
AWSフォールトインジェクションシミュレータ(FIS)-AWSサービス内の内部システム障害の既知のシナリオを実装できるようにするツール。何のために? -チームが排除のシナリオを作成し、一般に、提案された条件下での製品の動作を評価できるようにします。システムは、サーバーの速度低下、サーバーの障害、データベースへのアクセスエラー、クラッシュなど、障害シナリオを含むいくつかのテンプレートをすぐに提供します。同時に、FISは実験が行き過ぎないことを保証し、特定のパラメーターに達すると、テストが停止され、システムは通常に戻ります。クラウドジャイアントの新製品の主なスローガンは、「制御されたカオステクノロジーを使用して復元力とパフォーマンスを向上させる」ことです。新しいテストシステムのリリースは2021年に予定されています。
AWSは、単一のホストへの依存度が低いテストおよび分散仮想化システムも提供します。分散システムでの障害の特異性は、問題が周期的であり、より複雑な構造を持つ可能性があることです。 AWSの新機能を使用すると、モノリスのインフラストラクチャだけでなく、分散システムやアプリケーションの脆弱性を検索できます。
これが重要でクールな理由を見てみましょう。
カオスエンジニアリングは、システムへの主な影響が内部から発生し、プロジェクトインフラストラクチャに影響を与えるシミュレーションテストプロセスです。チームは、プロジェクトのインフラストラクチャ部分が技術的な問題やその他の問題に直面している状況をシミュレートします。たとえば、インスタンスのパフォーマンスがポイントまたはシステム的に低下します。これには、サーバーのクラッシュ、APIの障害、およびチームがいつでも、さらに悪いことに、次のバージョンがリリースされた日に直面する可能性のあるバックエンドの他の悪夢も含まれる可能性があります。
カオスエンジニアリングの明確な定義はまだありません。そのため、ここに最も人気のある、そして私たちの意見では正確なオプションのいくつかを示します。カオスエンジニアリングとは、「運用中に発生するさまざまな外乱に耐えられることを確認するために、生産システムを実験するアプローチ」と「故障の影響を軽減する実験」です。
AWSフォールトインジェクションシミュレータが必要な理由
ツールの開発者は、システムをテストおよび準備するときにFISがチームに役立つ理由をいくつか挙げています。
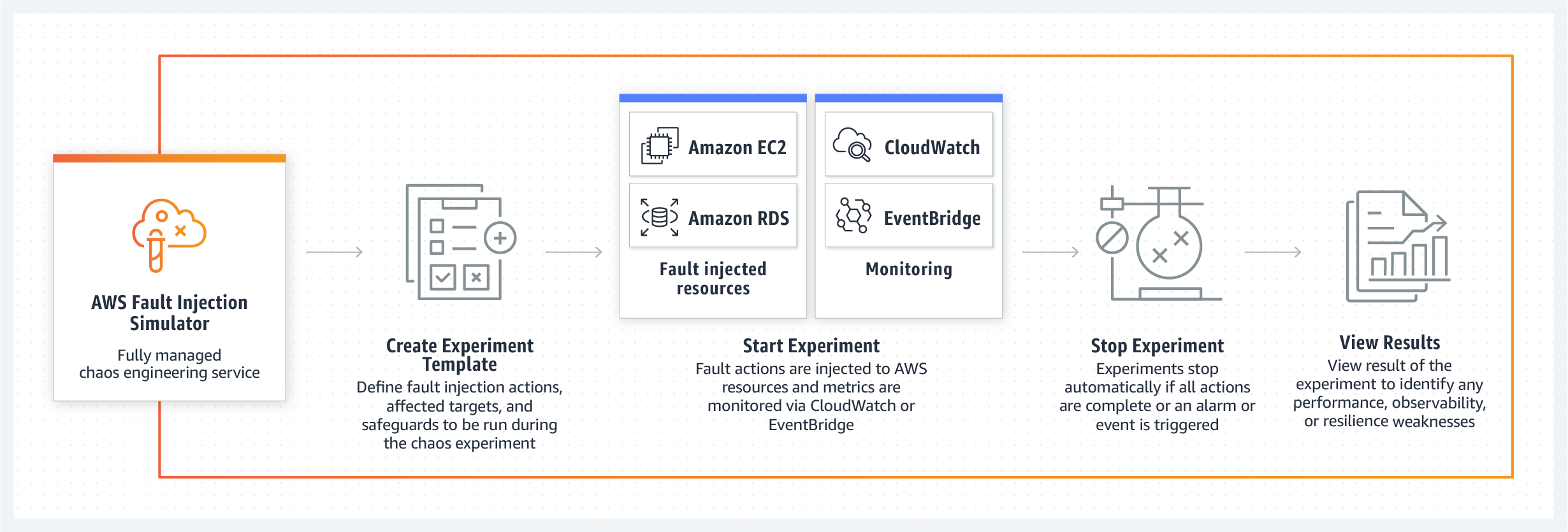
システムのパフォーマンス、回復力、透明性は、AWSFISチームのコアメッセージの1つです。
AWS Fault Injection Simulator , , «» , .
実際、通常のテスト方法は、まず第一に、システムの外部負荷のシミュレーションです。たとえば、システムまたはサービスに対するhabra効果または外部DDoS攻撃をシミュレートします。ほとんどの場合、すべての主要な監視システムはこれらのノードに正確に関連付けられていますが、内部インフラストラクチャの動作の追跡は、多くの場合、「ダウン/ダウン」スタイルのデータの受信またはCPUの負荷のみに制限されています。同時に、近年の最大の被害と最も強力な障害は、内部障害またはインフラストラクチャエラーに正確に関連しています。昨年のCloudFlareのクラッシュを思い出すだけで十分です。多くの障害やエラーが原因で、開発者は文字通りインターネットの半分を自分の手で「横になる」ように強制しました。
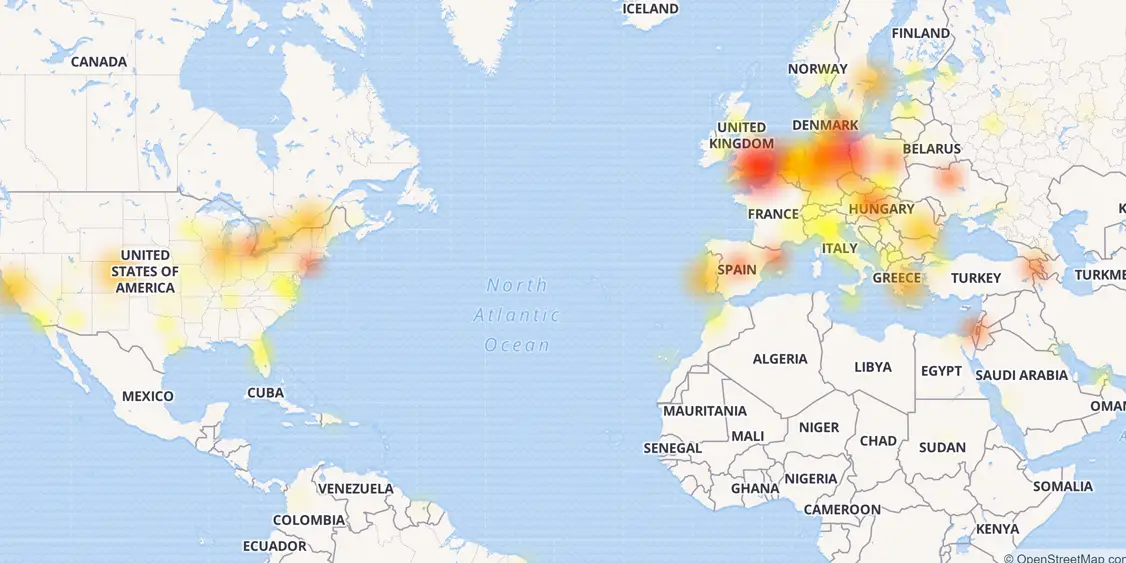
そのCloudFlare障害のマップ
新しいツールは、データベース障害、API、またはパフォーマンスの低下のシナリオ用の既製のテンプレートを作成するだけでなく、さまざまなノードで任意の順序で問題が発生するランダム化されたブラインドテスト条件を作成することもできます。
新しいAWSツールキットのもう1つの強みは、システム内のチームによって作成されたカオスの制御可能性です。エンジニアは、コントロールパネルの助けを借りて、開発者がいつでも制御された障害シナリオを停止し、システムを元の動作状態に戻すことができることを保証します。フォールトインジェクションシミュレータは、AmazonCloudWatchおよびAmazonEventBridgeを介して接続されたサードパーティの監視ツールをサポートしているため、開発者はメトリックを使用して、制御されたカオス実験を監視できます。もちろん、テストを停止した後、管理者は、障害の影響を受けたシステムノードとその順序に関する完全なレポートを受け取ります。これは、将来、問題を特定して排除するための一連の対策と手順の開発に役立ちます。
カオスの領主がどのように生まれたのか
明らかに、システムのこのようなストレステストは、AWSの既存のインフラストラクチャが新しいパッチに耐えることを確認するために、プレリリース期間に実行するのが最も論理的です。ただし、実際には、カオスエンジニアリング手法は古い手法にまでさかのぼります。その創設者は、2000年代のAmazonマネージャーの1人であるJesseRobbinsです。彼の立場は正式には「災害のマスター」と呼ばれ、哀れな翻訳では「大惨事の主」と間違えられる可能性があり、彼の自由な言葉では彼の立場は「マスターロマスター」のように聞こえました。 アマゾンでGameDay
 を実装したのは、元消防士救助者のロビンズ
でした。..。ロビンズイニシアチブの目標は非常に単純でした。つまり、火の旅団でその感覚が訓練されているように、エンジニアリングチームに災害への対処方法を直感的に理解させることです。このため、完全なカオスのグローバルシミュレーションの方法論が選択されました。すべてがすべての側面から同時にまたは順次に分解され、障害に対処しようとするたびに新しい問題が発生します。
を実装したのは、元消防士救助者のロビンズ
でした。..。ロビンズイニシアチブの目標は非常に単純でした。つまり、火の旅団でその感覚が訓練されているように、エンジニアリングチームに災害への対処方法を直感的に理解させることです。このため、完全なカオスのグローバルシミュレーションの方法論が選択されました。すべてがすべての側面から同時にまたは順次に分解され、障害に対処しようとするたびに新しい問題が発生します。
準備ができていない人が要素の暴動に直面したとき、彼はほとんどの場合、愚か者またはパニックに陥ります。ほとんどの開発者とエンジニアは、問題の解決に3日かかる状況に心理的に対応する準備ができておらず、周囲のストレスのレベルは単純にスケール外です。
ロビンズは、GameDayの最も重要な結果を、そのような演習の心理的効果と呼んでいます。彼らは、大規模な混乱が発生するという事実を受け入れる能力を発達さ せます。周りのすべてが燃えて崩壊しているという事実の受け入れであり、彼はそれをエンジニアにとって非常に重要であると呼び、彼は自分の考えを集めて最終的に「火を消し始める」ことができます。訓練を受けていない人は、せいぜい輪になって走り、「すべてが失われた」と叫ぶでしょう。
GameDayプラクティスの実装後、このような演習では、従来のテストと検証では注意を払わなかったアーキテクチャ上の問題とボトルネックを完全に特定することが判明しました 。
GameDayと通常の「トレーニングと注文」の演習とのもう1つの重要な違いは、特定のシナリオと一般的に何が起こるかを知っている人はほとんどいないということです。今後の「ゲーム」に関する情報は非常に一般的で漠然とした方法で提供されるため、参加者はこのイベントの準備を十分に行うことができませんでした。理想的には、参加者が実際の事故と間違えないように、明確化せずに次の「ゲームの日」の日付のみを発表することです。もちろん、この方法論は大企業には拡張できません。たとえば、GameDayをYandexまたはMicrosoft全体で一度に実行することはできません。
その結果、このプラクティスはローカルのGameDayにアップグレードされ、Google、Flickrなどの既存のすべての大規模IT企業に導入されました。独自の災害マスター(または、必要に応じてマスター-ロムマスター)があり、トレーニングの失敗を整理して、特定のプロジェクトで得られた結果を分析します。
このプラクティスをどこにでも実装することの主な難しさは、それを整理する方法と、GameDayが無駄にならないようにデータを収集する方法の2つの側面にあります。そのため、中小企業では、最近まで、この手法はあまり広く使用されていませんでした(使用されたとしても)。 GameDayや災害シミュレーションの代わりに、ビジネスは、秩序だった一貫した開発のために、さまざまなタイプのテスト、CI / CD、およびその他の方法論に重点を置きました。つまり、それ自体が大惨事を防ぐものについてです。
新しいAWSツールキットを使用すると、混乱の反対側に取り組むことができます。間違いなく重要な予防の代わりに、FISを使用すると、あらゆる規模のエンジニアリングチームが、グローバルなインフラストラクチャの混乱を解決するための効果的なトレーニングを行うことができます。結局のところ、ロビンズが指摘する主なことは、とにかく災害が発生するということです。災害は避けられません。