
こんにちは、Habr!私はデータを読んで収集するのが大好きです。 2020年は8784時間で構成され、そのうち4874時間は、収集した統計で考慮に入れることができました。去年全体の55%をどのように過ごしたか知っています!この記事では、大学で勉強することはまったく難しいことではないことを証明しようとします。また、私の時間追跡の方法についても説明すると同時に、私が行うほとんどすべてのことに費やした時間について、1年間に収集したデータを精神的に分析します。大学での勉強の最初から、各学期の初めに、ため息をついている学生を見ました。「ああ、ランクが始まった!そして今、ひどい理論家だ!違いが詰まっている。TAUやランダムなプロセスを閉じるのはどれほど難しいか」。そして、試験に合格するたびに、そして安心して息を吐くたびに、私たちは多くの時間を費やしたので、そのような難しい問題を解決しました...そしてどれほど難しいですか?今何時ですか?遠くに行く主観的な意見は非常に主観的であるため、私はこれらの質問を頻繁に行いました。私たちは工科大学で勉強していますが、数字はどこにありますか?よく勉強し始めてから、他の学生の判断に戸惑うようになり、頭脳がラッキーだったそうです。そして、今週彼らがどれくらい悩んでいるのかと尋ねると、「まあ、わからない、約2時間」とよく耳にしました。最近、私はこの質問に非常に明確に答えることができ、明白な理論に賛成する証拠を集めました。研究の問題では、頭の中の灰色の物質の量ではなく、費やした時間の量はまったく運の問題ではありません。そして、彼らが今週どれくらい悩んだかという私の質問に対して、私はしばしば「まあ、私にはわかりません、約2時間」と聞きました。最近、私はこの質問に非常に明確に答えることができ、明白な論文に賛成する証拠を集めました。研究の問題では、頭の中の灰色の物質の量ではなく、費やした時間の量はまったく運の問題ではありません。そして、彼らが今週どれくらい悩んだかという私の質問に対して、私はしばしば「まあ、私にはわかりません、約2時間」と聞きました。最近、私はこの質問に非常に明確に答えることができ、明白な理論に賛成する証拠を集めました。研究の問題では、頭の中の灰色の物質の量ではなく、費やした時間の量はまったく運の問題ではありません。
clockify.me ? Data Science, , , , , , . ? ( , , )
, , , . , , , , 60 . , .
-, . , . .
/
import math
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import matplotlib.dates as dates
import matplotlib.dates as mdates
file_name = "CLK 31 12 20.xlsx"
sheet = "Sheet 1"
df = pd.read_excel(io=file_name, sheet_name=sheet)
print(df)
print(df.info())
[2823 rows x 4 columns]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2823 entries, 0 to 2822
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Project 2823 non-null object
1 Description 2823 non-null object
2 Start Date 2823 non-null datetime64[ns]
3 Duration (decimal) 2823 non-null float64
dtypes: datetime64[ns](1), float64(1), object(2)
. . . . , , , .
, , . . , - , . - … , ? , , . , -, , -, , . , Nan', .
, . , . , . , .
def remove_duplicates(df):
date = df["Start Date"].to_numpy()
time = df["Duration (decimal)"].to_numpy()
length = len(date)
remove_list = []
for i in range(length - 1):
for j in range(i + 1, length):
if date[i] == date[j]:
time[i] += time[j]
if not j in remove_list:
remove_list.append(j)
df = df.drop(df.index[remove_list])
date = np.delete(date, remove_list)
time = np.delete(time, remove_list)
return df
. 800 .
data = pd.DataFrame()
for project in projects:
descriptions = df[df.Project == project].Description.unique()
for description in descriptions:
df_temp = df[df.Project == project]
df_temp = df_temp[df_temp.Description == description]
new = remove_duplicates(df_temp)
data = data.append(new, ignore_index=True)
print(data.info())
df = data
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2095 entries, 0 to 2094
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Project 2095 non-null object
1 Description 2095 non-null object
2 Start Date 2095 non-null datetime64[ns]
3 Duration (decimal) 2095 non-null float64
dtypes: datetime64[ns](1), float64(1), object(2)
, , . , , , data science . , : b7, b8, m1, m2, m3, games, DS english.
. .
def reindex(data_frame, name='data', start_date='1-1-2019', end_date='12-31-20'):
idx = pd.date_range(start_date, end_date)
dates = pd.Index(pd.to_datetime(data_frame['Start Date'].tolist(), format="%Y%m%d"))
column = data_frame['Duration (decimal)'].tolist()
column = [float(i) for i in column]
series = pd.Series(column, dates)
series.index = pd.DatetimeIndex(series.index)
series = series.reindex(idx, fill_value=0)
data = series.to_frame(name=name)
return data
def plot_kde(data_frame, col_name):
fig = plt.figure(figsize=(14, 7))
ax = fig.add_subplot(111)
sns.distplot(data_frame[col_name], hist=True, ax=ax, bins=20)
fig.savefig('kde.png', dpi=300)
# .
def plot_bar(data_frame, img_name):
fig = plt.figure(figsize=(20, 10))
ax = fig.add_subplot(111)
data_frame.plot.bar(ax=ax, legend=False)
ax.xaxis.set_major_locator(dates.MonthLocator())
ax.xaxis.set_major_formatter(dates.DateFormatter('\n\n\n%b\n'))
plt.tight_layout()
ax.tick_params(labelsize=20)
ax.set_xlabel(" 2020", fontsize=25)
ax.set_ylabel("", fontsize=25)
plt.axhline(y=data_frame.data.mean(), color='r', linestyle='-')
x = list(range(0, data_frame.data.shape[0]))
mean = data_frame.data.mean()
std = data_frame.data.std()
ax.fill_between(x,
(mean - std) if (mean - std) > 0 else 0,
mean + std,
color='silver')
plt.tight_layout()
fig.savefig(img_name, dpi=500)
return ax
# , :)
def stat(data_frame, col_name):
print("Sum: ".ljust(10), "%0.2f" % data_frame[col_name].sum())
print("Mean: ".ljust(10), "%0.2f" % data_frame[col_name].mean())
print("Std: ".ljust(10), "%0.2f" % data_frame[col_name].std())
print("Min: ".ljust(10), data_frame[col_name].min())
print("Max: ".ljust(10), data_frame[col_name].max())
print("Zero: ".ljust(10), (data_frame[col_name] == 0).astype(int).sum())
print("Not zero: ".ljust(10), (data_frame[col_name] != 0).astype(int).sum())
! . Nan-, . , . , , , , .
start_date = '1-1-2020'
end_date = '12-31-2020'
sleep_data = df.loc[df['Description'].isin(['Sleep'])]
sleep_data = reindex(sleep_data,
start_date=start_date,
end_date=end_date)
sleep_data['data'] = sleep_data['data'].replace({0:np.nan})
sleep_arr = sleep_data['data'].to_numpy()
for i in range(1, len(sleep_arr - 1)):
if math.isnan(sleep_arr[i]) and not math.isnan(sleep_arr[i - 1]) and not math.isnan(sleep_arr[i + 1]):
sleep_arr[i] = 0
sleep_arr[np.isnan(sleep_arr)] = np.nanmean(sleep_arr)
sleep_data['data'] = sleep_arr
stat(sleep_data, 'data')
plot_bar(sleep_data, 'sleep.png')
plot_kde(sleep_data, 'data')
, 3224 . , 8784 . , . 0 20 . 16 . , , . , - …
, .
Sum: 3224.42
Mean: 8.81
Std: 3.28
Min: 0.0
Max: 20.0
Zero: 16
Not zero: 350
, , . , , !

, . , , .
152 . 216 , DS, , . , , . , , , , , , . , , - . (- ), . , . , .
Sum: 152.50
Mean: 0.42
Std: 0.89
Min: 0.0
Max: 7.73
Zero: 267
Not zero: 99
( , ). . , , . , . digital , , 47 . , 100, 160. , … osu, .
Sum: 46.60
Mean: 0.13
Std: 0.58
Min: 0.0
Max: 5.8
Zero: 339
Not zero: 27
, … , . 90 , , .
Sum: 90.69
Mean: 0.25
Std: 0.58
Min: 0.0
Max: 3.13
Zero: 282
Not zero: 84
, . , ! , . , . , , ( ). , - 50 , . … … … , , . . . , . , , , … , . , .
Sum: 52.42
Mean: 0.14
Std: 0.45
Min: 0.0
Max: 3.18
Zero: 320
Not zero: 46
- , .
. . , 344 . su , … , - . , - , , - ? , . , .. , (, , ). , . , . , , .
Sum: 344.03
Mean: 0.94
Std: 1.62
Min: 0.0
Max: 12.0
Zero: 165
Not zero: 201
Data science
data science. , . , - . 208 , . , , - , , . Anrew Ng - . , , , , .
Python (18 ), Andrew Ng (32 ), (19 ).
Sum: 208.30
Mean: 0.57
Std: 1.04
Min: 0.0
Max: 6.0
Zero: 254
Not zero: 112
\\
. +10 . , , . , . Breaking Bad. . , , , , .
Sum: 271.24
Mean: 0.74
Std: 1.25
Min: 0.0
Max: 9.5
Zero: 220
Not zero: 146
- , . , 95 . , , . ? ! , ! , .
Sum: 192.04
Mean: 0.52
Std: 0.41
Min: 0.0
Max: 1.0
Zero: 128
Not zero: 238

, ?
- . . . .
def plot_bot(data_frame, start_date, end_date, year, img_name):
descriptions = data_frame.Description.unique()
df = pd.DataFrame(reindex(remove_duplicates(data_frame[data_frame.Description == descriptions[0]]),
name=descriptions[0],
start_date=start_date,
end_date=end_date))
for description in descriptions[1:]:
new = reindex(remove_duplicates(data_frame[data_frame['Description'] == description]),
name=description,
start_date=start_date,
end_date=end_date)
df[description] = new[description].to_numpy()
fig = plt.figure(figsize=(20, 10))
ax = fig.add_subplot(111)
df[descriptions].plot(kind='bar', stacked=True, figsize=(30, 15), ax=ax)
ax.xaxis.set_major_locator(dates.MonthLocator())
ax.xaxis.set_major_formatter(dates.DateFormatter('\n\n\n%b\n'))
ax.tick_params(labelsize=20)
ax.set_xlabel(" " + str(year), fontsize=25)
ax.set_ylabel("", fontsize=25)
ax.legend(fontsize=30)
ax.grid(axis='y')
df['Sum'] = df[list(df.columns)].sum(axis=1)
#ax.set_xlim(243, 395) #m1
#ax.set_xlim(45, 181) #m2
#ax.set_xlim(245, 366) #m3
plt.tight_layout()
fig.savefig(img_name, dpi=300)
return ax, df
: , . , , , . , - . . , . , , . 212 = 116 , 1,8 . , . , . , . . " ?" , . , , : " ???" , , . , , , .
. 66 " ". . , , , 400 , 200 . = = … ", , 400 000 / 24 = 16 666 !!!" ! 13700. 66 208 . , 236 , .
Sum: 390.97
Mean: 1.07
Std: 2.10
Min: 0.0
Max: 10.0
Zero: 252
Not zero: 113
: 212
: 66
: 66
: 212
: 15
: 28
: 25
: 16
: 12
: 13

. , , . , 234 ( B&R ). , 96 . , . , , , 1 20 , . , .
Sum: 234.95
Mean: 0.59
Std: 1.40
Min: 0.0
Max: 12.64
Zero: 296
Not zero: 99
: 1.22
: 62
: 172
: 34
: 13
: 56
: 52
: 18
: 15
: 28

. . , . . 165 . . . 152 . . , 12 . , .
Sum: 165.84
Mean: 0.45
Std: 1.21
Min: 0.0
Max: 7.97
Zero: 301
Not zero: 65
: 0.92
: 12
: 153
: 29
: 7
: 48
: 12
: 18
: 40
: 8

. 58 , 120. , . , .
Sum: 58.60
Mean: 0.16
Std: 0.58
Min: 0.0
Max: 4.5
Zero: 327
Not zero: 39
: 15
: 43
: 1
: 6
: 0
: 5
: 24
: 4

. , -, . , .
: 787
: 650
: 492

2020 .
Time, h Time, % Time per day
Nan 3910 44.5 10.7
Sleep 3224 36.7 8.8
Games 344 3.9 0.9
Study 295 3.4 0.8
Watching films 271 3.1 0.7
DS 208 2.4 0.6
Walks 192 2.2 0.5
Reading books 152 1.7 0.4
English 90 1.0 0.2
Japanese 52 0.6 0.1
Drawing 46 0.5 0.1
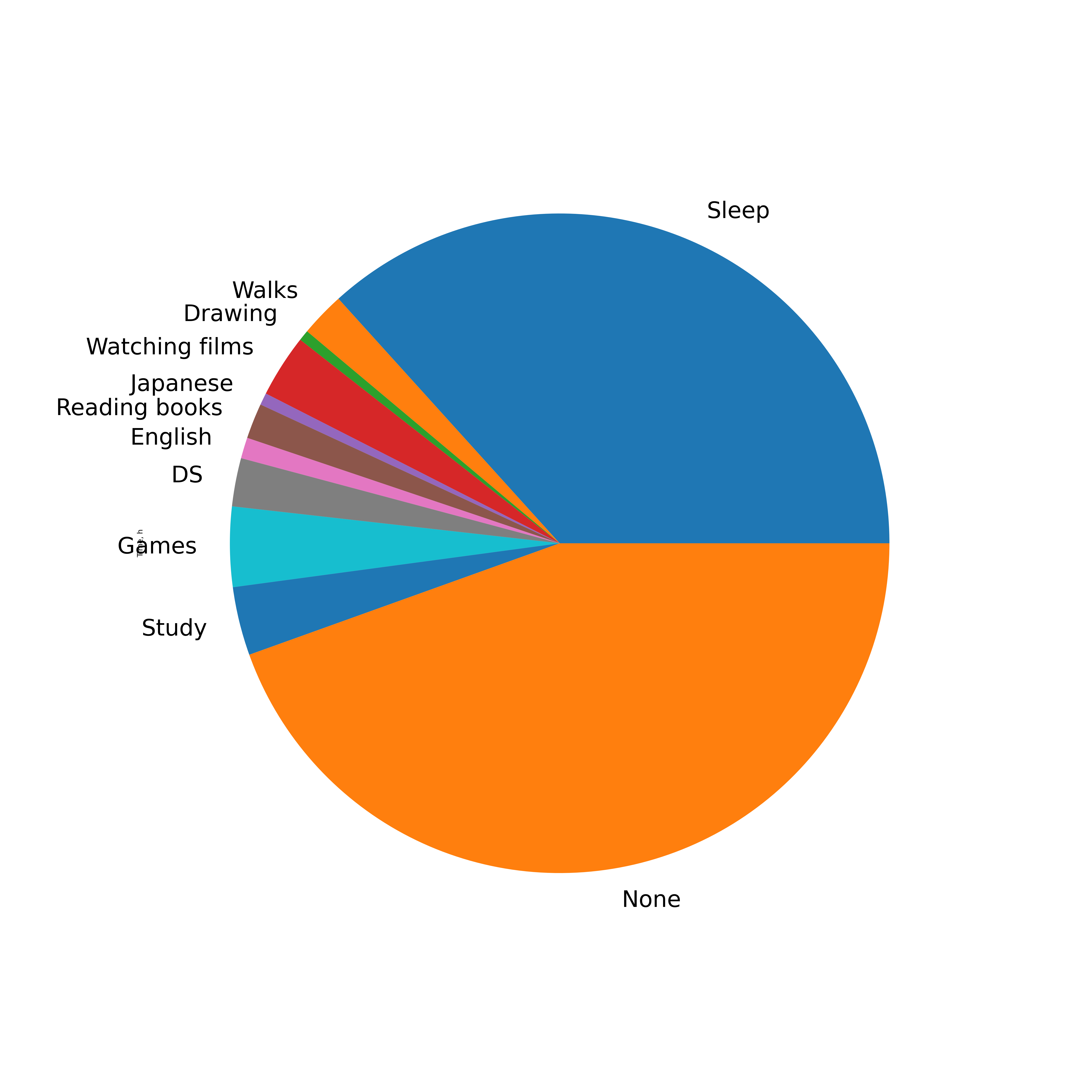
, . , . , , . , , .
, . 235 , 96 . , ! 1 13 , 2 . ? . , - . , , - . 165 152 . 55 , 1 22 . .
, . , , . , , , - , . , ( ), , ( ), . , , , . , !
P.S.
, . , , "". . , . ... , .
? : . , .
? . - , Data Science. , - , : ", ". , , . , 1089 , LSTM. , 400 - . . , 2020- , . , . , ?! , , , .. , .
, . , . . Python 420 , , - 18 . , . , - . , )
P.P.S.
. , , . , . !