
GPUの金属板を加熱しましょう
Python自体がスピードで輝くわけではないことは誰もが知っています。私の意見では、この言語は読みやすさにおいて優れていますが、そのアプリケーションの主なニッチは、データの入力/出力をほとんどの時間待つことです。慣例により、RustまたはCで超高性能のコードを書くことができますが、99%の時間はただ待つだけです。
ただし、Pythonは高レベルの構文の接着剤としても優れています。この場合、そのゆったりと解釈された部分は、コンパイルされたプログラミング言語で書かれた高速コードを呼び出します。通常、これにはNumPyなどの従来のライブラリが使用されます。
しかし、もう少し進んで、CUDAで計算を並列化し、C ++、stdpar、およびNvidiaのnvc ++コンパイラの奇妙で機能するハイブリッドを使用してみます。さて、同時に、パフォーマンスを評価してみましょう。番号の並べ替えと、金属板の加熱を計算するために使用するJacobiメソッドの2つの問題を取り上げましょう。
PythonからC ++を呼び出す
並べ替えコードは次のようになります。
# distutils: language=c++
from libcpp.algorithm cimport sort
def cppsort(int[:] x):
sort(&x[0], &x[-1] + 1)
最初の行では、CythonがデフォルトのCではなくC ++を使用する必要があることを明示的に示しています。2番目の行では、C ++から並べ替え関数をインポートし、ロジック自体が続きます。コードをcppsort.pyxファイルに配置します。拡張機能は、Cythonの用語でコンパイルまたはcythonizeを実行するため、通常のpyとは異なることに注意してください。
コンパイルは手動で行うことも、setup.pyに含めることもできます。ここでは、環境の準備について詳しく説明しています。
setup.pyでは、次のようになります。
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("cppsort.pyx")
)
しかし、これはコマンドラインで実行できます。
cythonize -i cppsort.pyx
内部では、次のようなことが起こります。

- CythonはpythonコードをC ++に変換し、有効なcppsort.cppを生成します。
- C ++コンパイラ(この場合はg ++)は、C ++コードをPython拡張モジュールにコンパイルします
- Python拡張モジュールは、通常のPythonモジュールとしてコードにインポートされます。
コンパイル後、インポートしてすぐに並べ替えをテストできます。
from cppsort import cppsort
import numpy as np
x = np.array([4, 3, 2, 1], dtype="int32")
print(x)
cppsort(x)
print(x)
配列[4、3、2、1]は、C ++ std :: sortを使用して[1、2、3、4]に正常にソートされます。
GPUに行きましょう。
C ++標準ライブラリアルゴリズムは、並列実行ポリシー引数を使用して呼び出すことができます 。この引数は、アルゴリズムを並列プロセスに分割することをコンパイラーに通知します。
そうは言っても、C ++にはこのポリシーに対していくつかのオプションがあります。
- std ::実行:: seq:順次実行。並列処理は禁止されています。
- std ::実行:: unseq:呼び出し元スレッド内のベクトル化された実行。
- std ::実行:: par:1つ以上のスレッドでの並列実行。
- std ::実行:: par_unseq:1つ以上のスレッドでの並列実行。各ストリームは、可能な限りベクトル化されます。
この場合、あなた自身がレースの状態とデッドロックを監視する必要があります。標準のg ++コンパイラは、CPUコア間で計算を分散しようとします。ただし、Nvidiaから独自のコンパイラ(nvc ++)を取得して、「-stdpar」オプションを指定することはできます。stdparは、GPUで並列コードを実行するNvidiaのC ++標準並列処理です。
GPUはNumPy内にあるアレイにアクセスできないため、アレイのローカルコピーを作成する必要性を考慮して、コードを書き直してみましょう。
from libcpp.algorithm cimport sort, copy_n
from libcpp.vector cimport vector
from libcpp.execution cimport par
def cppsort(int[:] x):
cdef vector[int] temp
temp.resize(len(x))
copy_n(&x[0], len(x), temp.begin())
sort(par, temp.begin(), temp.end())
copy_n(temp.begin(), len(x), &x[0])

これを再度コンパイルする必要がありますが、nvc ++を使用します。今回は、通常のsetup.pyを記述して、次のように呼び出します。
CC=nvc++ python setup.py build_ext --inplace
コードにインポートして、次のように呼び出します。
x = np.array([4, 3, 2, 1], dtype="int32")
cppsort(x) # GPU
パフォーマンス
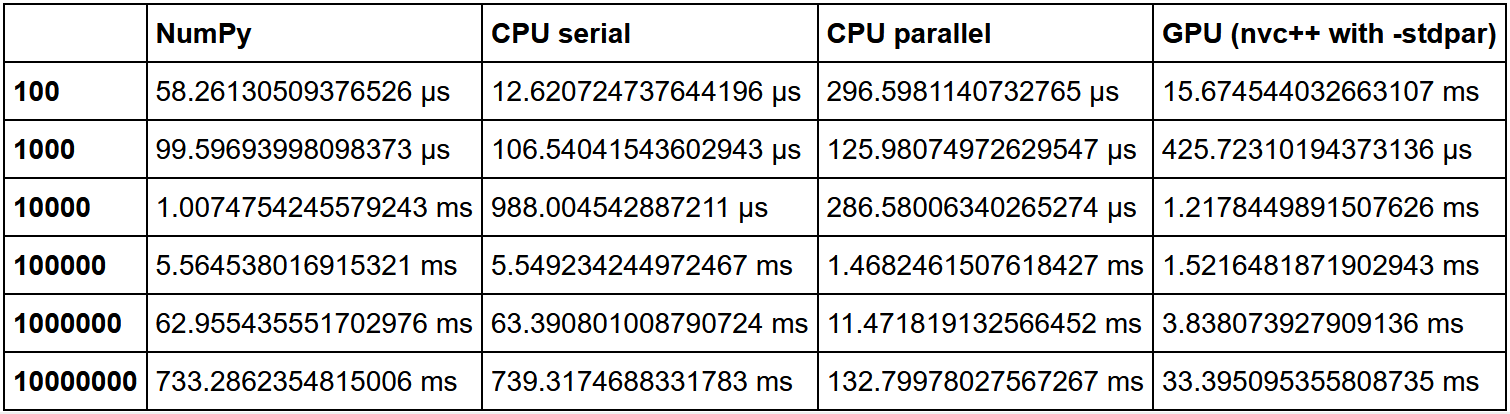
従来、GPUは、同じタイプの軽量コンピューティングが多数ある場合に適しています。重いタスク、単一のGPUタスクは機能しません。さらに、データの量を考慮する価値があります。データが少ない場合は、並列化プロセス、つまりCPUとGPU間のI / Oに大きなオーバーヘッドが発生します。その結果、そのようなコードは、データが非常に少ない場合、ベアCPUで、場合によっては単一コア内でさえ、最も効率的に実行される可能性があります。しかし、大規模なアレイでは、GPUが確実に先行します。 ここでは、並べ替えの優れた比較
があります。 NumPyの速度を単位として、各メソッドの速度増加の多重度を計算しました。
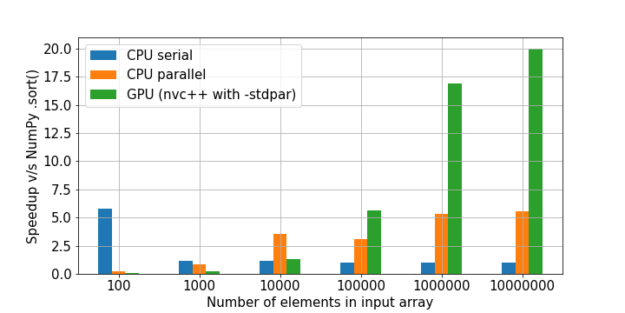
ご覧のとおり、大量のデータでGPUを使用することで得られる利益が増大しているという仮説が確認されています。
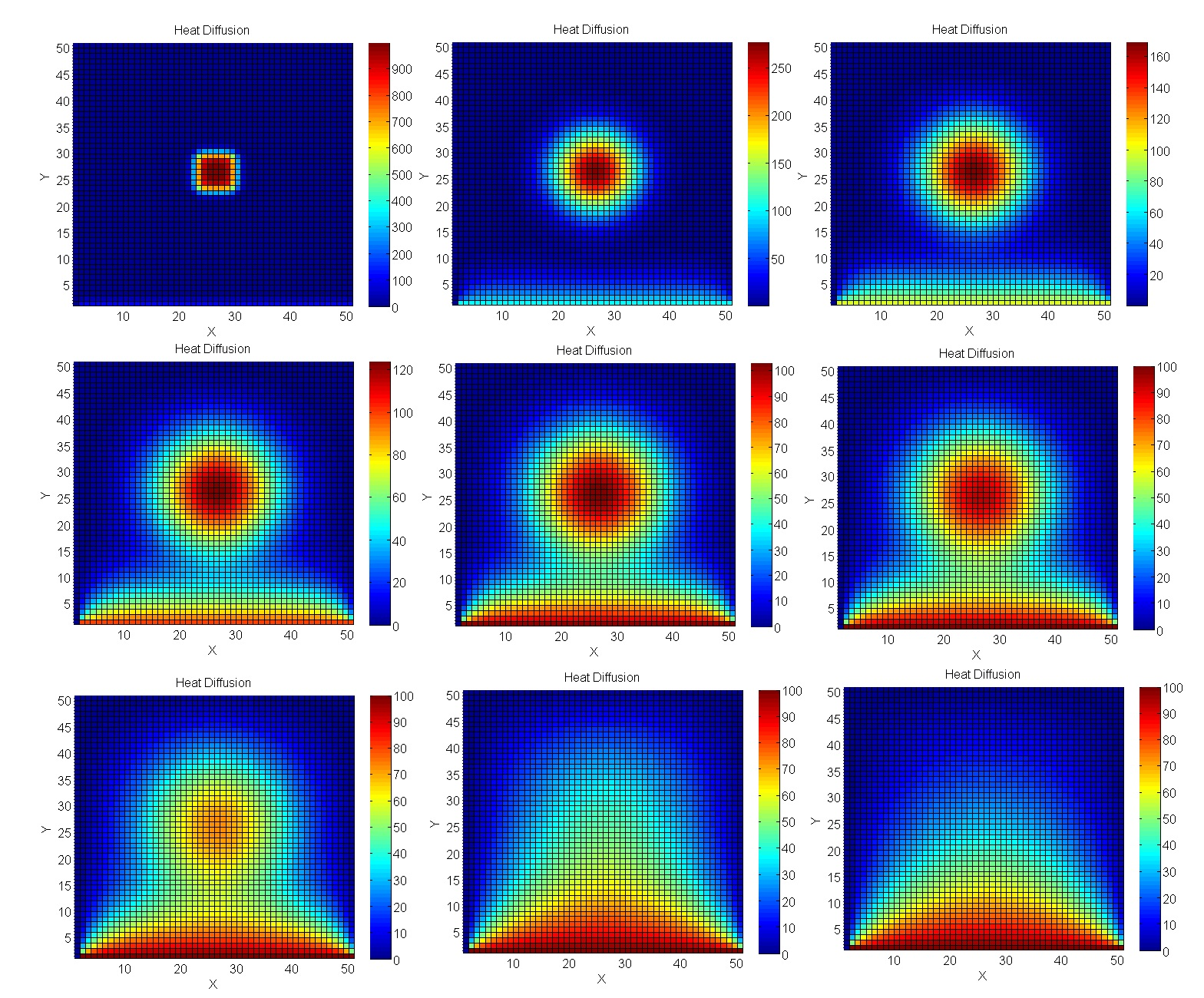
プレートの加熱を計算します
問題を実際のエンジニアリングモデリング、つまりJacobiメソッドを使用した計算に近づけてみましょう。特に、2D空間での温度プロセスの計算に最適です。
シミュレーションコード
"""
simulates heat equation on rectangle returning a heat map at a number of times
boundary and initial conditions are 0, source represents burner on a stove
This program is based on the script FEniCS tutorial demo program: Diffusion of a Gaussian hill.
u'= Laplace(u) + f in a square domain
u = u_D = 0 on the boundary
u = u_0 = 0 at t = 0
u_D = f = stove burner flame
This program succesfully runs in the fenics docker image, see the book Solving PDEs in Python.
to animate: convert -delay 4 -loop 100 heatequation10*.png heatstovelinn.gif
to crop:convert heatstovelinn.gif -coalesce -repage 0x0 -crop 810x810+95+15 +repage heatstovelin.gif
"""
from fenics import *
import time
import matplotlib.pyplot as plt
from matplotlib import cm
# Create mesh and define function space
nx = ny = 100
mesh = RectangleMesh(Point(-2, -2), Point(2, 2), nx, ny)
V = FunctionSpace(mesh, 'P', 1)
# Define boundary, source, initial
def boundary(x, on_boundary):
return on_boundary
bc = DirichletBC(V, Constant(0), boundary)
u_0 = interpolate(Constant(0), V)
f = Expression('exp(-sqrt(pow((a*pow(x[0], 2) + a*pow(x[1], 2)-a*1),2)))', degree=2, a=5) #steep guassian centred on the unit sphere
final_time = 0.035
num_pics = 72
for i in range(num_pics):
T = final_time*(i+1.0)/(num_pics+1) #solve time even space
#T = final_time*1.1**(i-num_pics+1) #solve time log space
num_steps = 30
dt = T / num_steps # time step size
# Define variational problem
u = TrialFunction(V)
v = TestFunction(V)
F = u*v*dx + dt*dot(grad(u), grad(v))*dx - (u_0 + dt*f)*v*dx
a, L = lhs(F), rhs(F)
# Time-stepping
u = Function(V)
t = 0
for n in range(num_steps):
t += dt #step
solve(a == L, u, bc) #solve
u_0.assign(u) #update
#plot solution
plot(u,cmap=cm.hot,vmin=0,vmax=0.07)
plt.axis('off')
plt.savefig('heatequation10%s.png'%(i+10),figsize=(8, 8), dpi=220,bbox_inches='tight', pad_inches=0,transparent=True)
CUDAを使用した後続のコンパイルのために、Cythonで同様のソルバーを作成しましょう。
# distutils: language=c++
# cython: cdivision=True
from libcpp.algorithm cimport swap
from libcpp.vector cimport vector
from libcpp cimport bool, float
from libc.math cimport fabs
from algorithm cimport for_each, any_of, copy
from execution cimport par, seq
cdef cppclass avg:
float *T1
float *T2
int M, N
avg(float* T1, float *T2, int M, int N):
this.T1, this.T2, this.M, this.N = T1, T2, M, N
inline void call "operator()"(int i):
if (i % this.N != 0 and i % this.N != this.N-1):
this.T2[i] = (
this.T1[i-this.N] + this.T1[i+this.N] + this.T1[i-1] + this.T1[i+1]) / 4.0
cdef cppclass converged:
float *T1
float *T2
float max_diff
converged(float* T1, float *T2, float max_diff):
this.T1, this.T2, this.max_diff = T1, T2, max_diff
inline bool call "operator()"(int i):
return fabs(this.T2[i] - this.T1[i]) > this.max_diff
def jacobi_solver(float[:, :] data, float max_diff, int max_iter=10_000):
M, N = data.shape[0], data.shape[1]
cdef vector[float] local
cdef vector[float] temp
local.resize(M*N)
temp.resize(M*N)
cdef vector[int] indices = range(N+1, (M-1)*N-1)
copy(seq, &data[0, 0], &data[-1, -1], local.begin())
copy(par, local.begin(), local.end(), temp.begin())
cdef int iterations = 0
cdef float* T1 = local.data()
cdef float* T2 = temp.data()
keep_going = True
while keep_going and iterations < max_iter:
iterations += 1
for_each(par, indices.begin(), indices.end(), avg(T1, T2, M, N))
keep_going = any_of(par, indices.begin(), indices.end(), converged(T1, T2, max_diff))
swap(T1, T2)
if (T2 == local.data()):
copy(seq, local.begin(), local.end(), &data[0, 0])
else:
copy(seq, temp.begin(), temp.end(), &data[0, 0])
return iterations
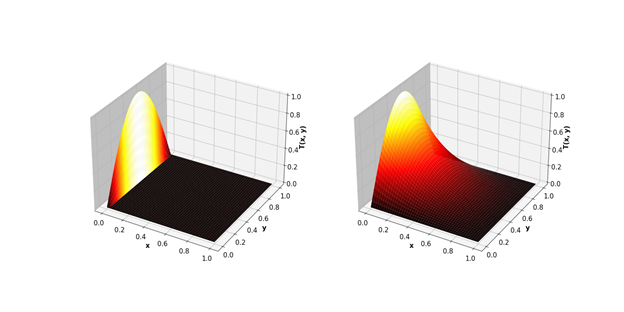

その結果、GPUギャップはさらに重要になります。
マイナス
- このようなコードの記述は、純粋なPythonバージョンよりもいくらか複雑であり、GPUで並列コンピューティングがどのように機能するかを理解する必要があります。
- ビデオカードがアクセスできないGPUに転送するには、データを別のアレイにコピーする必要があります。これは、非常に大きなアレイを処理するときに問題になる可能性があります。
