
したがって、有向加重グラフを検討してください。グラフにn個の頂点があるとします。頂点の各ペアは、ある程度の重み(遷移確率)に対応します。

典型的なウェブグラフは、分解不可能条件と非周期性条件が満たされる均質な離散マルコフチェーンであることに注意する必要があります。
Kolmogorov-Chapmanの式を書いてみましょう。
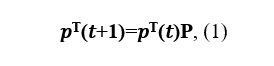
ここで、Pは遷移行列です。
限界があると仮定します。
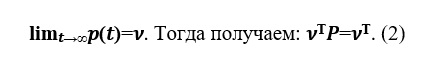
ベクトル vは定常確率分布と呼ばれます。
ブリンページモデルでウェブページのランキングベクトルを検索することが提案されたのは、関係(2)からでした。
以来、 vが限界であり、

定常分布が単純な反復(MPI)の方法により算出することができます。
あるWebページから別のWebページに移動するには、ユーザーは一定の確率で、移動するリンクを選択する必要があります。ドキュメントに複数の送信リンクがある場合、ユーザーが同じ確率でそれぞれをクリックしたと想定します。そして最後に、テレポーテーション係数もあります。これは、ユーザーが現在のドキュメントから別のページに移動できる可能性があることを示していますが、必ずしも現在のページに直接関連しているとは限りません。ユーザーが確率δでテレポートすると、式(1)は次の形式になります

。0<δ<1の場合、式は一意の解を持つことが保証されます。実際には、通常、PageRankの計算にはδ= 0.15の式が使用されます。
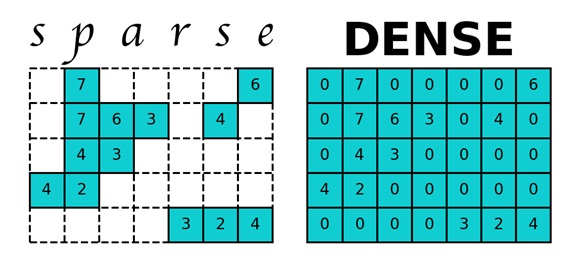
サイトからのGoogleWebグラフを考えてみましょう-リンク。このWebグラフには875713の頂点が含まれています。つまり、2次元マトリックスPの場合、714Gbのメモリを割り当てる必要があります。最近のコンピューターのRAMは1桁少ないため、コンピューターはハードディスクメモリの使用を開始し、アクセスするとPageRank計算プログラムの作業が大幅に遅くなります。しかし、行列Pはまばらな行列、つまり主に要素がゼロの行列です。 Pythonでスパース行列を操作するには、scipyライブラリのスパースモジュールを使用します。これにより、行列Pが占めるメモリが大幅に少なくなります。
このアルゴリズムをこのデータに適用してみましょう。ノードはWebページを表し、有向エッジはそれらの間のハイパーリンクです。
まず、必要なライブラリをインポートしましょう。
import cvxpy as cp
import numpy as np
import pandas as pd
import time
import numpy.linalg as ln
from scipy.sparse import csr_matrix
それでは、実装自体に移りましょう。
#
data = pd.read_csv("web-Google.txt", names = ['i','j'], sep="\t", header=None)
NODES = 916428
EDGES = 5105039
#
NEW = csr_matrix((np.ones(len(data['i'])),(data['i'],data['j'])),shape=(NODES,NODES))
b = NEW.sum(axis=1)
NEW = NEW.transpose()
#
p0 = np.ones((NODES,1))/NODES
eps = 10**-5
delta = 0.15
ERROR = True
k = 0
#
while (ERROR == True):
with np.errstate(divide='ignore'):
z = p0 / b
p1 = (1-delta) * NEW.dot(csr_matrix(z)) + delta * np.ones((NODES,1))/NODES
if (ln.norm(p1-p0) < eps):
ERROR = False
k = k + 1
# PageRank
p0 = p1
我々はベクトルpが定常状態になるかを確認することができ、グラフの上に 、V:

PageRankのベクトルを使用して、我々はまた、選挙で勝者を決定することができます。Wikipediaの寄稿者のごく一部は管理者であり、管理者はメンテナンスを支援するための追加の技術機能にアクセスできるユーザーです。ユーザーが管理者になるために、管理者リクエストが発行され、Wikipediaコミュニティは、パブリックコメントまたは投票を通じて、誰を管理者の位置に昇格させるかを決定します。
PageRank問題は、最小化問題に還元し、Frank – Wolfe条件付き勾配法を使用して解決することもできます。これは次のとおりです。シンプレックスの頂点の1つを選択し、この頂点に開始点を作成します。データに対するこのメソッドの実装-リンクを以下に示します。
#
data = pd.read_csv("grad.txt", names = ['i','j'], sep="\t", header=None)
NODES = 6301
EDGES = 20777
#
NEW = csr_matrix((np.ones(len(data['i'])),(data['i'],data['j'])),shape=(NODES,NODES))
b = NEW.sum(axis=1)
NEW = NEW.transpose()
e = np.ones(NODES)
with np.errstate(divide='ignore'):
z = e / b
NEW = NEW.dot(csr_matrix(z))
#
eps = 0.05
k=0
a_0 = 1
y = np.zeros((NODES,1))
p0 = np.ones((NODES,1))/NODES
#
p0[0] = 0.1
y[np.argmin(df(p0))] = 1
p1 = (1-2/(1+k))*p0 + 2/(1+k)*y
#
while ((ln.norm(p1-p0) > eps)):
y = np.zeros((NODES,1))
k = k + 1
p0 = p1
y[np.argmin(df(p0))] = 1
p1 = (1-2/(1+k))*p0 + 2/(1+k)*y

実際の検索エンジンを効果的に運用するには、PageRankベクトルの計算速度が計算の精度よりも重要です。 MPIでは、計算速度のために精度を犠牲にすることはできません。モンテカルロアルゴリズムは、この問題にある程度対処するのに役立ちます。サイトのページをさまよっている仮想ユーザーを起動します。サイトのページへの訪問の統計を収集することにより、かなり長い期間の後、ユーザーがページにアクセスした回数を各ページで取得します。このベクトルを正規化することにより、目的のPageRankベクトルを取得します。このアルゴリズムがすでに使用されているデータでどのように機能するかを示しましょう 。
#
def get_edges(m, i):
if (i == NODES):
return random.randint(0, NODES)
else:
if (len(m.indices[m.indptr[i] : m.indptr[i+1]]) != 0):
return np.random.choice(m.indices[m.indptr[i] : m.indptr[i+1]])
else:
return NODES
#
data = pd.read_csv("web-Google.txt", names = ['i','j'], sep="\t", header=None)
NODES = 916428
EDGES = 5105039
NEW = csr_matrix((np.ones(len(data['i'])),(data['i'],data['j'])),shape=(NODES,NODES))
#c , total –
for total in range(1000000,2000000,100000):
#
k = random.randint(0, NODES)
# PageRank
ans = np.zeros(NODES+1)
margin2 = np.zeros(NODES)
ans_prev = np.zeros(NODES)
for t in range(total):
j = get_edges(NEW, k)
ans[j] = ans[j]+1
k = j
#
ans = np.delete(ans, len(ans)-1)
ans = ans/sum(ans)
for number in range(len(ans)):
margin2[number] = ans[number] - ans_prev[number]
ans_prev = ans
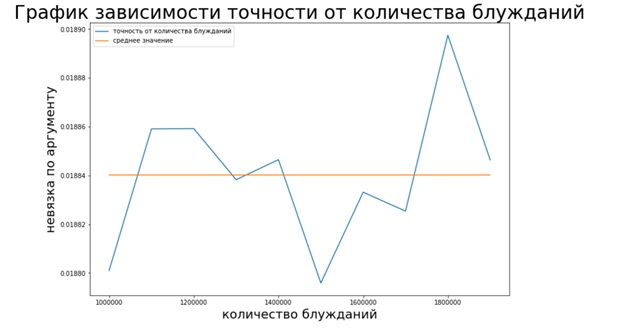
グラフからわかるように、モンテカルロ法は、前の2つの方法とは異なり、安定していません(収束がありません)が、多くの時間を必要とせずにページランクベクトルを推定するのに役立ちます。
結論:したがって、WebグラフのPageRankを決定するための主なアルゴリズムを検討しました。Webサイトの設計を開始する前に、次の点に注意してPageRankが無駄になっていないことを確認する必要があります。
- 内部リンクは、サイトに「リンクパワー」がどのように蓄積されているかを示します。サイトの「ホーム」ページには最も強力なPageRankがあるため、サイトのホームページの重要な情報に注目してください。
- サイトの他のページからリンクされていない孤立したページ。そのようなページは避けてください。
- 外部リンクがサイト訪問者にとって役立つ場合は、言及する価値があります。
- 壊れたインバウンドリンクはページ全体の重みを薄めるため、定期的に監視し、必要に応じて「修正」する必要があります。
ただし、これは、PageRankに夢中になっている必要があるという意味ではありません。ただし、サイトを構築するときにサイトの構造、内部リンクと外部リンクの機能に注意を払うことで、PageRank用にサイトを最適化することを覚えておく価値があります。