CREATE TABLE task AS
SELECT
id
, (random() * 100)::integer person -- 100
, least(trunc(-ln(random()) / ln(2)), 10)::integer priority -- 2
FROM
generate_series(1, 1e5) id; -- 100K
CREATE INDEX ON task(person, priority);
SQLの「is」という単語は次のようになります
EXISTS
-これが最も単純なバージョンで、始めましょう:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);

すべてのプランの写真はクリック可能です
これまでのところ、すべてが良さそうですが...
EXISTS + IN
...それから彼らは私たちのところに来て、「スーパー」として
priority = 10
8と9だけでなく含めるように頼みました :
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority IN (10, 9, 8)
);

彼らは1.5倍多く読み、それは実行時間にも影響を及ぼしました。
または+存在する
priority = 8
10を超えるレコードに遭遇する可能性がはるかに高いという私たちの知識を使用してみましょう 。
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
) OR
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
) OR
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);

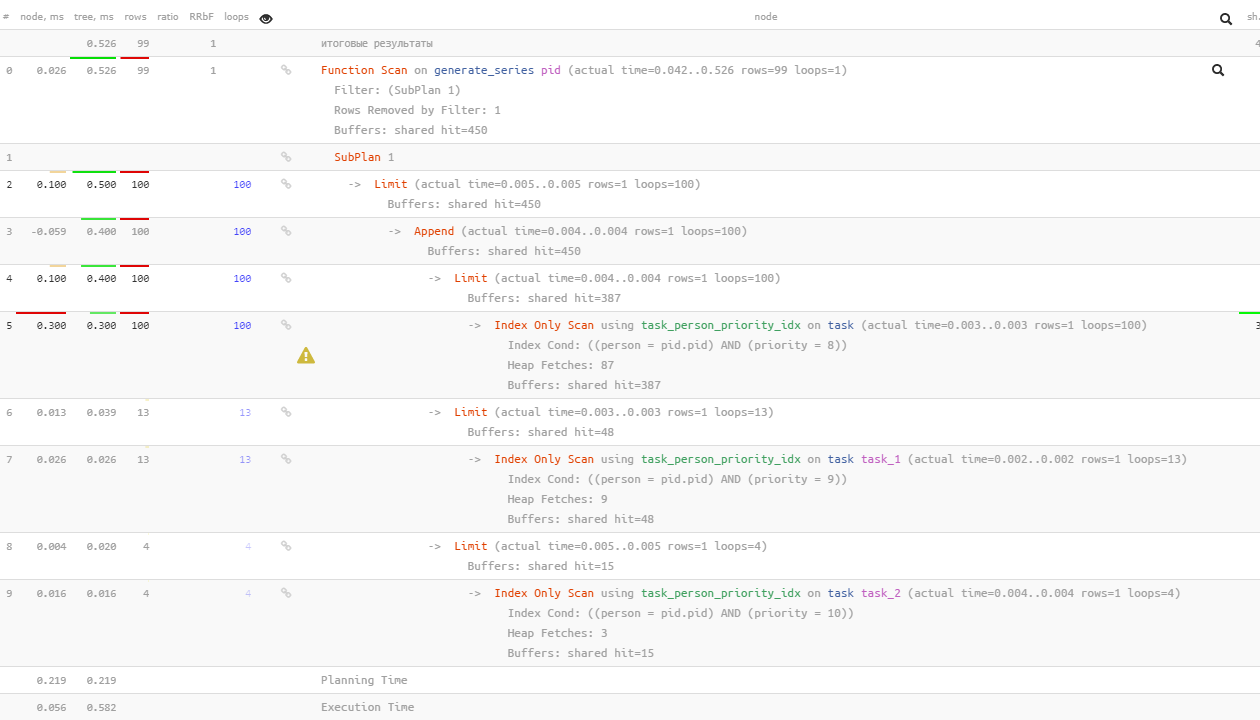
そのノート のPostgreSQL 12が既にスマート後続するのに十分な
EXISTS
だけ前のものによって、「見つかりません」のためのもの-subqueriesを値8 100を検索した後、 値9に対してのみ13、及びわずか4 10用- 。
ケース+存在+..。
以前のバージョンでは、次のクエリを「CASEの下に隠す」ことで同様の結果を得ることができます。
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
CASE
WHEN
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
) THEN TRUE
ELSE
CASE
WHEN
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
) THEN TRUE
ELSE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
)
END
END;
EXISTS + UNION ALL + LIMIT
同じですが、「ハック」を使用すると少し速くなる可能性があります
UNION ALL + LIMIT
。
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
LIMIT 1
)
UNION ALL
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
LIMIT 1
)
UNION ALL
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
LIMIT 1
)
LIMIT 1
);
正しいインデックスはデータベースの健全性の鍵です
それでは、まったく別の側面から問題を見てみましょう。私たちがいることを確かに知っている場合
task
、我々が発見したいとレコードの数がある 数倍以下残りの部分よりも、我々は、適切な部分インデックスを作成します。同時に、「ドット」列挙
8, 9, 10
から
>= 8
:に直接進みましょう 。
CREATE INDEX ON task(person) WHERE priority >= 8;
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority >= 8
);

私は2倍速くそして1.5倍少なく読まなければなりませんでした!
しかし、おそらく、すべての適切なものを
task
一度に差し引く と、さらに速くなりますか?..
SELECT DISTINCT
person
FROM
task
WHERE
priority >= 8;

常にではなく、この場合は確かにそうではありません。最初に使用可能なレコードを100回読み取る代わりに、400回以上読み取る必要があるためです。
そして、どのクエリオプションがより効果的であるかを推測せず、自信を持って知るために、explain.tensor.ruを使用して ください。