなニューラルネットワークの速度が1774FPSに達します: github。 com / ceccocats / tkDNN
YOLOv4-tinyは、JetsonNano(416x416、fp16、バッチ= 1)tkDNN / TensorRTで39FPS / 25msのレイテンシでリアルタイムで実行できます。

スケーリングされたYOLOv4は、GPUやNPUなどの並列コンピューターのリソースをはるかに効率的に使用します。たとえば、GPU V100(Volta)のパフォーマンスは次のとおりです。14TFLops-112TFLops-TC images.nvidia.com/content/technologies/volta/pdf/tesla-volta-v100-datasheet-letter-fnl-web.pdf
テストする場合バッチ= 1、パラメータ--hparams = mixed_precision = true、-tensorrt = FP32なしの 、 GPU V100の両方のモデル 。
- YOLOv4-CSP(640x640)-47.5%AP-70 FPS-120 BFlops(60 FMA)
BFlopsに基づくと、933 FPS =(112,000 / 120)になりますが、実際には70 FPS、つまり 7.5% GPUを使用=(70/933) - EfficientDetD3 (896x896) – 47.5% AP – 36 FPS – 50 BFlops (25 FMA)
BFlops, 2240 FPS = (112 000 / 50), 36 FPS, .. 1.6% GPU = (36 / 2240)
それら。YOLOv4-CSP(7.5 / 1.6)で使用されるGPUなどの大規模な並列コンピューティングを備えたデバイスでのコンピューティング操作の効率= EfficientDetD3で使用される操作の効率より4.7倍 優れています。
通常、ニューラルネットワークはデバッグを容易にするための研究タスクでのみCPU上で実行され、BFlops特性は現在学術的な関心のみです。実際のタスクでは、紙のパフォーマンスではなく、実際の速度と精度が重要です。YOLOv4-P6の実際の速度は、GPUV100のEfficientDetD7より3.7倍高速です。したがって、大規模な並列処理GPU / NPU / TPU / DSPを備え、速度、価格、および熱放散がはるかに最適なデバイスがほとんどの場合使用されます。
- 組み込みGPU(Jetson Nano / Nx)
- モバイル-GPU / NPU / DSP(Bionic-NPU / Snapdragon-DSP / Mediatek-APU / Kirin-NPU / Exynos-GPU / ...)
- TPU-Edge(Google Coral / Intel Myriad / Mobileye EyeQ5 / Tesla-motors TPU 144 TOPS-8ビット)
- クラウドGPU(nVidia A100 / V100 / TitanV)
- クラウドNPU(Google-TPU、Huawei Ascend、Intel Habana、Qualcomm AI 100、...)
また、Web上でニューラルネットワークを使用する場合(通常、GPUはWebGL、WebAssembly、WebGPUライブラリを介して使用されます。この場合)、モデルのサイズが重要になる可能性があります。github.com / tensorflow / tfjs#about-this-repo
弱いデバイスとアルゴリズムの使用並列処理は開発の行き止まりの道です。プロセッサの周波数を上げるために、リトグラフのサイズをシリコン原子のサイズよりも小さくすることは不可能です。
- 半導体デバイスの製造に現在最適なサイズは5ナノメートルです。
- シリコンの結晶格子サイズは0.5ナノメートルです。
- シリコンの原子半径は0.1ナノメートルです。
解決策は、大規模な並列処理を備えたコンピューターです。単一のクリスタル上、またはインターポーザーによって接続された複数のクリスタル上にあります。したがって、GPUやNPUなどの大規模並列コンピューティングマシンを効果的に使用するニューラルネットワークを作成することは非常に重要です。
YOLOv4に対するスケーリングされたYOLOv4の改善:
- スケーリングされたYOLOv4は、最適なネットワークスケーリング手法を使用して、YOLOv4-CSP-> P5-> P6-> P7ネットワークを取得しました。
- 改善されたネットワークアーキテクチャ:バックボーンが最適化され、ネック(PAN)はクロスステージパーシャル(CSP)接続とミッシュアクティベーションを使用します
- 指数移動平均(EMA)はトレーニング中に使用されます-これはSWAの特殊なケースです:pytorch.org/blog/pytorch-1.6-now-includes-stochastic-weight-averaging
- ネットワークの解像度ごとに、個別のニューラルネットワークがトレーニングされます(YOLOv4では、すべての解像度に対して1つのニューラルネットワークのみがトレーニングされました)
- [yolo]レイヤーのノーマライザーの改善
- 幅と高さのアクティベーションが変更され、ネットワークトレーニングが高速化されました
- 高解像度ネットワーク(yolov4-tiny.cfgを除くすべて)には、[net] letter_box = 1パラメーター(入力画像のアスペクト比を保持)を使用します。
スケーリングされたYOLOv4ニューラルネットワークアーキテクチャ(3つのネットワークの例:P5、P6、P7):

CSP接続は非常に効率的でシンプルであり、任意のニューラルネットワークに適用できます。肝心なのは
- 出力信号の半分はメインパスに沿って進みます(大きな受容フィールドでより多くのセマンティック情報を生成します)
- 信号の残りの半分は迂回します(小さな受容フィールドでより多くの空間情報を保持します)
CSP接続の最も単純な例(左側は通常のネットワーク、右側はCSPネットワーク):

YOLOv4-CSP / P5 / P6 / P7のCSP接続の例
(左側は通常のネットワーク、右側はCSPネットワーク):

YOLOv4-tinyには2つのCSP接続があります。 :

YOLOv4は、さまざまな分野やタスクで使用されています。
- 台湾政府:交通管制www.taiwannews.com.tw/en/news/3957400およびyoutu.be/IiU6wFmfVnk
- アマゾン:Anti-Covid19ディスタンスアシスタントgithub.com/amzn/distance-assistantおよびAmazon Neurochip / Amazon EC2 Inf1インスタンス:aws.amazon.com/ru/blogs/machine-learning/improving-performance-for-deep-learning- Based-object-detection-with-an-aws-neuron-compiled-yolov4-model-on-aws-inferentia
- BMWイノベーションラボ:github.com/BMW-InnovationLab
そして他の多くのタスクで…。
さまざまなフレームワークに実装があります。
- Pytorch:github.com/WongKinYiu/ScaledYOLOv4
- ダークネット:github.com/AlexeyAB/darknet
- TensorFlow:github.com/hunglc007/tensorflow-yolov4-tflite
- o pip install yolov4 pypi.org/project/yolov4
- OpenCV: docs.opencv.org/master/da/d9d/tutorial_dnn_yolo.html
- OpenVINO: github.com/TNTWEN/OpenVINO-YOLOV4
- ONNX: developer.nvidia.com/blog/announcing-onnx-runtime-for-jetson
- TensorRT ONNX Scaled-YOLOv4: github.com/linghu8812/tensorrt_inference/tree/master/ScaledYOLOv4
- TensorRT + tkDNN: github.com/ceccocats/tkDNN
- TensorRT + Deepstream: github.com/NVIDIA-AI-IOT/yolov4_deepstream
- Another Pytorch implementations:
- o github.com/WongKinYiu/PyTorch_YOLOv4
- o github.com/Tianxiaomo/pytorch-YOLOv4
- o github.com/VCasecnikovs/Yet-Another-YOLOv4-Pytorch
- ネットワークの構造は、Netronユーティリティを使用して表示できます-ニューラルネットワークのビジュアライザー:github.com/lutzroeder/netron
Cloud Object Detectionを無料でコンパイルして実行する方法 :
- colab:colab.research.google.com/drive/12QusaaRj_lUwCGDvQNfICpa7kA7_a2dE
- ビデオ:www.youtube.com/watch?v = mKAEGSxwOAY
Training in the Cloudを無料でコンパイルして実行する方法 :
- colab:colab.research.google.com/drive/1_GdoqCJWXsChrOiY8sZMr_zbr_fH-0Fg?usp = sharing
- ビデオ:youtu.be/mmj3nxGT2YQ
また、YOLOv4アプローチは、他のタスクで使用できます。たとえば、3Dオブジェクトを検出する場合です。
- コード-Complex-YOLOv4(5-DOF):github.com/maudzung/Complex-YOLOv4-Pytorch
- コード-YOLO3D-YOLOv4(7-DOF):github.com/maudzung/YOLO3D-YOLOv4-PyTorch
