前書き
オンラインデータを使用して機械学習の問題に取り組む場合、さらに分析および評価するために、さまざまなエンティティを1つにまとめる必要があります。収集プロセスは便利で高速でなければなりません。また、多くの場合、追加の労力や日常的な作業なしで、開発から産業用へのシームレスな移行を提供する必要があります。Feature Storeアプローチを使用して、この問題を解決できます。このアプローチについては、ここで詳しく説明しています。ミケランジェロに会う:Uberの機械学習プラットフォーム。この記事では、指定された機能管理ソリューションをプロトタイプとして解釈する方法について説明します。
オンラインストリーミング用の機能ストア
Feature Storeは、仕様に厳密に従って機能を実行する必要があるサービスと見なすことができます。この仕様を定義する前に、簡単な例を分解する必要があります。
例
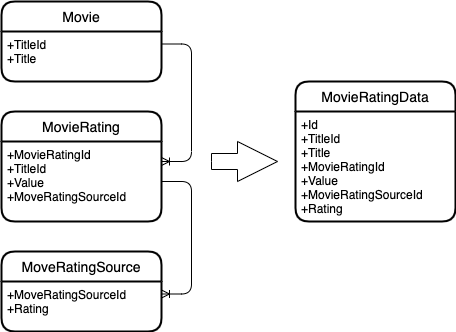
次のエンティティを指定します。
IDとタイトルのある映画。
映画の評価。独自の識別子、映画の識別子、評価値もあります。レーティングは時間とともに変化します。
独自の評価もある評価ソース。そしてそれは時間とともに変化します。
そして、これらのエンティティを1つに結合する必要があります。
これが何が起こるかです。
エンティティ図
ご覧のとおり、マージはエンティティキーによって行われます。それら。すべての映画の評価で映画が検索され、すべてのソースの評価で映画の評価が検索されます。
例の一般化
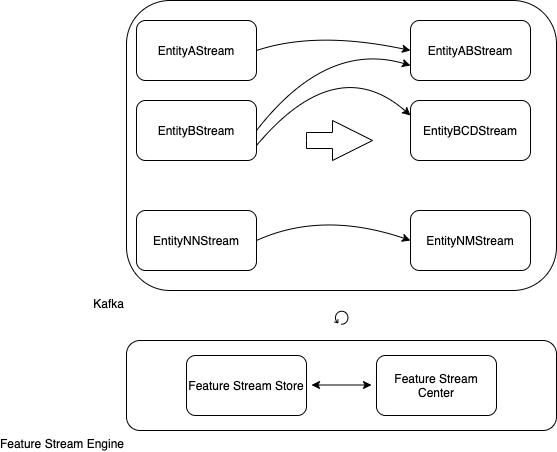
, .
kafka-, : A, B… NN.
: AB, BCD… NM.
: Feature Stream Engine.
Feature Stream Engine kafka-, Feature Stream Store Feature Stream Center, .
Feature Stream Engine
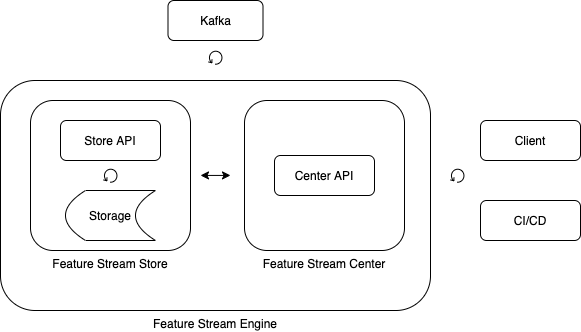
Feature Stream Store
, .
– (feature).
, , .
.
Feature Stream Center
, , .
Feature Stream Engine
Feature Stream Engine , .
Feature Stream Engine
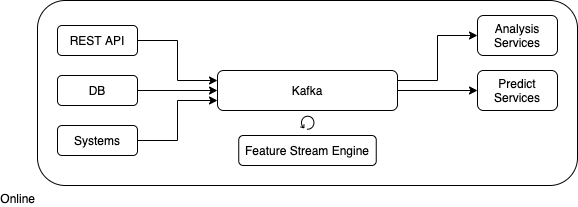
Feature Stream Engine
Feature Stream Engine , .
Feature Stream Engine .
.
kafka.
.
( ).
, .
Feature Stream Engine
.
.
, ("configration.properties").
.
topic- kafka. “,”.
. “,”.
topic-.
, .
public static FeaturesDescriptor createFromProperties(Properties properties) {
String sources = properties.getProperty(FEATURES_DESCRIPTOR_FEATURE_DESCRIPTORS_SOURCES);
String keys = properties.getProperty(FEATURES_DESCRIPTOR_FEATURE_DESCRIPTORS_KEYS);
String sinkSource = properties.getProperty(FEATURES_DESCRIPTOR_SINK_SOURCE);
String[] sourcesArray = sources.split(",");
String[] keysArray = keys.split(",");
List<FeatureDescriptor> featureDescriptors = new ArrayList<>();
for (int i = 0; i < sourcesArray.length; i++) {
FeatureDescriptor featureDescriptor =
new FeatureDescriptor(sourcesArray[i], keysArray[i]);
featureDescriptors.add(featureDescriptor);
}
return new FeaturesDescriptor(featureDescriptors, sinkSource);
}
public static class FeatureDescriptor {
public final String source;
public final String key;
public FeatureDescriptor(String source, String key) {
this.source = source;
this.key = key;
}
}
public static class FeaturesDescriptor {
public final List<FeatureDescriptor> featureDescriptors;
public final String sinkSource;
public FeaturesDescriptor(List<FeatureDescriptor> featureDescriptors, String sinkSource) {
this.featureDescriptors = featureDescriptors;
this.sinkSource = sinkSource;
}
}
.
void buildStreams(StreamsBuilder builder)
topic-, , , .
Serde<String> stringSerde = Serdes.String();
List<KStream<String, String>> streams = new ArrayList<>();
for (FeatureDescriptor featureDescriptor : featuresDescriptor.featureDescriptors) {
KStream<String, String> stream =
builder.stream(featureDescriptor.source, Consumed.with(stringSerde, stringSerde))
.map(new KeyValueMapperSimple(featureDescriptor.key));
streams.add(stream);
}
.
KStream<String, String> pref = streams.get(0);
for (int i = 1; i < streams.size(); i++) {
KStream<String, String> cur = streams.get(i);
pref = pref.leftJoin(cur,
new ValueJoinerSimple(),
JoinWindows.of(Duration.ofSeconds(1)),
StreamJoined.with(
Serdes.String(),
Serdes.String(),
Serdes.String())
);
}
topic.
pref.to(featuresDescriptor.sinkSource);
.
public void buildStreams(StreamsBuilder builder) {
Serde<String> stringSerde = Serdes.String();
List<KStream<String, String>> streams = new ArrayList<>();
for (FeatureDescriptor featureDescriptor : featuresDescriptor.featureDescriptors) {
KStream<String, String> stream =
builder.stream(featureDescriptor.source, Consumed.with(stringSerde, stringSerde))
.map(new KeyValueMapperSimple(featureDescriptor.key));
streams.add(stream);
}
if (streams.size() > 0) {
if (streams.size() == 1) {
KStream<String, String> stream = streams.get(0);
stream.to(featuresDescriptor.sinkSource);
} else {
KStream<String, String> pref = streams.get(0);
for (int i = 1; i < streams.size(); i++) {
KStream<String, String> cur = streams.get(i);
pref = pref.leftJoin(cur,
new ValueJoinerSimple(),
JoinWindows.of(Duration.ofSeconds(1)),
StreamJoined.with(
Serdes.String(),
Serdes.String(),
Serdes.String())
);
}
pref.to(featuresDescriptor.sinkSource);
}
}
}
.
void run(Properties config)
( ).
FeaturesStream featuresStream = new FeaturesStream(config);
kafka.
StreamsBuilder builder = new StreamsBuilder();
featuresStream.buildStreams(builder);
Topology topology = builder.build();
KafkaStreams streams = new KafkaStreams(topology, featuresStream.buildStreamsProperties());
.
streams.start();
.
public static void run(Properties config) {
StreamsBuilder builder = new StreamsBuilder();
FeaturesStream featuresStream = new FeaturesStream(config);
featuresStream.buildStreams(builder);
Topology topology = builder.build();
KafkaStreams streams = new KafkaStreams(topology, featuresStream.buildStreamsProperties());
CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
streams.close();
latch.countDown();
}));
try {
streams.start();
latch.await();
} catch (Throwable e) {
System.exit(1);
}
System.exit(0);
}
.
java -jar features-stream-1.0.0.jar -c plain.properties
: Java 1.8.
: kafka 2.6.0, jsoup 1.13.1.
. .
1つ目:トピックからユニオンへの迅速な構築を可能にします。
2番目:さまざまな環境ですばやくマージを開始できます。
このソリューションは、入力データの構造に制約を課していることに注意してください。つまり、トピック-そして表形式の構造でなければなりません。この制限を克服するために、さまざまな構造を表形式に縮小できる追加のレイヤーを導入できます。
全機能を産業用に実装するには、非常に強力で、最も重要なのは柔軟な機能であるKSQLに注意を払う必要があります。
リンクとリソース
ソースコード;
ミケランジェロに会いましょう:Uberの機械学習プラットフォーム。