dentsuでは、ポッドキャストのオーディエンスを測定し、その中の広告を計画するための分析ツールであるPodcasterを考案しました。データの収集を開始し、視聴者認識の問題をどのように解決したか、どのような問題が発生したか、そして何が起こったのかを、この記事で説明します。

バックグラウンド
ポッドキャストのスケジュールは、ポッドキャストの作成者に連絡してリスナーの説明を求める販売者(スタジオまたは専門機関)からのデータに基づいています。ポッドキャスター自体は、ポッドキャストが投稿されたプラットフォームまたは外部の統計システムからデータを受信します。このアプローチにはいくつかの制限があります。
- ポッドキャストは、売り手が同意し、ポッドキャストの聴衆に関するデータを持っている限られたリストから選択できます。
- より親和性の高いポッドキャストを選択する方法はありません(親和性とは、すべてのポッドキャストリスナーに対するリスナー間の特定のターゲットオーディエンスの比率です)。これは、原則として、リスナーのコアの説明が利用可能であり、ほとんどのポッドキャストの年齢に関しては一般的に同じであるためです。
- ポッドキャスター自体は各ポッドキャストに関するデータを持っていますが、ポッドキャスターもセラーも、リスナーがポッドキャスト間でどのように交差するかを知りません。
ポッドキャストのスケジューリングをよりスマートにするために、既存のポッドキャストのリストとこれらのポッドキャストを聞いているユーザーのベースからのデータ、およびこれらの同じリスナーの性別と年齢を判別する機能に基づく統合分析システムの形成を試みました。
アプローチ
ユーザー固有のオーディションを自分たちで受けることができないことにすぐに気づきました。しかし、ポッドキャストにはいいね/サブスクリプションがあります。たとえば、Instagramでブロガーと一緒に、ある人が自分のニュースを見るためにブロガーにサブスクライブすると、同様のメカニズムが機能します。同じ話がポッドキャストでも起こっていると仮定しました。リスナーはお気に入りのポッドキャストを購読して、すばやくアクセスして新しいエピソードをフォローできるようにします。
視聴者がポッドキャストを聞くための一般的なプラットフォームを使用して、この仮説をテストすることにしました。 Tiburonによると、Yandex.Musicはポッドキャストを聴くリーダーです。
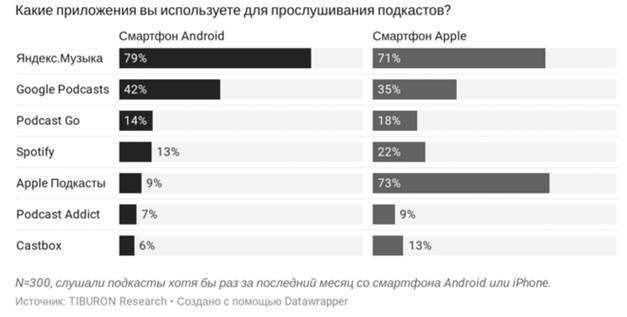
幸い、Ya Musicには、ポッドキャストのサブスクリプションに関する情報を提供するユーザーページがあります。
写真とポッドキャストのサブスクリプションを含むプロファイルの例
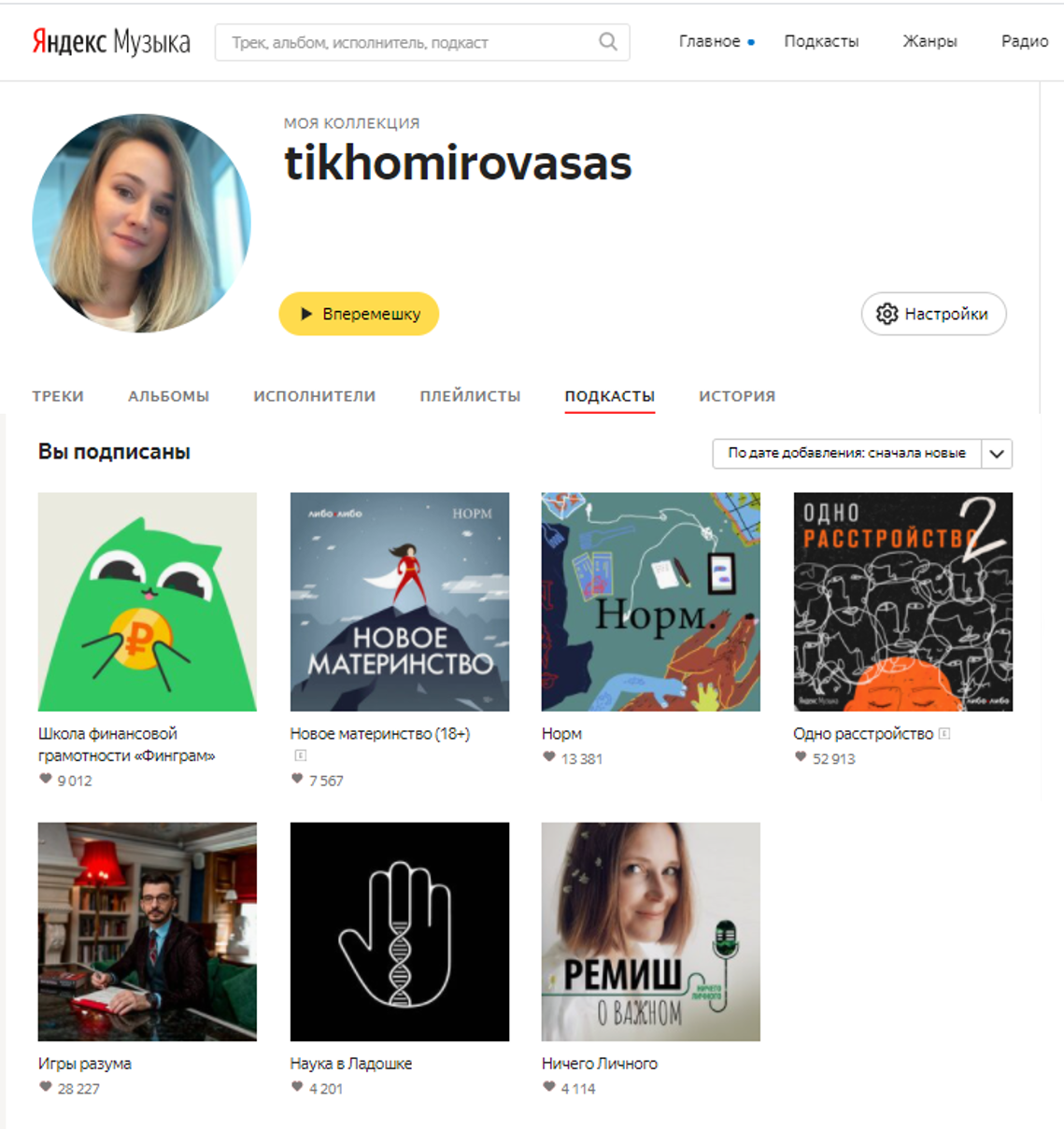
サブスクリプション自体に加えて、パブリックドメインにはニックネームとユーザーアバターがあります。実際、ポッドキャストリスナーのコア、つまり定期的にリスナーを聴いている人がいるので、これはすでに何かです。また、ここに私たちが見つけたかった非常にユーザーポッドキャストのリンクがあります。
力学
リスナーがサブスクライブしたユーザーとポッドキャストなどのデータの収集を開始しました。当初、Yandexでメールボックスを提供したdentsu従業員のデータに関するポッドキャストを持っているYa.Muzykaユーザーを見つけました。数年前から公開データを扱ってきたので、プロジェクトの規模を拡大することは難しくありませんでした。
幸いなことに、ポッドキャストのサブスクライバーベースは非常に急速に集まっていました。わずか1か月半で、少なくとも1つのポッドキャストをサブスクライブした10,000人を超えるユーザーが獲得しました。
しかし、悪いニュースもありました。写真とニックネームで性別と年齢を目で判断できるとは限りません。むしろ、まったく不可能です。私たちにとって、さまざまなオーディエンスに関連するポッドキャストを選択できるようにするために、性別と年齢なしではできません。 私たちのニューラルネットワーク
は、写真から性別と年齢を決定するというこのタスクに対処しました 。その精度は96%です。アルゴリズムは単純です。ユーザーJ.Musicの写真を撮り、顔を探し、それを使用して性別と年齢を判断します。 顔は顔認識ライブラリによって検出されます
dlibを使用します。また、ニューラルネットワークの中心には、ResNet-50アーキテクチャに基づく事前トレーニング済みのVGGFaceモデルがあります。これは、パブリックAPIから入手できるVKユーザーの写真でトレーニングしたものです。データセットは100万枚の写真で構成されており、アルバム化によってさらに補強されています。12歳未満および65歳以上のユーザーの写真はトレーニング目的では考慮されないことに注意してください。
結果
トレーニングの結果、ポッドキャストを使用したユーザープロファイルの約45%で、写真や写真、シンボル、または単に低品質の写真がないプロファイルが多数あるため、性別と年齢を特定できることがわかりました。しかし、この結果でさえ私たちに合っています。
ポッドキャストを購読するプロファイルを見つけるダイナミクスを考慮すると、数か月以内にリスナーベースは50,000プロファイルになり、そのうち22,500は性別と年齢になると予想されます。
性別や年齢を特定できないプロファイルの例
現在の開発により、さまざまなオーディエンスグループの親和性のあるポッドキャストのサンプルを作成できます。
ブランドに関連するトピックの20〜50のポッドキャストの選択

親和性=ポッドキャストリスナー/すべてのポッドキャストリスナーのターゲットオーディエンス)/(すべてのポッドキャストリスナー/ポッドキャスト
を持つすべての人々)広告主が興味を持っている場合は、特定のポッドキャストを分析することもできます。
ポッドキャストを購読している人の数を確認することで、最大のリーチを構築するポッドキャストパッケージに関する推奨事項を作成できます。
選択した50個のポッドキャストのカバレッジ曲線
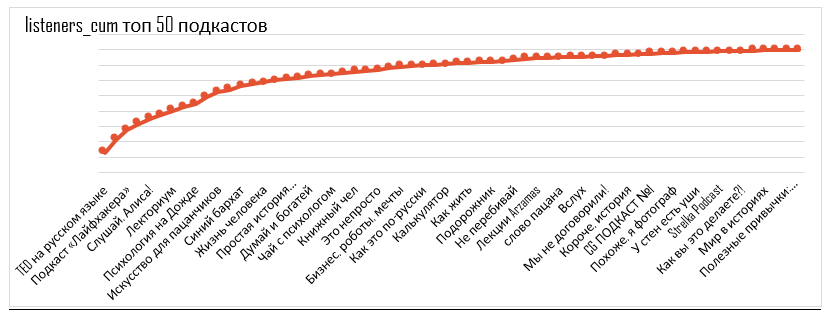
各ポイントは、ミックスごとに+1ポッドキャスト。最初のドットは最大の固有オーディエンスを持つポッドキャストであり、最後のドットは最小の固有オーディエンスを持つポッドキャストです。
曲線力学と数学モデル
まず、オーディエンスの多いポッドキャスト(この場合はポッドキャスト3)を取り上げます。以下は、ブルートフォースロジック、つまり、ポッドキャスト間で調停者を分散する原理を示した表です。

次に、ポッドキャスト3で到達したリスナーを取り消し、最もユニークなオーディエンスを持つポッドキャスト(ポッドキャスト4)を再度選択します。これは2つの新しいユニークなリスナーを提供するポッドキャストなので、次に配置することをお勧めします。

演習を繰り返しますが、これ以上ユニークなリスナーをカバーすることはありません。つまり、6つのポッドキャストのうち2つに配置するだけで、すべてのユニークなオーディエンスをカバーできます。

結論
すべての質問に答えたわけではないので、引き続きデータを検索します。たとえば、最近、Ya.Muzykaは、各ポッドキャストのサブスクライブされたオーディエンスの数に関する情報の公開を開始しました。これで、合計から収集されたリスナーの量がわかりました。
サブスクリプションデータをサイトやポッドキャスターからのデータと組み合わせて、リスナーの数と構成を推定するためのモデルを改良するメカニズムに取り組んでいます。しかし、すでに現在、私たちのアプローチは、ポッドキャストでの広告統合のスケジュールを変更し、ポッドキャストのオーディエンスに関する販売者または広告主の直感の集約データからではなく、ブランドのオーディエンスから進めるのに役立っています。また、このブランドのオーディエンスに特に関連するポッドキャストパッケージを作成し、最大限のリーチを構築します。
著者 Sasha_Kopylova