
この問題は、人工薬剤を設計するときにも発生します。たとえば、強化学習エージェントは、人間の設計者が意図したように割り当てを完了することなく、大量の報酬を受け取るための最短ルートを見つけることができます。この動作は一般的であり、これまでに約60の例を収集しました (既存の リストとAIコミュニティからの現在の 貢献を組み合わせて )。この投稿では、仕様に従ってゲームの考えられる原因を調べ、実際に発生する場所の例を共有し、仕様の問題を克服するための原則的なアプローチについてさらに作業する必要があることについても議論します。
例を見てみましょう。レゴブロックを使用した構築タスク では、望ましい結果は、赤いブロックが青いブロックの上になることでした。エージェントは、赤いブロックに触れなかった瞬間の赤いブロックの底面の高さに対して報酬を受け取りました。赤いブロックを拾い上げて青いブロックの上に置くという比較的難しい操作を行う代わりに、エージェントは単に赤いブロックを裏返して報酬を集めました。この動作により、設計者が本当に気にかけていること(青いボックスの上に構築)を犠牲にして、目標(赤いボックスの底面が高い)を達成することができました。

器用なデータ操作のための深い強化学習。
仕様ゲームは2つの観点から見ることができます。強化学習(RL)アルゴリズムの開発の一環として、目標は、特定の目標を達成することを学習するエージェントを作成することです。たとえば、RLアルゴリズムを教えるためのベンチマークとしてAtariゲームを使用する場合、目標は、アルゴリズムが複雑な問題を解決できるかどうかを評価することです。エージェントが抜け穴を使用して問題を解決するかどうかは、このコンテキストでは重要ではありません。この観点から、スペックでプレイすることは良い兆候です。エージェントはこの目標を達成するための新しい方法を見つけました。この振る舞いは、私たちが指示したとおりに実行する方法を見つけるためのアルゴリズムの創意工夫と力を示しています。
ただし、エージェントに実際にLegoブロックを接続させたい場合は、同じ工夫で問題が発生する可能性があります。世界で望ましい結果を達成するターゲットエージェントを構築するというより広いフレームワークで は、仕様ゲームは、エージェントが望ましい結果を犠牲にして仕様の抜け穴を悪用することを伴うため、問題があります。この動作は、RLアルゴリズムの欠陥ではなく、誤った問題設定が原因で発生します。アルゴリズムの設計に加えて、ターゲットエージェントを構築するために必要なもう1つのコンポーネントは、報酬の設計です。
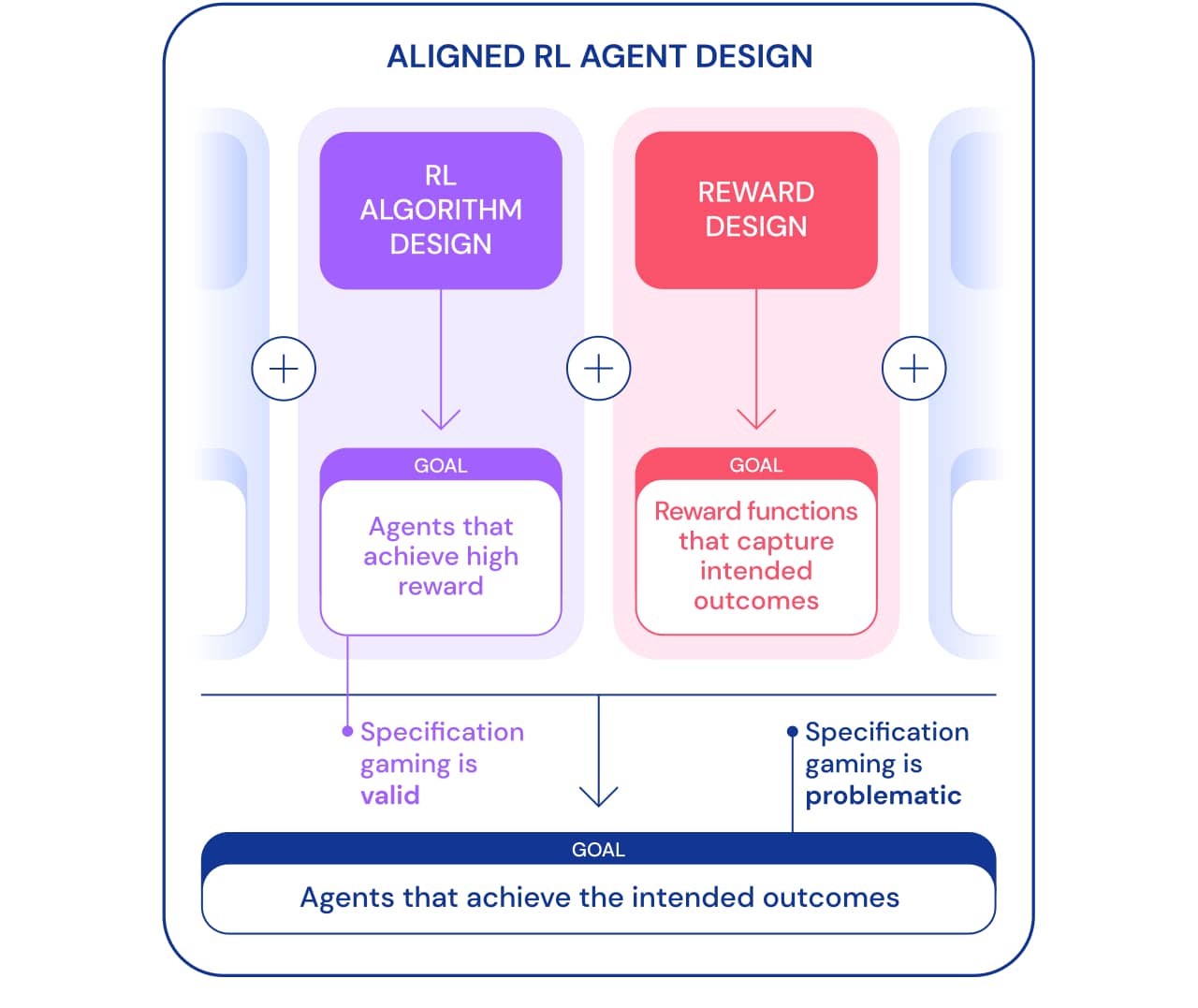
人間の設計者の意図を正確に反映するタスク仕様(報酬機能、環境など)を設計することは通常困難です。わずかな誤解があっても、非常に優れたRLアルゴリズムは、意図したものとは大きく異なる複雑なソリューションを見つけることができます。より弱いアルゴリズムがこの解決策を見つけることができず、したがって意図した結果に近い解決策を得ることができなくても。これは、RLアルゴリズムが向上するにつれて、目的の結果を正しく定義することがより重要になる可能性があることを意味します。したがって、問題を正しく定義する研究者の能力が、新しい解決策を見つけるエージェントの能力に遅れをとらないことが重要です。
タスク仕様という用語は、エージェント開発プロセスの多くの側面を含む広い意味で使用されます。 RLを設定する場合、タスクの仕様には、報酬の設計だけでなく、学習環境の選択と報酬のサポートも含まれます。問題ステートメントの正確さにより、エージェントの創意工夫が意図した結果に対応しているかどうかを判断できます。仕様が正しければ、エージェントの創造性が望ましい新しいソリューションを生み出します。これがAlphaGoが有名な37番目の動きをすることを可能にしたもの です。、ゴーの専門家を驚かせたが、リー・セドルとの2回目の試合で重要な役割を果たした。仕様が正しくない場合、ブロックの反転など、望ましくないゲーム動作につながる可能性があります。そのような解決策は可能であり、私たちはそれらに気付く客観的な方法がありません。

それでは、スペックゲームの考えられる理由を見てみましょう。報酬機能に関する誤解の原因の1つは、不十分に設計された報酬の生成です。報酬の形成は、最終結果に対してのみ報酬を与えるのではなく、問題を解決する途中でエージェントに報酬を与えることにより、特定の目標を容易に吸収できるようにします。ただし、報酬の形成は、視点に基づいていない場合、最適なポリシーを変更する可能性があり ます。コーストランナーでボートを走らせているエージェントを考えてみましょう 意図された目標は、できるだけ早くレースを終了することです。エージェントは、レーストラックに沿って緑のブロックと衝突したことに対して形成的な報酬を受け取りました。これにより、サークルを一周して同じ緑のブロックと何度も衝突するという最適なポリシーが変更されました。

誤った報酬が機能しています。
望ましい最終結果を正確に反映する賞を決定することは、それ自体が困難な作業になる可能性があります。レゴブロックの接続の問題では、エージェントはこの目標を達成するために赤いブロックを裏返すだけでよいため、赤いブロックの下端を床から高くする必要があることを示すだけでは不十分です。望ましい結果のより完全な仕様には、赤いボックスの上面を下面よりも高くする必要があり、下面が青いボックスの上面と位置合わせされることも含まれます。結果を決定するときにこれらの基準の1つを見落とすのは簡単です。そのため、仕様が広すぎて、縮退したソリューションで満たすのが簡単になる可能性があります。
考えられるすべてのコーナーケースをカバーする仕様を作成しようとするのではなく、人間のフィードバックから報酬関数を学ぶことができ ます。多くの場合、結果を明示的に述べるよりも、結果が達成されたかどうかを評価する方が簡単です。ただし、報酬モデルがデザイナーの好みを反映する真の報酬関数を研究していない場合、このアプローチはゲーム仕様の問題に遭遇する可能性もあります。不正確さの考えられる原因の1つは、報酬モデルのトレーニングに使用される人間のフィードバックである可能性があります。たとえば、キャプチャタスクを実行するエージェント は、カメラとオブジェクトの間にカーソルを合わせると、評価者をだますことを学びました。

人間の好みに基づいて深い学習を強化します。
訓練された報酬モデルは、一般化が不十分であるなど、他の理由で誤って定義されることもあります。追加のフィードバックを使用して、報酬モデルの不正確さを悪用しようとするエージェントの試みを修正できます。
仕様による別のクラスのゲームは、シミュレータのバグを悪用するエージェントからのものです。たとえば、歩くことを学ばなければならなかった シミュレートされたロボットは、足を一緒にロックして地面に沿ってスライドするというアイデアを思いつきました。
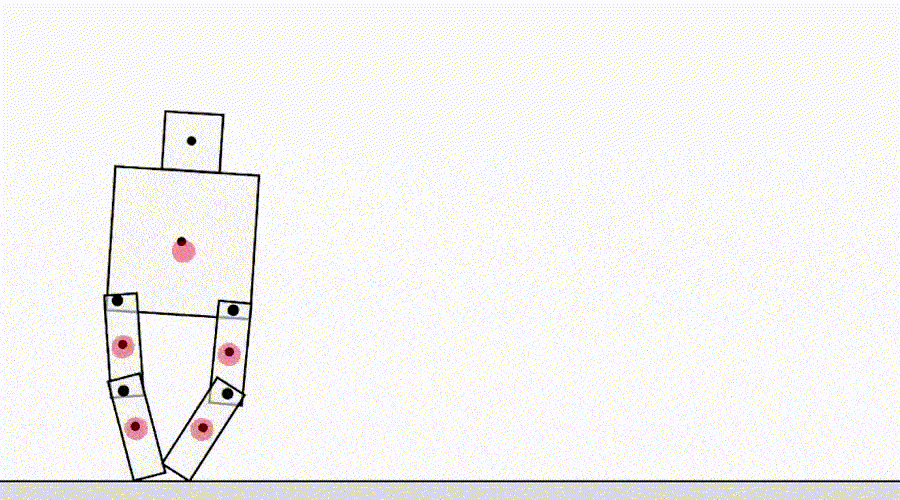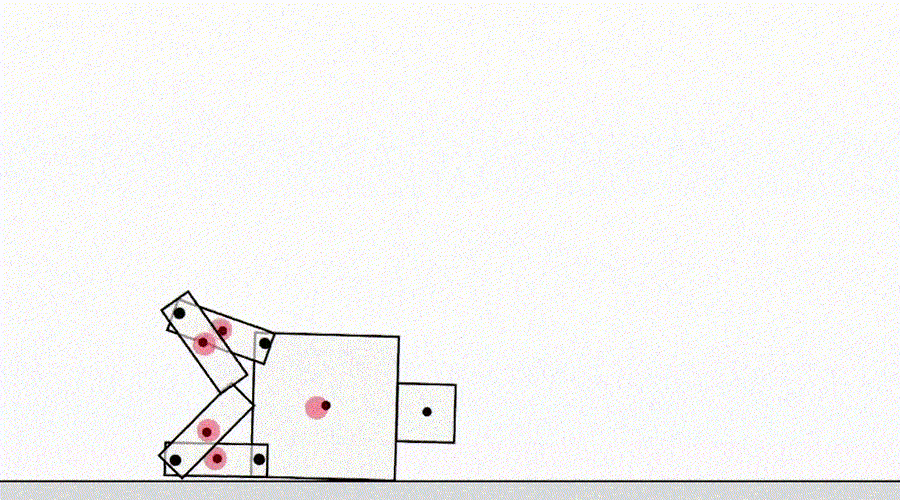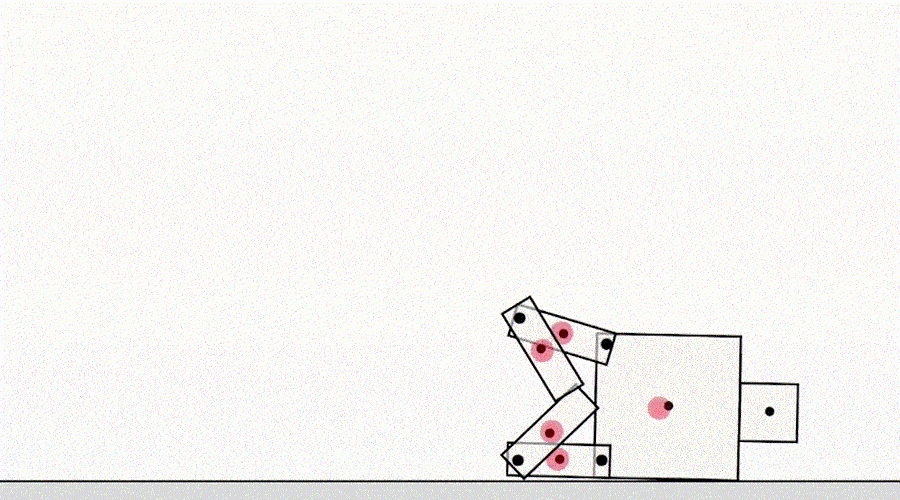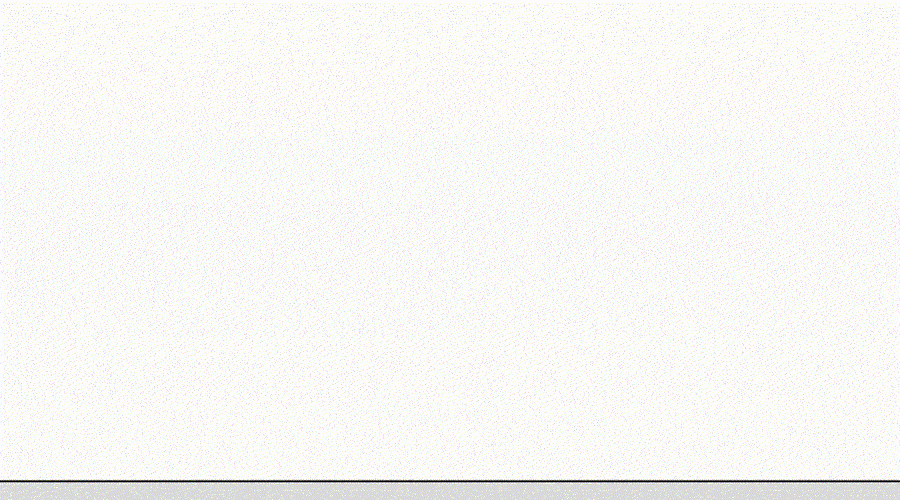
AIは歩くことを学びます。
一見、そのような例は面白そうに見えるかもしれませんが、あまり面白くなく、シミュレーターエラーがない現実の世界でのエージェントの展開とは何の関係もありません。ただし、主な問題はエラー自体ではなく、エージェントが使用できる抽象化の失敗です。上記の例では、シミュレーターの物理に関する誤った仮定のために、ロボットのタスクが誤って定義されていました。同様に、トラフィックルーティングインフラストラクチャに、十分にスマートなエージェントが検出する可能性のあるソフトウェアのバグやセキュリティの脆弱性が含まれていないと想定される場合、実際のトラフィックの最適化は誤認される可能性があります。このような仮定は、明示的に行う必要はありません。むしろ、設計者の心を決して超えなかった詳細です。そして、タスクが複雑になりすぎるとすべての詳細を考慮に入れるために、研究者は仕様を開発するときに誤った仮定を導入する可能性が高くなります。これは疑問を投げかけます:それらを使用する代わりにそのような誤った仮定を修正するエージェントアーキテクチャを設計することは可能ですか?
タスク仕様で一般的に使用される前提条件の1つは、仕様がエージェントのアクションの影響を受けないことです。これは、分離されたシミュレータで動作するエージェントには当てはまりますが、現実の世界で動作するエージェントには当てはまりません。すべてのタスク仕様には、物理的な兆候があります。つまり、コンピューターに保存されている報酬関数、または個人の好みです。現実の世界に配置されたエージェントは、これらの目的の概念を操作する可能性があり、報酬の偽造の問題を 引き起こします。私たちの架空のトラフィック最適化システムでは、ユーザーの好みを満たすこと(たとえば、役立つガイダンスを提供することによって)とユーザーに影響を与えることの間に明確な区別はありません 。満足しやすい好みを持つようにします(たとえば、到達しやすい目的地を選択するようにナッジすることによって)。前者はタスクを満たし、後者は目標の世界観(ユーザーの好み)を操作し、どちらもAIシステムに高い報酬をもたらします。もう1つのより極端な例として、非常に高度なAIシステムが、実行中のコンピューターを引き継いで、独自の報酬を高い値に設定できます。

要約すると、ゲーム仕様の問題を解決する際に克服しなければならない問題が少なくとも3つあると言えます。
- 特定のタスクの人間の概念を報酬関数として正確にキャプチャするにはどうすればよいですか?
- , , ?
- ?
報酬のモデル化からエージェントへのインセンティブの開発に至るまで、多くのアプローチが提案されてきましたが、仕様によるプレイの問題はまだ解決されていません。 考えられる仕様の動作のリストは、問題の規模と、エージェントが仕様を回避するための無数の方法を示しています。 AIシステムが意図した結果を犠牲にしてタスク仕様を満たすことができるようになるにつれて、これらの問題は将来さらに複雑になる可能性があります。より高度なエージェントを構築するにつれて、仕様の問題に具体的に対処し、これらのエージェントが開発者が意図した結果を確実に達成できるようにする設計原則が必要になります。
機械と深層学習についてもっと学びたい場合は、適切なコースに立ち寄ってください。難しいですが、エキサイティングです。また、プロモーションコード HABRは、バナーの割引に10%を追加することで、新しいことを学ぶための努力を支援します。
