- 使い慣れた言語でコードを記述できますが、同時に別の言語にのみ存在する関数を使用できます。
- 別の言語でプログラミングしている同僚との直接コラボレーションを可能にします。
- それは2つの言語で作業することを可能にし、最終的にそれらに堪能になることを学びます。

私たちは何が必要なのか
動作するには、次のコンポーネントが必要です。
- もちろん、RとPython。
- IDE RStudio(これは他のIDEでも実行できますが、RStudioの方が簡単です)。
- お気に入りのPython環境マネージャー(ここではcondaを使用しています)。
- パッケージ
rmarkdown
とreticulate
Rにインストールされます。
R Markdownドキュメントを作成するときは、RStudioで作業しますが、同時にRとPythonで作成されたコードスニペット間を移動します。簡単な例をいくつか紹介します。
Python環境のセットアップ
Pythonプログラミングに精通している場合、Pythonで行われるすべての作業は、その作業に必要なすべてのパッケージを含む特定の環境を参照する必要があることをご存知でしょう。Pythonでパッケージを管理する方法はたくさんありますが、最も人気のある2つはvirtualenvとcondaです。ここでは、condaを使用しており、Python環境マネージャーとしてインストールされていることを前提としています。
必要に応じて、Rの網状パッケージを使用してRコマンドラインからconda環境をセットアップできますが(などの機能を使用
conda_create()
)、通常のPythonプログラマーとして、環境を手動でセットアップすることを好みます。
名前の付いたconda環境を作成し、それに
r_and_python
インストールして
pandas
、
statsmodels
..。したがって、ターミナルのコマンドは次のとおりです。
conda create -name r_and_python conda activate r_and_python conda install pandas conda install statsmodels
pandas
、
statsmodels
(およびその他の必要なパッケージ)をインストールする と 、環境のセットアップが完了します。次に、ターミナルでconda infoを実行し、環境へのパスを選択します。次のステップで必要になります。
RおよびPythonで動作するようにRプロジェクトを設定する
RStudioでRプロジェクトを開始しますが、同じプロジェクトでPythonを実行できるようにしたいと考えています。 Pythonコードが
RETICULATE_PYTHON
目的の環境で実行されるようにするには、その環境で実行可能なPythonのシステム環境変数を設定する必要があり ます。これは、前のセクションで選択したパスになり、その後に
/bin/python3
。が続き ます。
この変数がプロジェクトに永続的に設定されていることを確認する最良の方法は、プロジェクトに名前付きテキストファイルを作成し、
.Rprofile
この行をプロジェクト に追加することです。
Sys.setenv(RETICULATE_PYTHON=”path_to_environment/bin/python3")
pathtoenvironmentを、前のセクションで選択したパスに置き換えます。ファイル
.Rprofile
を保存し てRセッションを再起動します。セッションまたはプロジェクトを再起動するたびに起動し
.Rprofile
、Python環境をセットアップします。これをテストしたい場合は、Sys.getenv( "RETICULATE_PYTHON")行を実行できます。
コードの記述-最初の例
これで、プロジェクトにRマークダウンドキュメントを設定し、
.Rmd
2つの異なる言語でコードを記述できます。まず、最初のコードに網状ライブラリをロードする必要があります。
```{r} library(reticulate) ```
これで、Pythonコードを記述したい場合は、通常のバッククォートでラップできますが、でPythonコードスニペットとしてマークし
{python}
、Rで記述したい場合は、を使用します
{r}
。
最初の例では、学生のテストスコアのデータセットでPythonモデルを実行するとします。
```{python} import pandas as pd import statsmodels.api as sm import statsmodels.formula.api as smf # obtain ugtests data url = “http://peopleanalytics-regression-book.org/data/ugtests.csv" ugtests = pd.read_csv(url) # define model model = smf.ols(formula = “Final ~ Yr3 + Yr2 + Yr1”, data = ugtests) # fit model fitted_model = model.fit() # see results summary model_summary = fitted_model.summary() print(model_summary) ```
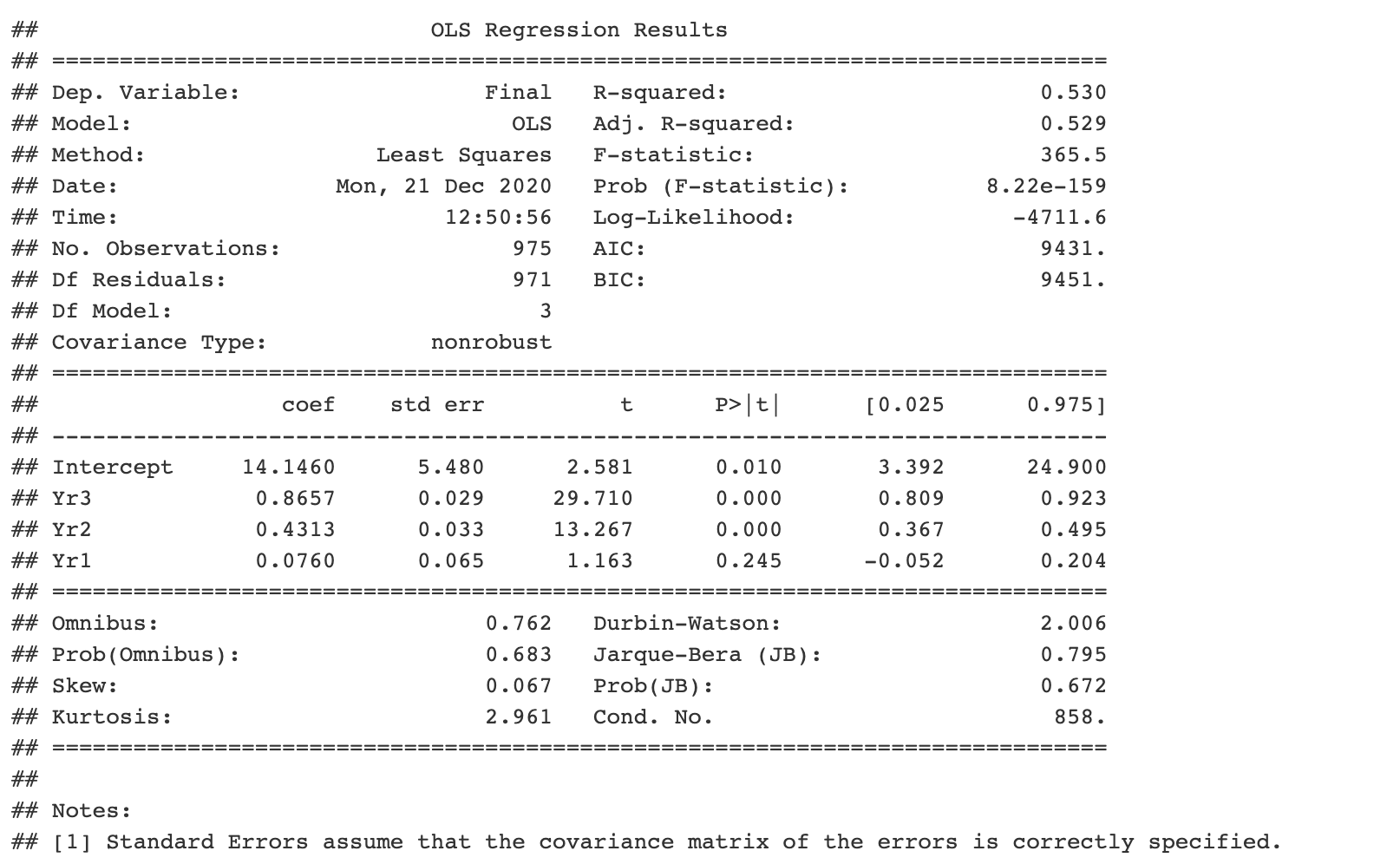
それは素晴らしいことですが、もっと緊急の理由で仕事を辞めて、同僚のRプログラマーに渡さなければならなかったとしましょう。モデルを診断できることを望んでいました。
恐れることはありません。pyと呼ばれる一般的なリストで作成したすべてのpythonオブジェクトにアクセスできます。したがって、RブロックがRマークダウンドキュメント内に作成されている場合、同僚はモデルパラメータにアクセスできます。
```{r} py$fitted_model$params ```

または最初のいくつかの残り物:
```{r} py$fitted_model$resid[1:5] ```

これで、クォンタイル-クォンタイルモデルの残差をプロットするなど、モデルに対していくつかの診断を簡単に実行できます。
```{r} qqnorm(py$fitted_model$resid) ```
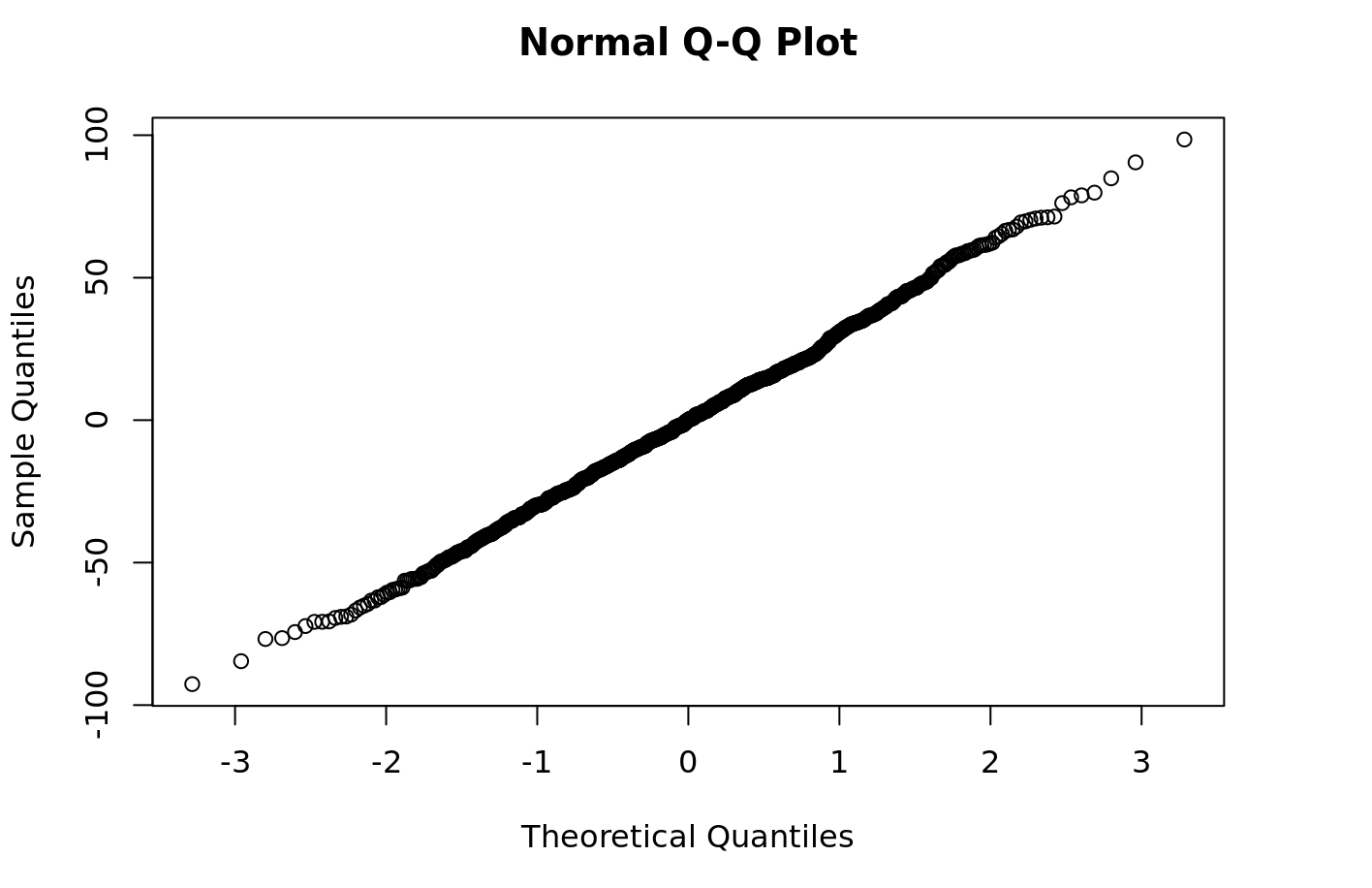
コードの記述-2番目の例
いくつかのPython日付データを解析し、すべてのデータを含むpandasデータフレームを作成しました。簡単にするために、データをロードして見てみましょう。
```{python} import pandas as pd url = “http://peopleanalytics-regression-book.org/data/speed_dating.csv" speed_dating = pd.read_csv(url) print(speed_dating.head()) ```

これで、Pythonで単純なロジスティック回帰モデルを実行して、decソリューションを他のいくつかの変数に関連付けようとしました。ただし、このデータは実際には階層的であり、同じ個々のiidに複数の知人がいる可能性があることを理解しています。
したがって、混合効果ロジスティック回帰モデルを実行する必要があることはわかっていますが、それを実行するPythonプログラムは見つかりません。
繰り返しになりますが、恐れることはありません。プロジェクトを同僚に送信すると、彼はRでソリューションを作成します。
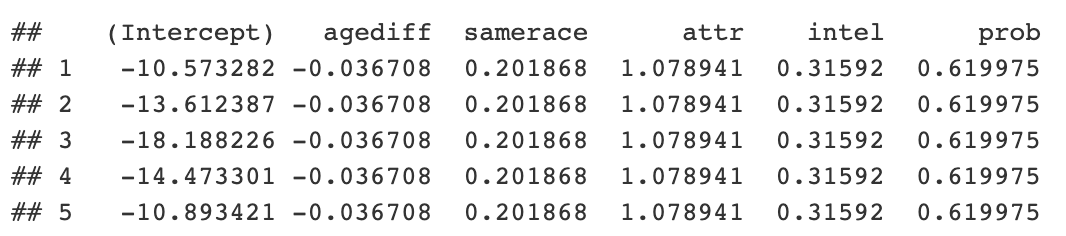
```{r} library(lme4) speed_dating <- py$speed_dating iid_intercept_model <- lme4:::glmer(dec ~ agediff + samerace + attr + intel + prob + (1 | iid), data = speed_dating, family = “binomial”) coefficients <- coef(iid_intercept_model)$iid ```
これで、コードを取得してオッズを確認できます。汎用rオブジェクト内のPythonRオブジェクトにアクセスすることもできます。
```{python} coefs = r.coefficients print(coefs.head()) ```
これらの2つの例は、同じRマークダウンドキュメント内でRとPythonの間をシームレスにナビゲートする方法を示しています。したがって、次にクロスランゲージプロジェクトでの作業を検討するときは、RMarkdownですべてのステップを実行することを検討してください。これにより、2つの言語を切り替える手間を大幅に省くことができ、すべての作業を継続的な説明として1か所にまとめることができます。
RとPythonのスニペットとそれらの間を移動するオブジェクトを含む、言語統合を中心に構築された完成したRMarkdownドキュメントをここに投稿でき ます。ソースコードを含むGithubリポジトリは こちらです。
ドキュメントのサンプルデータは私のものです People Analytics Regression ModelingReference。
