注釈
ユーザーが広告または製品をクリックする可能性を予測することを目的としたクリックスルー率(CTR)予測は、オンライン広告やアドバイザリー(推奨)システムなどの多くのオンラインアプリケーションにとって重要です。この問題は非常に複雑です。理由は次のとおりです。1)入力関数(ユーザーID、ユーザー年齢、アイテムID、アイテムカテゴリなど)は通常まばらです。 2)効果的な予測は、高次の組み合わせ関数(別名クロス関数)に依存します。これは、ドメインの専門家による手動処理に非常に時間がかかり、列挙できません。したがって、スパースおよび高次元の生のオブジェクトの低次元表現とそれらの意味のある組み合わせを見つけるための努力がなされてきました。
この記事では、入力オブジェクトの高次オブジェクトの相互作用を自動的に分析するための効率的で効果的なAutoIntメソッドを提案します。提案されたアルゴリズムは非常に一般的であり、数値入力機能とカテゴリ入力機能の両方に適用できます。特に、同じ低次元空間内の数値的特徴とカテゴリー的特徴の両方を比較します。次に、低次元空間での特徴の相互作用を明示的にモデル化するために、残余接続を備えた多目的自己調整ニューラルネットワークが提案されます。多目的自己ストレスニューラルネットワークのさまざまな層の助けを借りて、入力特徴の組み合わせのさまざまな順序をシミュレートすることが可能です。モデル全体をエンドツーエンドで大規模な生データに効果的に適用できます。4つの実際のデータセットでの実験結果は、提案されたアプローチが既存の最新の予測アプローチよりも優れているだけでなく、ネットワークの優れた説明力を提供することを示しています。コードはで入手できます。
1.はじめに
ユーザーが広告や製品をクリックする可能性を予測すること(クリック率の予測とも呼ばれます)は、オンライン広告やレコメンデーションシステムなどの多くのWebアプリケーションにとって重要な問題です[8、10、15]。予測の有効性は、ビジネスプロバイダーの最終的な収益に直接影響します。その重要性のために、それは学界と商業界の両方でますます関心を集めています。
, . . -, [8, 11, 13, 21, 32]. , / . , , . CTR Criteo, 30 99,99%. (). -, [8, 11, 19, 32], . , , -, , . <Gender=Male, Age=10, productCategory=VideoGame> . . , [8, 26]. : ? , . , , .
, () [26], , [27, 28]. , , . , [8, 11, 13, 38], . , . . , , - [4]. -, , , . , , .
, - [36]. , , . , , , (, ). , . , [36]. , () , , , . . , . [12], . , .
, :
;
, , ;
, CTR , , .
. 2. . 3 . 4. . 5 . , 6.
2.
: 1) -; 2) ; 3) .
2.1
-, [8-10, 15, 21, 29, 43]. , Google Wide&Deep[8] , , . . . , . [31] - , <, , >. Oentaryo . [24] .
2.2
, . () [26], [27, 28]. . , (FFM) [16] . GBFM [7] AFM [40] . .
, . , NFM [13] . , PNN [25], FNN [41], DeepCrossing [32], Wide&Deep [8] DeepFM [11] . , . , , . -, Deep&Cross [38] xDeepFM [19] . , , – . -, [39, 42, 44] , , . -, HOFM [5] . HOFM , ( 5) . , .
2.3
: [2] [12].
[2] , [35], [30] [14, 33, 43]. . [36] - .
[12] ImageNet. , y = F (x) + x, , .
3.
(CTR) :
1. ( CTR) x ∈ R n u v, , n - . , u v x.
CTR , x , . , x , . . , , [6, 8, 11, 23, 26, 32].

, .
2 ( p-). x ∈ R n p- g (xi1 , ..., xip ), , p- , g (·) - , [26] [19, 38]. , xi1 × xi2- , xi1 xi2.
. . , . , . .
3 ( ). x ∈ Rn , - x, .
4. Autoint:
AutoInt, CTR. , , .
4.1
, . .1, x, , (. . , ) . , () . , , . .
, . .

4.2
, . ,
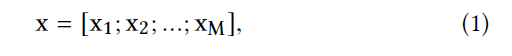
M - , xi - i- . xi - , i- (, x1 . 2). xi - , i- (, xM . 2).
4.3
, (, ). , , . .,

Vi - i, xi - . , xi - . . , , (, «»). 2 :

q - , i- , xi - - .
, . ,

vm - m, xm - .
, , .2.
4.4
, . , , . , . - - [36].
(Multi-head self-attentive network) [36] . , [36] [20], [37]. .
, «-» [22], , . m, , , m. m k () h :

ψ (h) (·, ·) - , m k. , ⟨·, ·⟩. - .
W(h)Query, W(h)Key ∈ Rd′ × d 5 - , Rd Rd′. m h, , α(h)m, k:
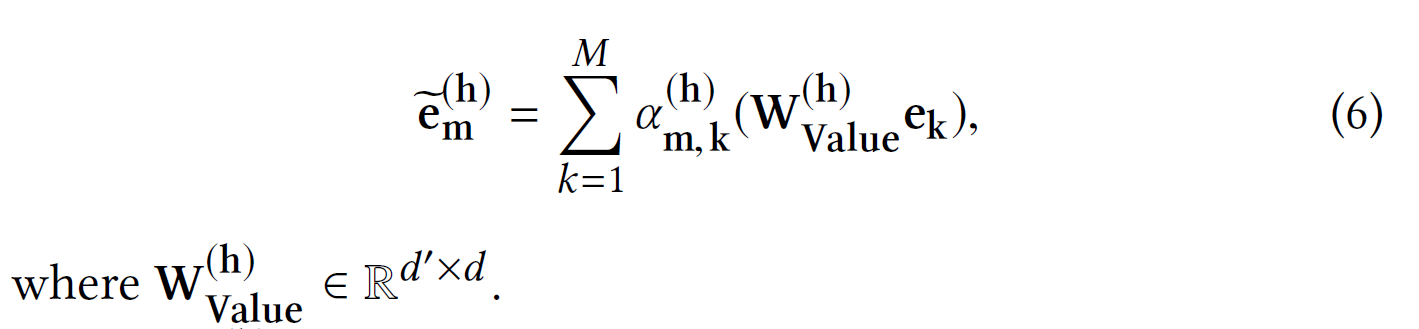
(6) m ( h), , . , , , . , , :

⊕ - , H - .
 m.")
, (. . ) , . ,
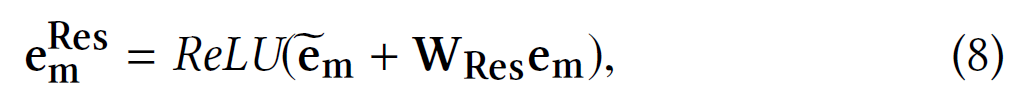
W Res ∈ R d ′ H × d - [12], ReLU (z) = max (0, z) - .
em eResm, . . , .
4.5
{eResm }Mm=1, , , , () . CTR , :

w ∈ R d ′ H M - , , b - , σ (x) = 1 / (1 + e−x) .
4.6
- , :
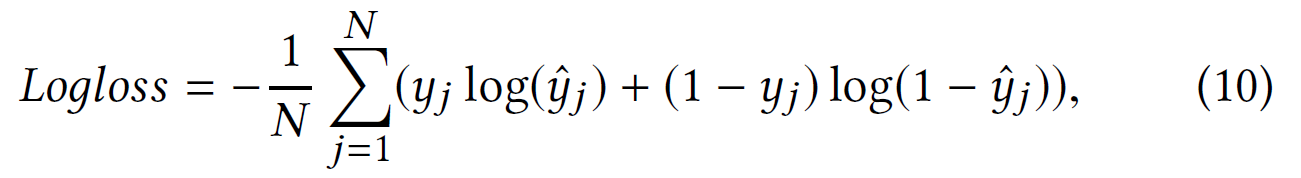
yj yˆj - CTR , j , N - . , :

logloss .
4.7 AutoInt
. , 5-8, , .
, (. . M = 4), x1, x2, x3 x4 . (, 5) , , , g (x1, x2), g (x2, x3) g ( x3, x4) , g (·) ( 2) ReLU (·). , x1, eRes1. , , .
, . eRes1 eRes3, , , x1, x2 x3, , eRes1 eRes3, eRes1 g (x1, x2), eRes3 x3 ( ). , . , g (x1, x2, x3, x4) e Res 1 e Res 3, g (x1, x2) g (x3 , x4) . , .
, , AutoInt , , . , [3, 18].
, [11, 19, 32], nd , n - , d - . : {W (h) Query, W (h) Key, W (h) Value, WRes}, L- L × (3dd ′ + d ′ Hd), M. , d ′ HM + 1 . , O (Ldd′H). , H d ′ (, H = 2 d′ = 32 ), .
. -, ( ) O(Mdd' + M2d' ) . O(Mdd' + M2d') . H (), O(MHd' (M + d)) . , H,d d ' . AutoInt 5.2.
5.
. :
RQ1) AutoInt CTR? ?
RQ2) ?
RQ3) ? ?
RQ4) ? , .

5.1
5.1.1 . . 1.
Criteo. CTR, 45 . 26 13 .
Avazu. , , . 23 , / .
KDD12. KDDCup 2012, . CTR, , (1 > 0, 0 ), FFM [16].
MovieLens-1M. . ( ) 3 , , . 3 – , 3.
. -, ( ) «<>», {10, 5, 10} Criteo, Avazu KDD12 . -, , , z log2(z) z> 2, Criteo Competition. -, 80% .
5.1.2 . :
AUC ROC (AUC) , CTR , . AUC .
Logloss. logloss , 10, .
, AUC Logloss 0,001 CTR, [8, 11, 38].
5.1.3 . : A) , ; ) , ; C) , . .
LR (). LR .
FM [26] (B). FM .
F [40] (B). AFM - , . FM, , .
DeepCrossing [32] (C). DeepCrossing .
NFM [13] (C). NFM . .
CrossNet [38] (). -, Deep&Cross, .
CIN [19] (C). , xDeepFM, .
HOFM[5] (). HOFM . Blondel et al. [5] [13], , .
CrossNet CIN, Deep&Cross xDeepFM, plain DNN (. . 5.5).
5.1.4 . TensorFlow[1]. AutoInt d 16, - 1024. AutoInt , d 32. ( ) - . , [34] {0.1 - 0.9} MovieLens-1M, , . 200 - NFM, . CN CIN AutoInt. DeepCrossing 100, . , . , Adam [17] , .

5.2 (RQ1)
. , 10 , 2. : 1) FM AFM, , LR , , CTR; 2) - , ; , DeepCrossing NFM , FM AFM , (, CIN ); 3) HOFM FM Criteo MovieLens-1M, , ; 4) AutoInt .
Avazu CIN , AutoInt AUC, Logloss. , AutoInt , DeepCrossing, , , .

4. , LR - . FM NFM , NFM . CIN, , - . . , AutoInt , DeepCrossing NFM.
( ) . 3, CIN AutoInt .
, , AutoInt . CIN, AutoInt -.

5.3 (RQ2) , AutoInt.
5.3.1 . AutoInt , , , . , , . 4, , . , KDD12 MovieLens-1M, , .

5.3.2 . ( 4). , , . , ( ), , .
5. , , , , , . , . . , . , , , .


5.3.3 . d, . KDD12 , , . MovieLens-1M. 24, . , , , .
5.4 (RQ3)
, . , AutoInt . MovieLens-1M.
, , . . 7 () , . , AutoInt <Gender=Male, Age=[18-24), MovieGenre=Action&Triller> (. . ). , , , .
.")
, . . . 7 (). , <Gender, Genre>, <Age, Genre>, <RequestTime, ReleaseTime> <Gender, Age, Genre> (. . ) , .
注意の重みマップ。 軸は、機能フィールド<性別、年齢、職業、郵便番号、RequestTime、RealeaseTime、Genre>を表します。 研究された組み合わせ関数のいくつかを長方形で強調表示します。")
5.5 (RQ4)
CTR [8, 11, 19]. , , AutoInt . AutoInt+ :
Wide&Deep [8]. Wide&Deep ;
DeepFM [11]. DeepFM ;
Deep&Cross [38]. Deep&Cross- CrossNet ;
xDeepFM [19]. xDeepFM - CIN .
5 ( 10 ) . : 1) , , , , , , , AutoInt ; 2) , AutoInt+ , CTR.
6.
CTR, -, . , . . , . , , AUC Logloss .
-. , AutoInt , , .
[1] Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, et al. 2016. TensorFlow: A System for Large-Scale Machine Learning.. In OSDI, Vol. 16. 265–283.
[2] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. In International Conference on Learning Representations.
[3] Yoshua Bengio, Aaron Courville, and Pascal Vincent. 2013. Representation learning: A review and new perspectives. IEEE transactions on pattern analysis and machine intelligence 35, 8 (2013), 1798–1828.
[4] Alex Beutel, Paul Covington, Sagar Jain, Can Xu, Jia Li, Vince Gatto, and Ed H Chi. 2018. Latent Cross: Making Use of Context in Recurrent Recommender Systems. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining. ACM, 46–54.
[5] Mathieu Blondel, Akinori Fujino, Naonori Ueda, and Masakazu Ishihata. 2016. Higher-order factorization machines. In Advances in Neural Information Processing Systems. 3351–3359.
[6] Mathieu Blondel, Masakazu Ishihata, Akinori Fujino, and Naonori Ueda. 2016. Polynomial Networks and Factorization Machines: New Insights and Efficient Training Algorithms. In International Conference on Machine Learning. 850–858.
[7] Chen Cheng, Fen Xia, Tong Zhang, Irwin King, and Michael R Lyu. 2014. Gradient boosting factorization machines. In Proceedings of the 8th ACM Conference on Recommender systems. ACM, 265–272.
[8] Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al.Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems. ACM, 7–10.
[9] Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 191–198.
[10] Thore Graepel, Joaquin Quiñonero Candela, Thomas Borchert, and Ralf Herbrich. 2010. Web-scale Bayesian Click-through Rate Prediction for Sponsored Search Advertising in Microsoft’s Bing Search Engine. In Proceedings of the 27th International Conference on International Conference on Machine Learning. 13–20.
[11] Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: A Factorization-machine Based Neural Network for CTR Prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence. AAAI Press, 1725–1731.
[12] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition. 770–778.
[13] Xiangnan He and Tat-Seng Chua. 2017. Neural factorization machines for sparse predictive analytics. In Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval. ACM, 355–364.
[14] Xiangnan He, Zhankui He, Jingkuan Song, Zhenguang Liu, Yu-Gang Jiang, and Tat-Seng Chua. 2018. NAIS: Neural attentive item similarity model for recommendation. IEEE Transactions on Knowledge and Data Engineering 30, 12 (2018), 2354–2366.
[15] Xinran He, Junfeng Pan, Ou Jin, Tianbing Xu, Bo Liu, Tao Xu, Yanxin Shi, Antoine Atallah, Ralf Herbrich, Stuart Bowers, et al. 2014. Practical lessons from predicting clicks on ads at facebook. In Proceedings of the Eighth International Workshop on Data Mining for Online Advertising. ACM, 1–9.
[16] Yuchin Juan, Yong Zhuang, Wei-Sheng Chin, and Chih-Jen Lin. 2016. Fieldaware factorization machines for CTR prediction. In Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 43–50.
[17] Diederick P Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In International Conference on Learning Representations.
[18] Honglak Lee, Roger Grosse, Rajesh Ranganath, and Andrew Y Ng. 2011. Unsupervised learning of hierarchical representations with convolutional deep belief networks. Commun. ACM 54, 10 (2011), 95–103.
[19] Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 1754– 1763.
[20] Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. 2017. A structured self-attentive sentence embedding. In International Conference on Learning Representations.
[21] H. Brendan McMahan, Gary Holt, D. Sculley, Michael Young, Dietmar Ebner, Julian Grady, Lan Nie, Todd Phillips, et al. 2013. Ad Click Prediction: A View from the Trenches. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 1222–1230.
[22] Alexander Miller, Adam Fisch, Jesse Dodge, Amir-Hossein Karimi, Antoine Bordes, and Jason Weston. 2016. Key-Value Memory Networks for Directly Reading Documents. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 1400–1409.
[23] Alexander Novikov, Mikhail Trofimov, and Ivan Oseledets. 2016. Exponential machines. arXiv preprint arXiv:1605.03795 (2016).
[24] Richard J Oentaryo, Ee-Peng Lim, Jia-Wei Low, David Lo, and Michael Finegold. Predicting response in mobile advertising with hierarchical importanceaware factorization machine. In Proceedings of the 7th ACM international conference on Web search and data mining. ACM, 123–132.
[25] Yanru Qu, Han Cai, Kan Ren, Weinan Zhang, Yong Yu, Ying Wen, and Jun Wang.Product-based neural networks for user response prediction. In Data Mining (ICDM), 2016 IEEE 16th International Conference on. IEEE, 1149–1154.
[26] Steffen Rendle. 2010. Factorization machines. In Data Mining (ICDM), 2010 IEEE 10th International Conference on. IEEE, 995–1000.
[27] Steffen Rendle, Christoph Freudenthaler, and Lars Schmidt-Thieme. 2010. Factorizing personalized markov chains for next-basket recommendation. In Proceedings of the 19th international conference on World wide web. ACM, 811–820.
[28] Steffen Rendle, Zeno Gantner, Christoph Freudenthaler, and Lars Schmidt-Thieme. Fast context-aware recommendations with factorization machines. In Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval. ACM, 635–644.
[29] Matthew Richardson, Ewa Dominowska, and Robert Ragno. 2007. Predicting clicks: estimating the click-through rate for new ads. In Proceedings of the 16th international conference on World Wide Web. ACM, 521–530.
[30] Alexander M. Rush, Sumit Chopra, and Jason Weston. 2015. A Neural Attention Model for Abstractive Sentence Summarization. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 379–389.
[31] Lili Shan, Lei Lin, Chengjie Sun, and Xiaolong Wang. 2016. Predicting ad clickthrough rates via feature-based fully coupled interaction tensor factorization. Electronic Commerce Research and Applications 16 (2016), 30–42.
[32] Ying Shan, T Ryan Hoens, Jian Jiao, Haijing Wang, Dong Yu, and JC Mao. 2016. Deep crossing: Web-scale modeling without manually crafted combinatorial features. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 255–262.
[33] Weiping Song, Zhiping Xiao, Yifan Wang, Laurent Charlin, Ming Zhang, and Jian Tang. 2019. Session-based Social Recommendation via Dynamic Graph Attention Networks. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining. ACM, 555–563.
[34] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: A simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research 15, 1 (2014), 1929–1958.
[35] Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al. 2015. End-to-end memory networks. In Advances in neural information processing systems. 2440–2448.
[36] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems. 6000–6010.
[37] Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. 2018. Graph Attention Networks. In International Conference on Learning Representations.
[38] Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & Cross Network for Ad Click Predictions. In Proceedings of the ADKDD’17. ACM, 12:1–12:7.
[39] Xiang Wang, Xiangnan He, Fuli Feng, Liqiang Nie, and Tat-Seng Chua. 2018. TEM: Tree-enhanced Embedding Model for Explainable Recommendation. In Proceedings of the 2018 World Wide Web Conference on World Wide Web. International World Wide Web Conferences Steering Committee, 1543–1552.
[40] Jun Xiao, Hao Ye, Xiangnan He, Hanwang Zhang, Fei Wu, and Tat-Seng Chua. Attentional factorization machines: learning the weight of feature interactions via attention networks. In Proceedings of the 26th International Joint Conference on Artificial Intelligence. AAAI Press, 3119–3125.
[41] Weinan Zhang, Tianming Du, and Jun Wang. 2016. Deep learning over multi-field categorical data. In European conference on information retrieval. Springer, 45–57.
[42] Qian Zhao, Yue Shi, and Liangjie Hong. 2017. GB-CENT: Gradient Boosted Categorical Embedding and Numerical Trees. In Proceedings of the 26th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, 1311–1319.
[43] Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep Interest Network for ClickThrough Rate Prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 1059–1068.
[44] Jie Zhu、Ying Shan、JC Mao、Dong Yu、Holakou Rahmanian、およびYiZhang。2017.ディープ埋め込みフォレスト:ディープ埋め込み機能を備えたフォレストベースのサービス。知識発見とデータマイニングに関する第23回ACMSIGKDD国際会議の議事録。ACM、1703-1711。