私たちは長い間、Apache Kafkaをデータウェアハウスとして使用するというトピックに興味を持っていました。これは、たとえばここで、理論的な観点から検討されてい ます。イベントを処理および再現するためのデータベースとしてのKafkaの型破りな使用について説明している、Twitterブログ(オリジナル-2020年12月)の資料の翻訳に注目することは、さらに興味深いことです。この記事がおもしろく、Kafkaを使用する際の新鮮な考えと解決策を提供することを願っています 。
前書き
開発者がTwitterAPIを介して公開Twitterデータを消費する場合、信頼性、速度、および安定性に依存します。そのため、しばらく前に、TwitterはAccount ActivityAPI用のAccountActivity Replay APIを リリースし 、開発者がシステムの安定性を確保しやすくしました。 Account Activity Replay APIは、開発者が最大5日経過したイベントを取得できるようにするデータ回復ツールです。このAPIは、リアルタイムで配信しようとしたときに発生したサーバークラッシュなど、さまざまな理由で配信されなかったイベントを回復します。
Twitterのエンジニアは、開発者に好評のAPIを作成するだけでなく、次のことにも取り組んできました。
- エンジニアの生産性を向上させます。
- システムの保守を容易にします。特に、開発者、SREエンジニア、およびシステムを扱う他のすべての人のコンテキスト切り替えの必要性を最小限に抑えるため。
このため、APIに依存するリプレイシステムの作成に取り組む際には、アカウントアクティビティAPIの基盤となる既存のリアルタイム動作システムをベースにすることにしました。このようにして、既存の開発を再利用し、コンテキストの切り替えとトレーニングを最小限に抑えることができました。これは、説明されている作業のために完全に新しいシステムが作成された場合にはるかに重要になります。
リアルタイムソリューションは、発行-サブスクライブアーキテクチャに基づいています。この目的のために、タスクを考慮し、それが読み取られる情報ストレージのレベルを作成することで、有名なストリーミングテクノロジーであるApacheKafkaを再考するというアイデアが生まれました。
環境
リアルタイムで発生するイベントは、2つのデータセンターで生成されます。これらのイベントがトリガーされると、冗長性のために2つのデータセンター間で相互複製される公開/サブスクライブトピックに書き込まれます。
すべてのイベントを配信する必要はないため、すべてのイベントは、関連トピックのイベントを消費する内部アプリケーションによってフィルタリングされ、キーと値のストア内の一連のルールと照合され、パブリックAPIを介して特定の開発者にイベントを配信するかどうかが決定されます。イベントはWebhookを介して配信され、各WebhookURLは一意のIDで識別される開発者に属します。
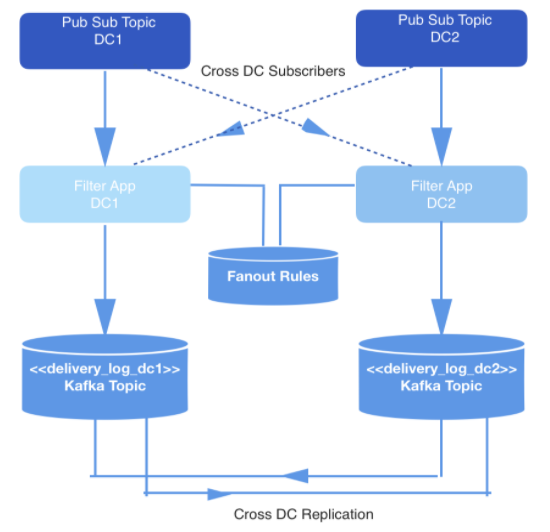
図:1:データ生成パイプライン
ストレージとセグメンテーション
通常、このようなデータウェアハウスを必要とする再生システムを構築する場合、HadoopとHDFSに基づくアーキテクチャが選択されます。この場合、逆に、2つの理由からApacheKafkaが選択されました。
- リアルタイムで作業するためのシステムは、Kafkaデバイスに有機的な発行-サブスクライブの原則に基づいていました
- 再生システムに保存する必要のあるイベントの量は、ペタバイト単位ではありません。データは数日以内に保存されます。また、HadoopのMapReduceジョブを処理することは、Kafkaでデータを消費するよりも費用がかかり、時間がかかり、最初のオプションは開発者の期待に応えません。
この場合、各開発者に配信する必要のあるイベントがKafkaに確実に保存されるように、主な負荷はリアルタイムのデータ再生パイプラインにかかります。トピックをKafkadelivery_logと呼びましょう。データセンターごとにそのようなトピックが1つあります。これらのトピックは冗長性のために相互複製されているため、単一のデータセンターから複製要求を発行できます。この方法で保存されたイベントは、配信前に重複排除されます。
このKafkaトピックでは、デフォルトのセマンティックシャーディングを使用して多くのパーティションを作成します。したがって、パーティションは開発者のwebhookIdハッシュに対応し、このIDは各エントリのキーとして機能します。静的シャーディングを使用することになっていたが、一部の開発者がアクティビティの過程で他のパーティションよりも多くのイベントを生成すると、1つのパーティションに他のパーティションよりも多くのデータが含まれるリスクが高まるため、最終的には放棄されました。代わりに、データを分散するために固定数のパーティションが選択され、パーティション化戦略はデフォルトのままにされました。これにより、パーティションが不均衡になるリスクが軽減され、Kafkaトピックのすべてのパーティションを読み取る必要がなくなります。
対照的に、要求が行われたwebhookIdに基づいて、再生サービスは読み取り元の特定のパーティションを決定し、そのパーティションの新しいKafkaコンシューマーを起動します。キーのハッシュとイベントの配布はそれに依存しているため、トピック内のパーティションの数は変わりません。 説明されているタスクの情報のほとんどはコンシューマー側で処理されることがわかっている
ため、ストレージスペースを最小限に抑えるために、情報はスナッピーアルゴリズムを使用して圧縮 されます。さらに、snappyは、Kafkaでサポートされている他の圧縮アルゴリズム(gzipおよび lz4)よりも 高速に 解凍できます。..。
お問い合わせ・処理
このように設計されたシステムでは、APIは再生要求を送信します。検証された各リクエストのペイロードの一部として、webhookIdと、イベントを再生する必要のあるデータの範囲が含まれます。これらのクエリはMySQLに長期間保存され、再生サービスによって取得されるまでキューに入れられます。要求で指定されたデータ範囲は、ディスクからの読み取りを開始するオフセットを決定するために使用されます。
offsetForTimes
オブジェクト関数 は
Consumer
、オフセットを取得するために使用されます。
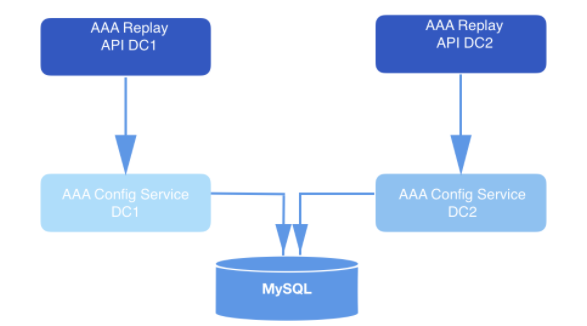
図:2:再生システム。要求を受信し、それを構成サービス(データアクセスレイヤー)に送信して、データベースにさらに長期間保存します。
リプレイサービスインスタンスは、各リプレイリクエストを処理します。インスタンスは、MySQLを使用して相互に調整され、データベースに保存されている次の再生レコードを処理します。各リプレイワーカープロセスは定期的にMySQLをポーリングして、処理するジョブがあるかどうかを確認します。リクエストは州から州へと移動します。処理のためにピックアップされていないリクエストは、OPEN状態です。デキューされたばかりのリクエストはSTARTED状態です。現在処理中のリクエストは進行中の状態です。すべての遷移が実行された要求は、COMPLETED状態です。再生ワークフローは、まだ処理を開始していない(つまり、OPEN状態の)要求のみを取得します。
定期的に、ワーカープロセスが処理のためにキューから要求を削除した後、それはMySQLテーブルにタップされ、タイムスタンプを残して、再生ジョブがまだ処理中であることを示します。複製ワークフローインスタンスが要求の処理を完了する前に停止した場合、これらのジョブが再開されます。その結果、再生プロセスは、OPEN状態の要求をデキューするだけでなく、STARTEDまたはONGOING状態に転送されたが、指定された分数後にデータベースでフィードバックを受信しなかった要求も取得します。
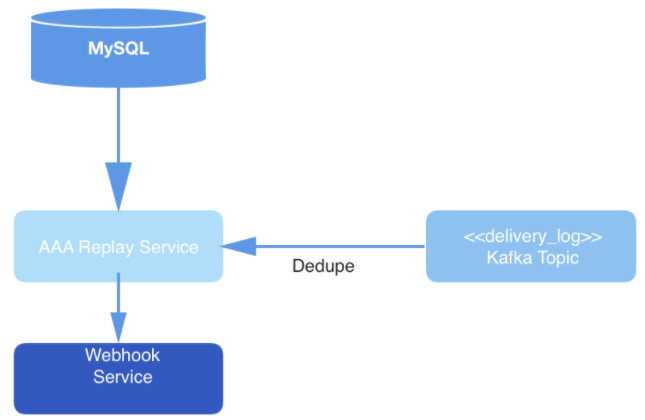
図: 3:データ配信レイヤー:再生サービスは、新しいリクエスト処理ジョブについてMySQLをポーリングし、Kafkaトピックからのリクエストを消費し、Webhookサービスを介してイベントを配信します。
最終的に、トピックのイベントは、読み取られる過程で重複排除され、特定のユーザーのWebhookのURLに公開されます。重複排除は、読み取りイベントのキャッシュを維持することによって実行され、その後ハッシュされます。すでにハッシュに含まれているものと同一のハッシュを持つイベントが発生した場合、そのイベントは配信されません。
一般的に、このカフカの使用は伝統的ではありません。ただし、説明したシステムのフレームワーク内で、Kafkaはデータストアとして正常に機能し、APIの作業に参加します。これにより、イベントを回復する際のデータへのアクセスのしやすさと使いやすさの両方に貢献します。リアルタイム操作のためのシステムの強みは、そのようなソリューションのフレームワークで役に立ちました。さらに、このようなシステムでのデータ回復率は、開発者の期待を完全に満たしています。