スピーチを扱うとき、いくつかの非常に「単純な」質問が常に発生します。その解決策には、音声(または音楽)の存在の検出、数字の存在の検出、言語の分類など、便利でオープンで単純なツールは多くありません。
音声検出の問題(Voice Activity Detector、VAD)を解決するために、Googleのかなり人気のあるツールであるwebRTCVADがあります。リソースとコンパクトさは要求されませんが、主な欠点は、ノイズに対する不安定さ、多数の誤検知、および微調整が不可能なことです。問題を音声検出ではなく無音検出(無音とは音声とノイズの両方がないこと)に再定式化すると、非常に簡単な方法(たとえば、エネルギーしきい値)で解決されますが、同じ欠点と制限があることは明らかです。最も不快なことは、多くの場合、そのような決定は脆弱であり、一部のハードコードしきい値は他のドメインに転送されないことです。
STT ( PyTorch ONNX), , , , VAD , MIT. .
"VAD"?
- VAD — , ;
- Number detector — , ;
- Language classifier — ;
- 4 (, , , ), VAD ( — - , , VAD !);
"" :
- 4 ;
- VAD WebRTC ;
- ;
- , 1 ;
- edge ;
- (PyTorch, ONNX);
- WebRTC , ;
- PyTorch (JIT), ONNX;
- ;
- ;
- (- , , STT);
- edge ;
- ONNX ;
- VAD 16 kHz, 8 kHz;
colab . , :
- PyTorch ONNX;
- — VAD — , / ;
- — . VAD ;
- , ( , 1 , - );
, VAD :
import torch
torch.set_num_threads(1)
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',
model='silero_vad',
force_reload=True)
(get_speech_ts,
_, read_audio,
_, _, _) = utils
files_dir = torch.hub.get_dir() + '/snakers4_silero-vad_master/files'
wav = read_audio(f'{files_dir}/en.wav')
speech_timestamps = get_speech_ts(wav, model,
num_steps=4)
print(speech_timestamps)
VAD
, VAD. .
1 AMD Ryzen Threadripper 3960X. :
torch.set_num_threads(1) # pytorch
ort_session.intra_op_num_threads = 1 # onnx
ort_session.inter_op_num_threads = 1 # onnx
, :
- num_steps — "";
- number of audio streams — ;
- , num_steps * number of audio streams;
:
| Batch size | Pytorch latency, ms | Onnx latency, ms |
|---|---|---|
| 2 | 9 | 2 |
| 4 | 11 | 4 |
| 8 | 14 | 7 |
| 16 | 19 | 12 |
| 40 | 36 | 29 |
| 80 | 64 | 55 |
| 120 | 96 | 85 |
| 200 | 157 | 137 |
, 1 :
| Batch size | num_steps | Pytorch model RTS | Onnx model RTS |
|---|---|---|---|
| 40 | 4 | 68 | 86 |
| 40 | 8 | 34 | 43 |
| 80 | 4 | 78 | 91 |
| 80 | 8 | 39 | 45 |
| 120 | 4 | 78 | 88 |
| 120 | 8 | 39 | 44 |
| 200 | 4 | 80 | 91 |
| 200 | 8 | 40 | 46 |
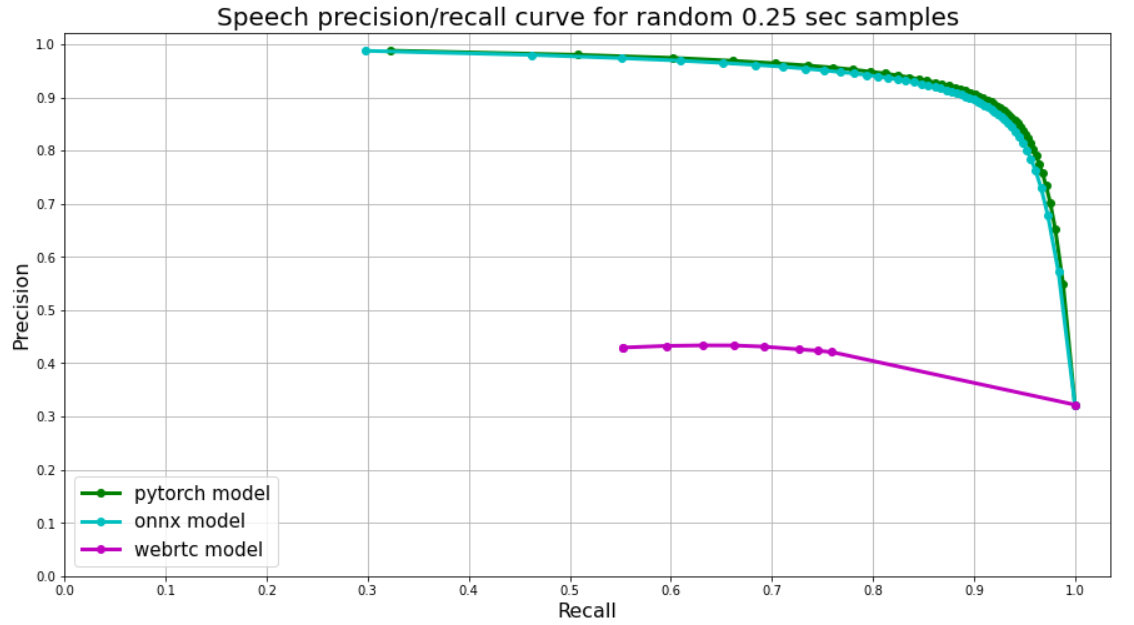
, , VAD . WebRT, 0 1?
WebRTC 0 1. - 30 , 250 8 . , 0 1 .
: