しかし、人々はコンピューターではないので、「そのようなものはイワノフまたはイワノフスキーからのものでした...いいえ、そうではありません、以前、さらに以前に...ここにあります!」の ようなものを探し ています。
しかし、これは開発者をひどい問題で脅かします-結局のところ、 PostgreSQLでのFTS検索では、「空間」 タイプのGINおよびGiSTインデックスが使用され、テキストベクトルを除いて追加データの「スリップ」を提供しません。
悲しいことに、プレフィックスの一致によってすべてのレコードを読み取るだけです (何千ものレコードがあります!)そして、並べ替えるか、逆に 、日付インデックスとフィルターを使用しますプレフィックスに対して見つかったすべてのレコードは、適切なレコードが見つかるまで一致します(「ギバーリッシュ」が発生するのはいつですか?..)。
どちらもクエリのパフォーマンスにはあまり適していません。それとも、クイック検索のために何かを考えることができますか?
まず、「現在までのテキスト」を生成しましょう。
CREATE TABLE corpus AS
SELECT
id
, dt
, str
FROM
(
SELECT
id::integer
, now()::date - (random() * 1e3)::integer dt -- - 3
, (random() * 1e2 + 1)::integer len -- "" 100
FROM
generate_series(1, 1e6) id -- 1M
) X
, LATERAL(
SELECT
string_agg(
CASE
WHEN random() < 1e-1 THEN ' ' -- 10%
ELSE chr((random() * 25 + ascii('a'))::integer)
END
, '') str
FROM
generate_series(1, len)
) Y;
素朴なアプローチ#1:要点+ btree
FTSと日付による並べ替えの両方でインデックスをロールしてみましょう-それらが役立つ場合はどうなりますか?
CREATE INDEX ON corpus(dt);
CREATE INDEX ON corpus USING gist(to_tsvector('simple', str));
で始まる単語を含むすべてのドキュメントを検索し
'abc...'
ます。そして、最初に、そのようなドキュメントがほとんどなく、FTSインデックスが通常使用されていることを確認しましょう。
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*');
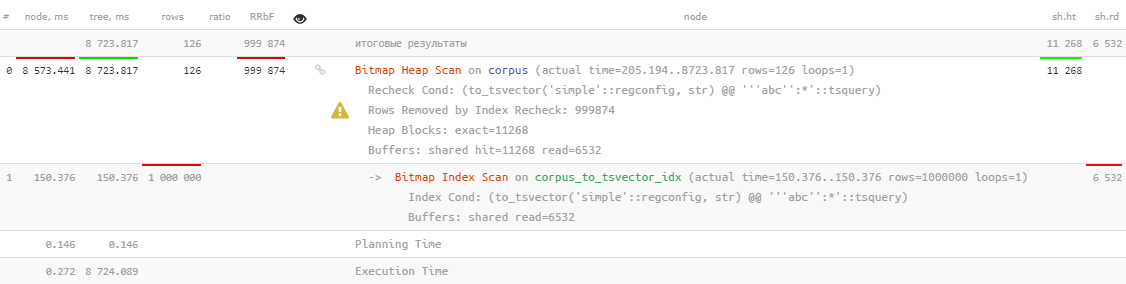
ええと...もちろん使用されていますが、8秒以上かかり ます。これは明らかに126レコードの検索に費やしたいものではありません。
おそらく、日付による並べ替えを追加して 、最後の10レコードのみを検索 すると、より良い結果が得られますか?
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*')
ORDER BY
dt DESC
LIMIT 10;

しかし、いいえ、並べ替えだけが上に追加されました。
素朴なアプローチ#2:btree_gist
ただし
btree_gist
、スカラー値をGiSTインデックスに「スリップ」できる優れた拡張機能 があります。これにより、kNN検索に使用できる距離演算子を
<->
使用してインデックスの並べ替えをすぐに使用 できるように なります。
CREATE EXTENSION btree_gist;
CREATE INDEX ON corpus USING gist(to_tsvector('simple', str), dt);
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*')
ORDER BY
dt <-> '2100-01-01'::date DESC -- ""
LIMIT 10;
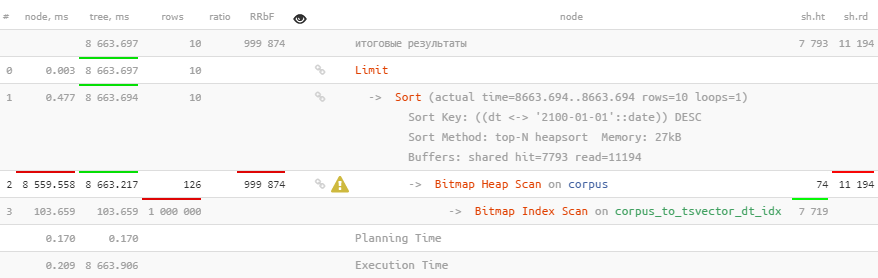
残念ながら、これはまったく役に立ちません。
救助のための幾何学!
しかし、絶望するには時期尚早です!組み込みのGiST演算子クラスのリストを見てみましょう。 距離演算子は「幾何学的」でのみ
<->
使用でき、PostgreSQL13以降 はで 使用できます 。 それでは、問題を「平面に」変換してみましょう。検索に使用するペアにいくつかのポイントの座標を 割り当てて、「接頭辞」の単語と遠くない日付をできるだけ近づけます。
circle_ops, point_ops, poly_ops
box_ops
(, )

テキストを単語に分割します
もちろん、同時に複数の単語に条件を設定することはできないという意味で、私たちの検索は完全にフルテキストではありません。しかし、それは間違いなくプレフィックスになります!
補助辞書テーブルを作成しましょう。
CREATE TABLE corpus_kw AS
SELECT
id
, dt
, kw
FROM
corpus
, LATERAL (
SELECT
kw
FROM
regexp_split_to_table(lower(str), E'[^\\-a-z-0-9]+', 'i') kw
WHERE
length(kw) > 1
) T;
この例では、100万の「テキスト」あたり480万の「単語」がありました。
言葉を置く
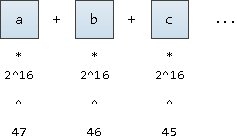
単語をその「座標」に変換するために、これが基本表記で書かれた数値であると
2^16
想像してみましょう (結局のところ、UNICODEシンボルもサポートしたいと思います)。固定の47番目の位置から書き留めるだけです:
63番目の位置から始めることは可能です、これはの
1E+308
制限 値よりわずかに小さい値を与えます
double precision
が、インデックスを構築するときにオーバーフローが発生します。
座標軸上ですべての単語が順序付けられることがわかります。

ALTER TABLE corpus_kw ADD COLUMN p point;
UPDATE
corpus_kw
SET
p = point(
(
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
);
CREATE INDEX ON corpus_kw USING gist(p);
検索クエリを作成します
WITH src AS (
SELECT
point(
( --
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
) ps
FROM
(VALUES('abc', '2100-01-01'::date)) T(kw, dt) --
)
SELECT
*
, src.ps <-> kw.p d
FROM
corpus_kw kw
, src
ORDER BY
d
LIMIT 10;

これで、探していた
id
ドキュメントが 正しい順序で並べ替えられました。 所要時間は2ミリ秒未満で、4000倍速くなりました。
軟膏の小さなハエ
オペレーター
<->
は2つの軸に沿った順序について何も知らないため、必要なデータは、日付による必要な並べ替えに応じて、適切な四半期の1つにのみ配置されます。

それでも、キーワードではなく、テキスト自体を選択したかったのです。したがって、長い間忘れられていたインデックスが必要になります。
CREATE UNIQUE INDEX ON corpus(id);
リクエストを確定しましょう:
WITH src AS (
SELECT
point(
(
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
) ps
FROM
(VALUES('abc', '2100-01-01'::date)) T(kw, dt) --
)
, dc AS (
SELECT
(
SELECT
dc
FROM
corpus dc
WHERE
id = kw.id
)
FROM
corpus_kw kw
, src
WHERE
p[0] >= ps[0] AND -- kw >= ...
p[1] <= ps[1] -- dt DESC
ORDER BY
src.ps <-> kw.p
LIMIT 10
)
SELECT
(dc).*
FROM
dc;

彼ら
InitPlan
は定数x / yの計算で少し追加しました が、それでも同じ2ミリ秒以内に保ちました !
軟膏#2で飛ぶ
無料のものはありません:
SELECT relname, pg_size_pretty(pg_total_relation_size(oid)) FROM pg_class WHERE relname LIKE 'corpus%';
corpus | 242 MB -- corpus_id_idx | 21 MB -- PK corpus_kw | 705 MB -- corpus_kw_p_idx | 403 MB -- GiST-
242MBの「テキスト」が1.1GBの「検索インデックス」になりました。
しかし、結局のところ、
corpus_kw
日付と単語自体は、 検索では使用していませんので、削除しましょう。
ALTER TABLE corpus_kw
DROP COLUMN kw
, DROP COLUMN dt;
VACUUM FULL corpus_kw;
corpus_kw | 641 MB -- id point
ささいなことですが、いいです。それはあまり役に立ちませんでしたが、それでもボリュームの10%が取り戻されました。