
フォトリチャード・ジェイコブスのUnsplash
で2020年11月には、我々は9.6から12.4に、当社のPostgreSQLクラスタをアップグレードするための主要な移行を開始しました。この投稿では、Coffee Meets Bagelでのアーキテクチャの概要を簡単に説明し、アップグレードのダウンタイムが30分未満に短縮された方法を説明し、その過程で学んだことを共有します。
建築
参考:Coffee Meets Bagelは、キュレーションシステムを備えたロマンチックな出会い系アプリです。毎日、ユーザーは自分のタイムゾーンの正午に高品質の候補者の限られたバッチを受け取ります。これにより、非常に予測可能な負荷パターンが得られます。記事を書いた瞬間から先週のデータを見ると、ピーク時には1秒あたり平均3万件のトランザクションがあり、最大6万5千件です。
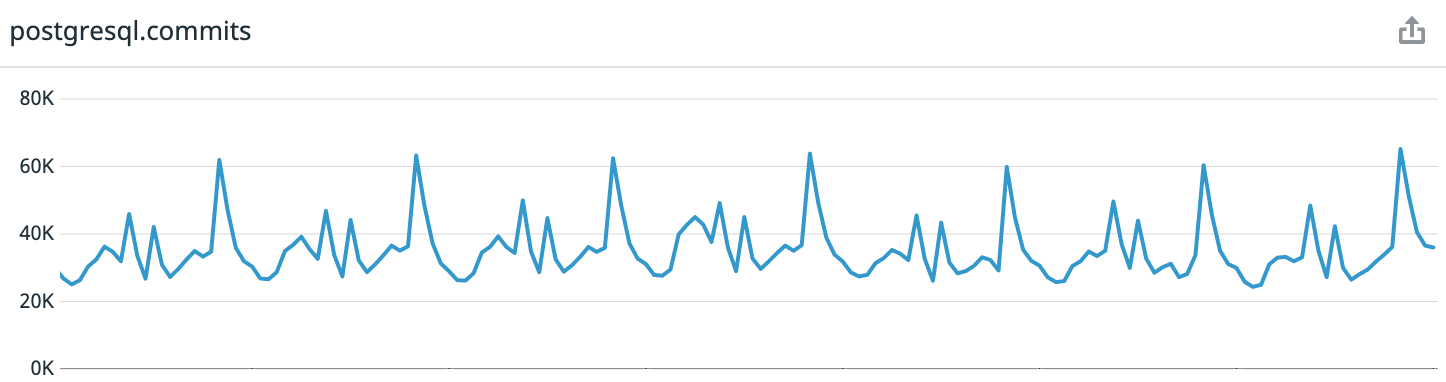
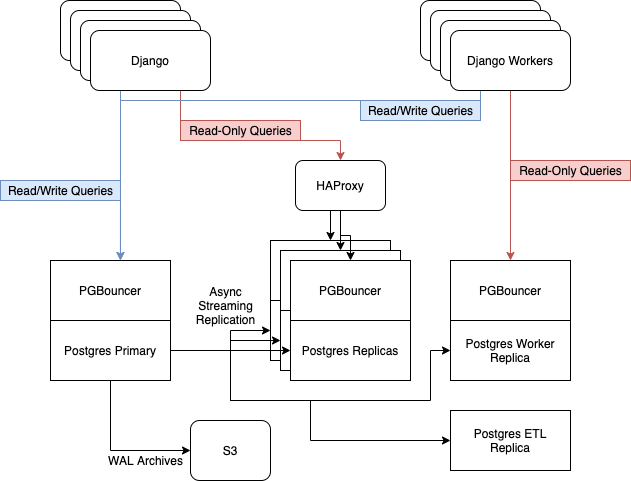
アップデート前は、AWSのi3.8xlargeインスタンスで6台のPostgresサーバーが実行されていました。それらには、1つのマスターノード、読み取り専用Webトラフィックを処理するための3つのレプリカ、HAProxyとのバランス、非同期ワーカー用の1つのサーバー、およびETL [抽出、変換、読み込み]および ビジネスインテリジェンス用の1つのサーバーが含まれていました 。..。
レプリカフリートを最新の状態に保つために、Postgresの組み込みストリーミングレプリケーションに依存しています。
アップグレードの理由
過去数年間、データレイヤーを著しく無視してきました。その結果、データレイヤーは少し古くなっています。特に多くの「松葉杖」がメインサーバーによって検出されました。これは3。5年間オンラインになっています。サーバーを停止することなく、さまざまなシステムライブラリとサービスにパッチを適用します。 r / uptimeporn subredditの

私の候補
結果として、あなたを緊張させる多くの奇妙なことが蓄積されました。たとえば、新しいサービスは
systemd
開始され ません。
datadog
セッションでエージェントの起動を構成する必要があり ました
screen
。プロセッサの負荷が50%を超えると、SSHが応答を停止し、サーバー自体が定期的にデータベース要求を送信することがありました。
また、ディスクの空き領域が危険な値に近づき始めました。上で述べたように、Postgresは7.6TBのNVMeストレージを持つEC2のi3.8xlargeインスタンスで実行されました。EBSとは異なり、ここではディスクのサイズを動的に変更することはできません。最初に配置されたものが変更されます。そして、ディスクの約75%を埋めました。将来の成長をサポートするには、インスタンスサイズを変更する必要があることが明らかになりました。
私たちの要件
- 最小のダウンタイム。アップグレードエラーによる計画外の停止を含め、合計4時間のダウンタイムの目標を設定しました。
- 新しいインスタンス上に新しいデータベースクラスターを構築して、現在の古いサーバー群を置き換えます。
- 拡大する余地がある場合は、i3.16xlargeに移動します。
Postgresをアップグレードするには、バックアップと復元、pg_upgrade、およびpglogical論理レプリケーションの3つの方法があります。
最初の方法をすぐに中止し、バックアップから復元しました。5.7TBのデータセットの場合、時間がかかりすぎます。その速度では、pg_upgradeは要件2および3を満たしていませんでした。これは、同じマシン上の移行ツールです。したがって、論理レプリケーションを選択しました。
私たちのプロセス
pglogicalの主要な機能については十分に書かれています。したがって、一般的な真実を繰り返す代わりに、私は単に私に役立つことが判明した記事を提供します:
- 最小限のダウンタイムでメジャーバージョンをアップグレードします。
- pglogicalを使用してPostgreSQLを9.4から10.3にアップグレードします。
- pglogicalの謎を解き明かす-チュートリアル。
新しいプライマリPostgres12サーバーを作成し、pglogicalを使用してすべてのデータを同期しました。同期して着信変更を複製するようになったとき、ストリーミングレプリカの追加を開始しました。新しいストリーミングレプリカを設定した後、それをHAProxyに含め、古いバージョン9.6の1つを削除しました。
このプロセスは、マスターを除いてPostgres9.6サーバーが完全にシャットダウンされるまで続きました。構成は次の形式でした。

次に、メンテナンスウィンドウを要求したのは、クラスターの切り替え(フェイルオーバー)の順番でした。切り替えプロセスはインターネットでも十分に文書化されているため、一般的な手順についてのみ説明します。
- サイトの技術作業モードへの移行。
- マスターのDNSレコードを新しいサーバーに変更する。
- 主キーのすべてのシーケンスの強制同期。
CHECKPOINT
古いマスターでのチェックポイント()の手動開始。- 新しいウィザードで-いくつかのデータ検証とテスト手順を実行します。
- サイトを有効にします。
全体として、移行は順調に進みました。インフラストラクチャにこのような大きな変更があったにもかかわらず、計画外のダウンタイムはありませんでした。
学んだ教訓
操作の全体的な成功により、途中でいくつかの問題が発生しました。それらの最悪のものは、Postgres9.6マスターをほぼ殺しました...
レッスン1:同期が遅いと危険な場合がある
コンテキストから始めましょう:pglogicalはどのように機能しますか?プロバイダーの送信側プロセス(この場合は古いウィザード9.6)は、先行書き込みWALログをデコードし、論理的な変更をフェッチして、サブスクライバーに送信します。
サブスクライバーが遅れている場合、プロバイダーはWALセグメントを格納するため、サブスクライバーが追いついたときにデータが失われることはありません。
テーブルがレプリケーションストリームに初めて追加されるとき、pglogicalは最初にテーブルデータを同期する必要があります。これは、Postgresコマンドで実行され
COPY
ます。その後、WALセグメントがプロバイダーに蓄積され始め、操作中に変更されます
COPY
最初の同期後にサブスクライバーに転送され、データが失われないことが判明しました。
実際には、これは、書き込み/変更の負荷が大きいシステムで大きなテーブルを同期する場合、ディスク使用量を注意深く監視する必要があることを意味します。最大(4 TB)のテーブルを同期する最初の試みで、チームとオペレーター
COPY
は1日以上作業し ました。この間、ベンダーノードは1テラバイトを超えるプロアクティブなWALログを蓄積しました。
言われたことから思い出すかもしれませんが、私たちの古いデータベースサーバーには2テラバイトの空きディスクスペースしか残っていませんでした。サブスクライバーのサーバーディスクの満杯から、テーブルの4分の1のみがコピーされたと推定されました。したがって、同期プロセスをすぐに停止する必要がありました。マスター上のディスクは以前に終了していました。
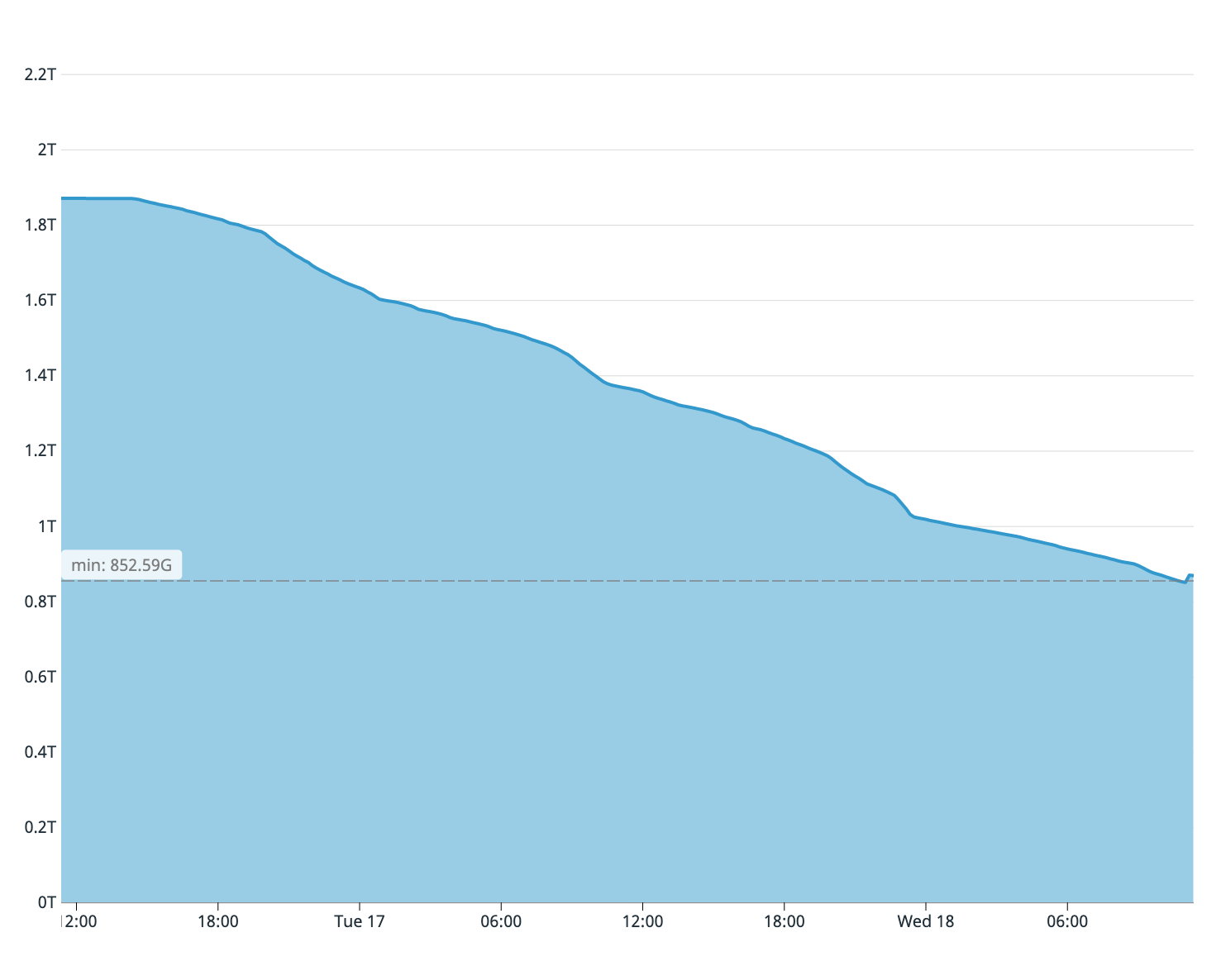
最初の同期試行時に古いウィザードで使用可能なディスク容量
同期プロセスを高速化するために、サブスクライバデータベースに次の変更を加えました。
- 同期テーブルのすべてのインデックスを削除しました。
fsynch
に切り替えましたoff
;- に変更さ
max_wal_size
れました50GB
; - に変更さ
checkpoint_timeout
れました1h
。
これらの4つのステップにより、サブスクライバーでの同期プロセスが大幅に高速化され、テーブル同期の2回目の試行が8時間で完了しました。
レッスン2:すべての行の変更は競合としてログに記録されます
pglogicalが競合を検出すると、アプリケーションはログに「
CONFLICT: remote UPDATE on relation PUBLIC.foo. Resolution: apply_remote
」エントリを残します 。
ただし、サブスクライバーによって処理されたすべての行の変更は、競合としてログに記録されることが判明しました。数時間のレプリケーションで、サブスクライバーのデータベースはギガバイト単位の競合するログファイルを残しました。
この問題は
pglogical.conflict_log_level = DEBUG
、ファイルにパラメータを設定することで解決され ました
postgresql.conf
。
著者について
 Tommy Leeは、Coffee MeetsBagelのシニアソフトウェアエンジニアです。それ以前は、Microsoftとカナダの会計自動化システムメーカーであるWaveHQに勤務していました。
Tommy Leeは、Coffee MeetsBagelのシニアソフトウェアエンジニアです。それ以前は、Microsoftとカナダの会計自動化システムメーカーであるWaveHQに勤務していました。