NLPなどの一部の領域では、主力製品はTransformerであり、これには大量のGPUメモリが必要です。現実的なモデルはメモリに収まりません。シャードと呼ばれる最後の方法[lit. 「セグメント化された」]は、人類を1兆個のパラメーターに近づける方法を開発したMicrosoftのゼロペーパーで紹介されました 。
特に機械学習に関する新しいコースの開始のために 、Shardedに関する記事を共有して、今日PyTorchで使用して、2倍のメモリとわずか数分でモデルをトレーニングする方法を示します。PyTorchのこの機能は、FairScale Facebook AIResearchとPyTorchLightningチームのコラボレーションを通じて利用できるように なり ました。

この記事は誰のためのものですか?
この記事は、PyTorchを使用してモデルをトレーニングするすべての人を対象としています。Shardedは、トレーニングするモデルに関係なく、NLP(トランスフォーマー)、ビジュアル(SIMCL、swav、Resnet)、さらには音声モデルなど、どのモデルでも機能します。これは、すべてのモデルタイプでShardedを使用して確認できるパフォーマンスの向上のスナップショットです。
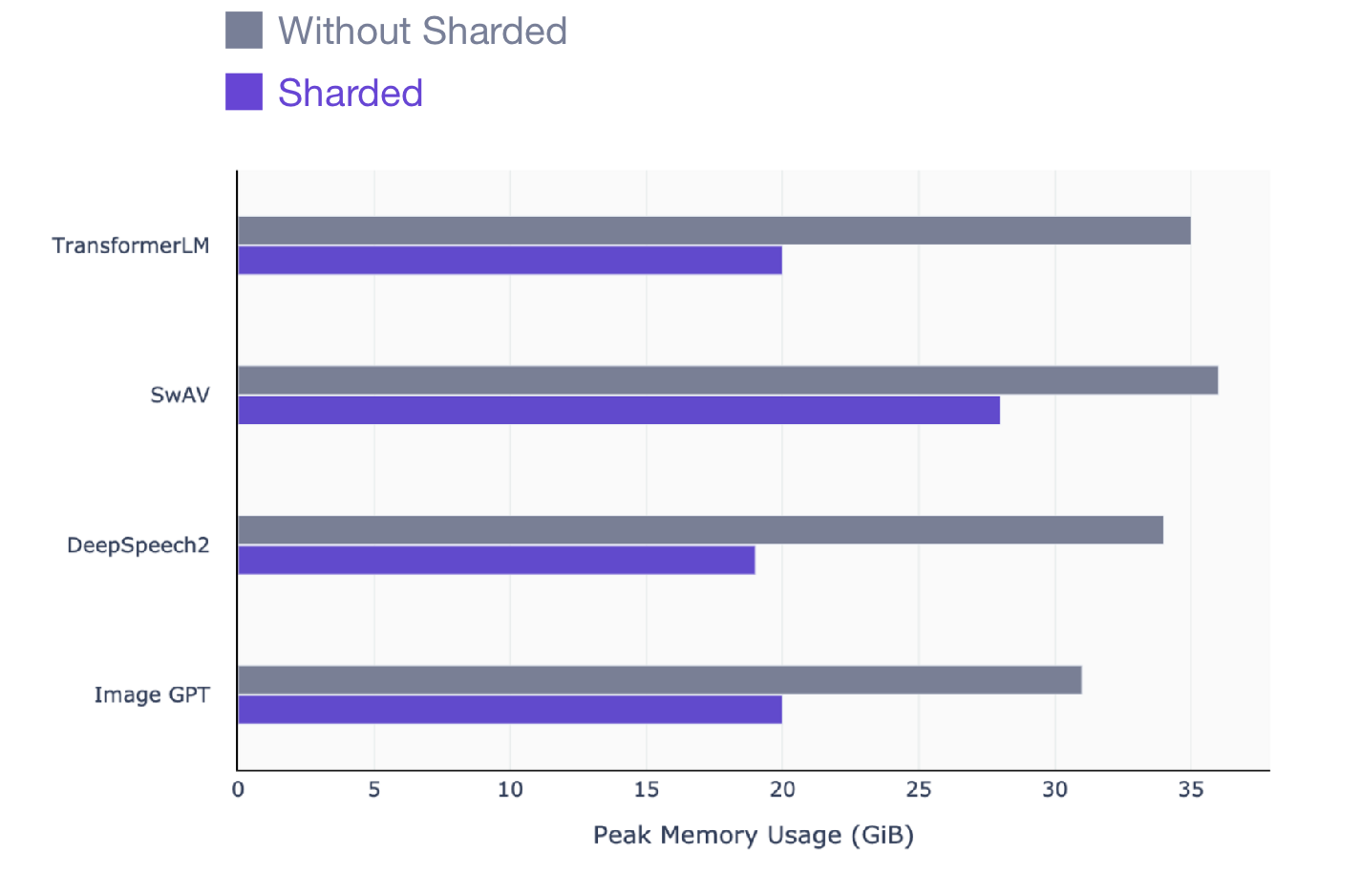
SwAVは、コンピュータービジョンにおける最先端のデータ駆動型学習方法です。
DeepSpeech2は、音声モデルの最新の手法です。
Image GPTは、ビジュアルモデルの高度な方法です。
Transformerは、高度な自然言語処理技術です。
PyTorchでShardedを使用する方法
Shardedがどのように機能するかについての直感的な説明を読む時間があまりない人のために、PyTorchコードでShardedを使用する方法をすぐに説明します。ただし、Shardedがどのように機能するかを理解するには、記事の最後を読むことをお勧めします。
Shardedは、複数のGPUで使用して、利用可能な利点を最大限に活用するように設計されています。ただし、複数のGPUでのトレーニングは、セットアップが困難で非常に困難な場合があります。
Shardedを使用してコードを課金する最も簡単な方法は、モデルをPyTorch Lightningに変換すること です(これは単なるリファクタリングです)。これは、PyTorchコードをLightningに変換する方法を示す4分間のビデオです。
それが済んだら、8つのGPUでShardedを有効にするのは、単一のフラグを変更するのと同じくらい簡単です。コードを変更する必要はありません。

モデルが別のディープラーニングライブラリからのものである場合でも、Lightning(NVIDIA Nemo、fast.ai、Hugging Face)で機能します。モデルをLightningModuleにインポートして、学習を開始するだけです。
from argparse import ArgumentParser
import torch
import torch.nn as nn
import pytorch_lightning as pl
from pytorch_lightning.metrics.functional import accuracy
from transformers import BertModel
class LitBertClassifier(pl.LightningModule):
def __init__(self, n_classes, pretrained_model_name='bert-base-uncased'):
super().__init__()
self.save_hyperparameters()
self.bert = BertModel.from_pretrained(pretrained_model_name)
self.drop = nn.Dropout(p=0.3)
self.out = nn.Linear(self.bert.config.hidden_size, n_classes)
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, input_ids, attention_mask):
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
return_dict=False
)
pooled_output = outputs[1]
output = self.drop(pooled_output)
return self.out(output)
def training_step(self, batch, batch_idx):
loss, acc = self._shared_step(batch, batch_idx)
self.log("acc", acc)
return loss
def validation_step(self, batch, batch_idx):
_, acc = self._shared_step(batch, batch_idx)
self.log("val_acc", acc)
def _shared_step(self, batch, batch_idx):
input_ids = batch["input_ids"]
attention_mask = batch["attention_mask"]
targets = batch["targets"]
outputs = self.forward(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
loss = self.loss_fn(outputs, targets)
acc = accuracy(preds, targets)
return loss, acc
def configure_optimizers(self):
return torch.optim.AdamW(self.parameters(), lr=2e-5)
if __name__ == '__main__':
# TODO: add your own dataset
train_dataloader = ...
val_dataloader = ...
bert = LitBertClassifier()
trainer = pl.Trainer(gpus=8, plugins='ddp_sharded')
trainer.fit(bert, train_dataloader)
シャードがどのように機能するかについての直感的な説明
多数のGPUで効果的にトレーニングするために、いくつかのアプローチが使用されます。1つのアプローチ(DP)では、各パッケージはGPU間で分割されます。これは、パッケージの各部分が異なるGPUに送信され、モデルがそれぞれに複数回コピーされるDPの図です。

DPトレーニング
ただし、モデルの重みがデバイスを介して送信されるため、このアプローチは不適切です。さらに、最初のGPUはすべてのオプティマイザー状態をサポートします。たとえば、Adamは、モデルの重みの完全なコピーを追加で保持します。
別の手法(並列データ分散、DDP)では、各GPUがデータのサブセットでトレーニングされ、勾配がGPU間で同期されます。この方法は、多くのマシン(ノード)でも機能します。この図では、各GPUがデータのサブセットを受け取り、すべてのGPUに対して同じモデルの重みを初期化します。次に、バックパスの後、すべてのグラデーションが同期されて更新されます。
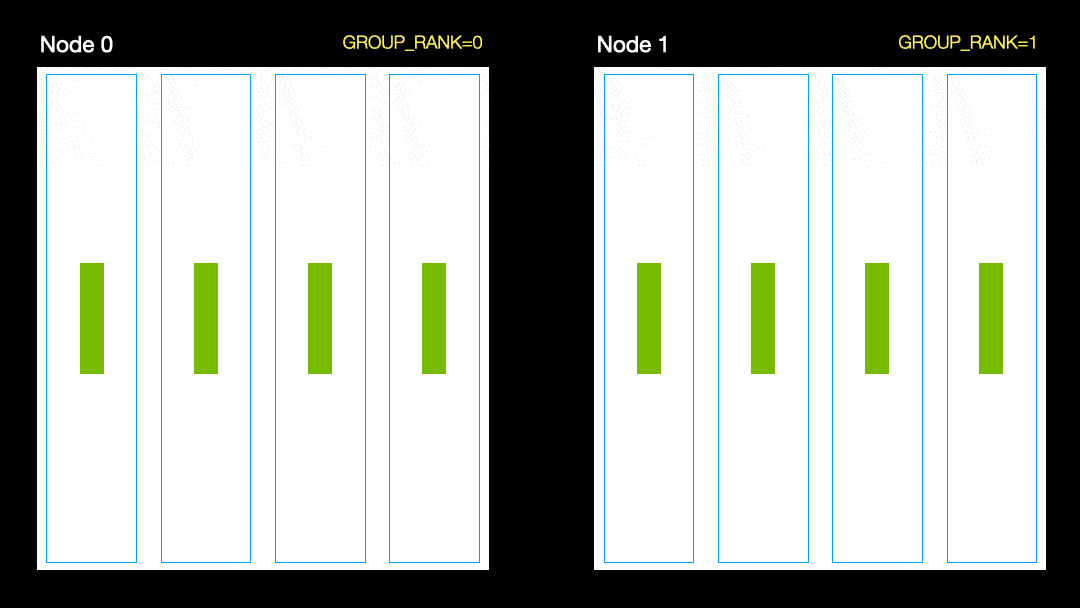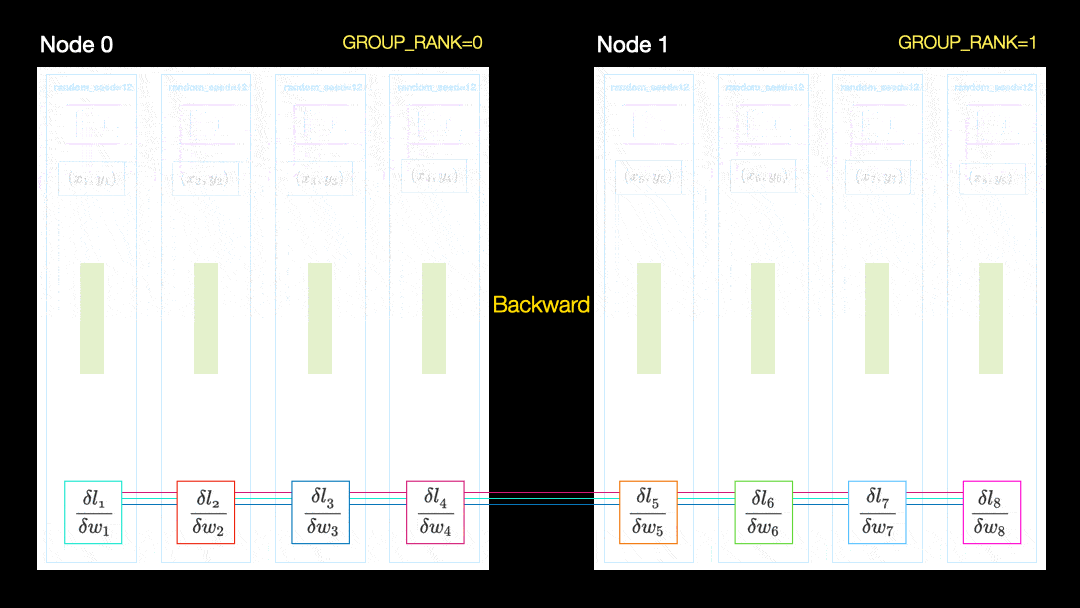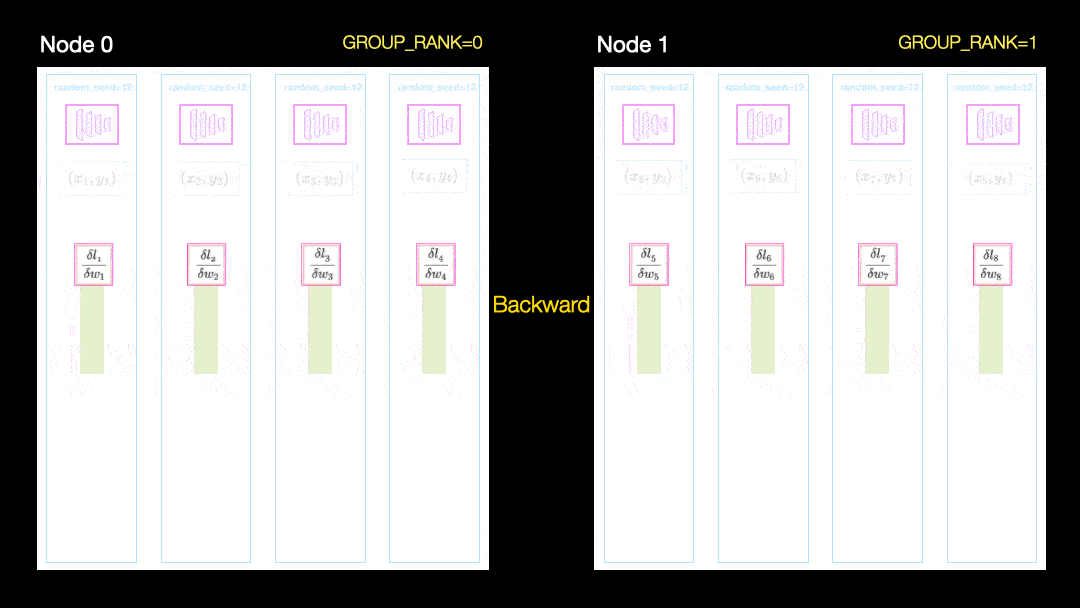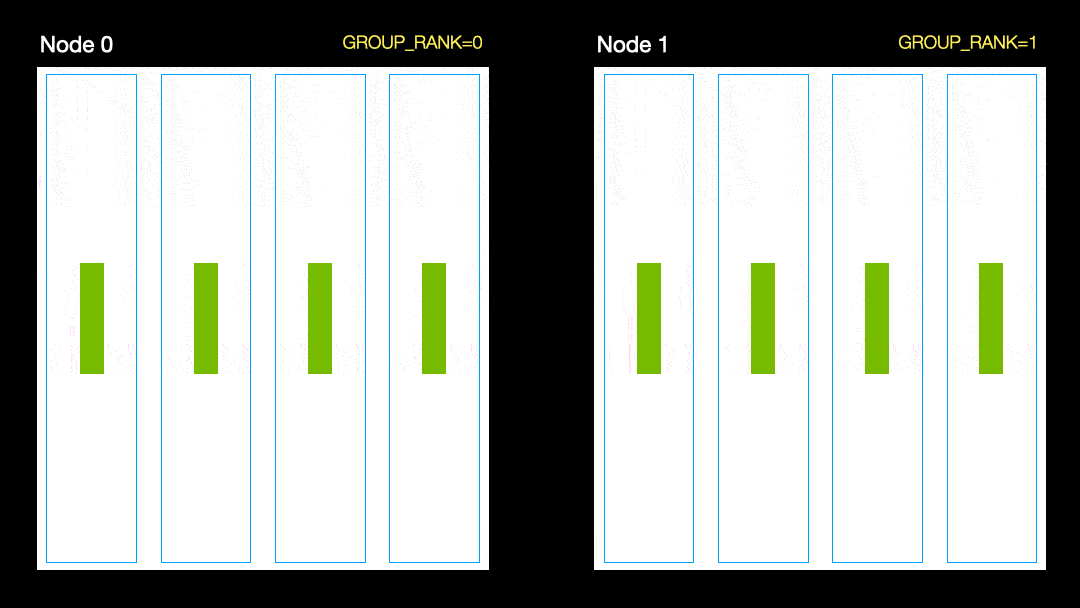
並列データ分散
ただし、この方法にはまだ問題があります。つまり、各GPUは、すべてのオプティマイザー状態(モデルパラメーターの約2〜3倍)のコピーと、すべての順方向および逆方向のアクティブ化を維持する必要があります。
Shardedはこの冗長性を取り除きます。これはDDPと同じように機能しますが、すべてのオーバーヘッド(勾配、オプティマイザーの状態など)がパラメーター全体のごく一部に対してのみ計算されるため、同じ勾配と状態を格納する冗長性が排除されます。すべてのGPUのオプティマイザ。つまり、各GPUは、アクティベーション、オプティマイザパラメータ、および勾配計算のサブセットのみを格納します。
ある種の分散モードを使用する

PyTorch Lightningでは、配布モードの切り替えは簡単です。
ご覧のとおり、これらの最適化アプローチのいずれでも、分散学習を最大限に活用する方法はたくさんあります。
幸いなことに、これらのモードはすべて、コードを変更することなくPyTorchLightningで使用できます。それらのいずれかを試して、必要に応じて特定のモデルに合わせて調整できます。
ない方法の1つは、並列モデルです。ただし、この方法はセグメント化されたトレーニングよりも効果がはるかに低いことが証明されているため、注意が必要です。注意して使用する必要があります。場合によっては機能することもありますが、一般的にはシャーディングを使用するのが最適です。
Lightningを使用する利点は、AI研究の最新の進歩に遅れをとることがないことです。オープンソースチームとコミュニティは、Lightningを通じてLightningと最新の進歩を共有することに取り組んでいます。
