
12の問題があり、名前とデザインを少し変更するときが来ましたが、内部ではまだ調査、デモ、オープンモデル、データセットを待っています。Machine LearningToolkitの新作をご覧ください。
DALL E
アクセシビリティ: プロジェクトページ/待機リストを介したクローズドAPIへのアクセス
OpenAIは、画像とテキストのペアでトレーニングされた120億のパラメーターを備えた新しいDALL-Eトランスフォーマー言語モデルを発表しました。このモデルはGPT-3に基づいており、テキストによる説明から画像を合成するために使用されます。
昨年6月、同社 は、正確な説明を含む一連のピクセルでトレーニングされたモデルが、入力に入力される画像の空白を埋める方法を示しました。その結果はすでに印象的でしたが、ここではOpenAIがすべての期待を上回りました。 GPT-3が一貫した完全な文を合成するように、DALL・Eは複雑な画像を作成します。

モデルは、擬人化されたオブジェクト(犬を歩く大根)と互換性のないオブジェクト(ハープの形をしたカタツムリ)の組み合わせに驚くほど優れています。そのため、名前に2つの名前の合併を選択しました-スペインのシュールレアリストのサルバドールダリとピクサーロボットWALL-I。
では、モデルはどのような結果を誇っていますか?
モデルは空間の深さを視覚化できるため、3次元シーンを操作することができます。目的の画像を説明するときは、オブジェクトをどの角度から、どの照明の下で見るかを示すだけで十分です。将来的には、これにより真の3D表現を作成できるようになります。
さらに、このモデルは、魚眼レンズで撮影する場合のように、シーンに光学効果を適用することができます。しかし、これまでのところ、彼は反射にうまく対処していません-鏡の中の立方体は説得力のある合成がされていません。したがって、さまざまな程度の信頼性で、自然言語を介したDALL・Eは、業界で3Dモデリングエンジンが使用されるタスクに対処します。これにより、部屋のデザインのレンダリングに使用できます。
モデルは、地理と象徴的なランドマーク、および個々の時代の特徴をよく認識しています。彼女は古い電話やサンフランシスコのゴールデンゲートブリッジの写真を合成することができます。
これらすべてにより、モデルは超正確な説明を必要としません-それはギャップ自体のいくつかを埋めます。 Open AIが指摘しているように、説明が正確であればあるほど、結果は悪くなります。
GPT-3はゼロショットモデルであるため、特定のタスクを実行するために追加の構成やトレーニングを行う必要はありません。説明に加えて、モデルが目的の回答を生成するようにヒントを与えることができます。 DALL・Eはレンダリングでも同じことを行い、プロンプトに基づいてさまざまな画像から画像への変換タスクを実行できます。たとえば、画像を入力として指定し、スケッチの形式で作成するように依頼できます。
驚いたことに、作成者はそのような目標を設定せず、モデルをトレーニングするときにこれを提供しませんでした。能力はテスト中にのみ明らかにされました。
この発見に導かれて、著者は視覚的IQテストの論理的問題を解決し、提示されたオプションから正しい答えを選択するのではなく、不足している要素を完全に予測するタスクを設定するDALL・Eの能力を研究しました。
一般に、モデルは、幾何学的理解が必要なタスクの一部でシーケンスを正しく続行することができました。
モデルはまだ公開されておらず、そのアーキテクチャの大まかな説明すらありません。この段階で、APIへのアクセスをリクエストするか、PyTorchの非公式実装を確認できます (TensorFlowの非公式バージョンも開発中です )。
CLIP(対照言語–画像の事前トレーニング)
アクセシビリティ: プロジェクトページ/ ソースコード
ディープラーニングはコンピュータービジョンに革命をもたらしましたが、現在のアプローチには、この分野でのDNNの使用に疑問を投げかける2つの重大な問題があります。
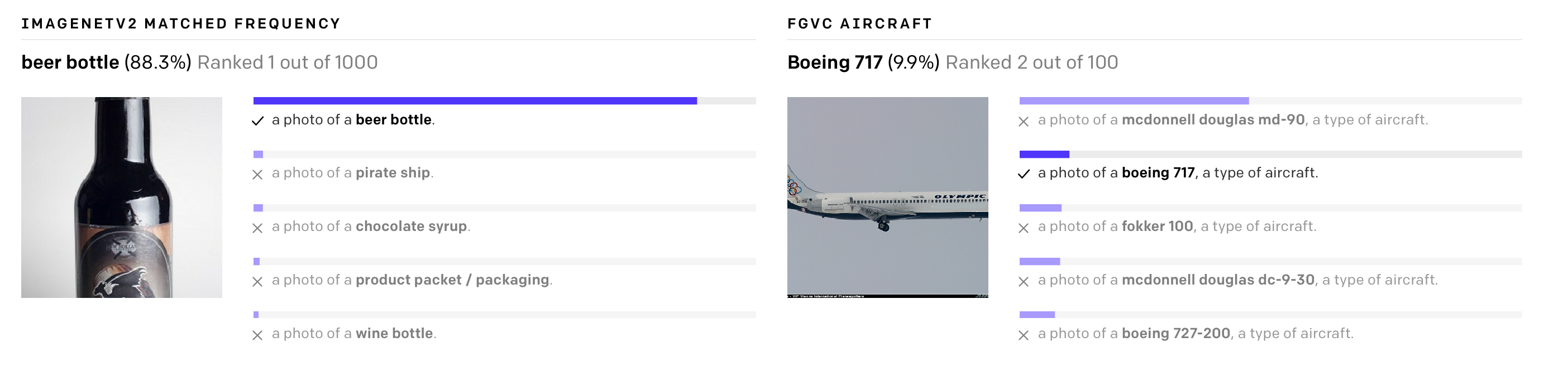
まず、データセットの作成は依然として非常にコストがかかりますが、同時に、その結果、非常に限られた視覚画像のセットを認識でき、狭いタスクに適しています。たとえば、ImageNetデータセットを準備する場合、22,000のオブジェクトカテゴリの1,400万の画像の説明を作成するのに25,000人がかかりました。同時に、ImageNetモデルは、データセットで表されるカテゴリのみを予測するのに適しています。他のタスクが必要な場合、スペシャリストは新しいデータセットを作成してモデルのトレーニングを完了する必要があります。
第二に、ベンチマークでうまく機能するモデルは、自然環境では不十分です。実世界で展開されたモデルは、実験室の設定ほどには機能しません。言い換えれば、モデルは、過去の試験の質問を詰め込んでいる学生として特定のテストに合格するように最適化されています。
OpenAIのオープンニューラルネットワークCLIPは、これらの問題を解決することを目的としています。モデルは、インターネット上で利用可能な多数の画像とテキストの説明でトレーニングされ、それらをベクトル表現、埋め込みに変換します。これらの表現は、碑文の数とそれに適した絵が近くなるように比較されます。
CLIPは、データのトレーニングなしで、さまざまなベンチマークですぐにテストできます。モデルは、直接最適化せずに分類テストを実行します。たとえば、ObjectNetテストは、さまざまな場所にあり、背景が変化するオブジェクトを認識するモデルの機能をテストしますが、ImageNetRenditionとImageNetSketchは、オブジェクトのより抽象的な画像(バナナだけでなく、スライスされたバナナ)を認識するモデルの機能をテストします。またはバナナのスケッチ)。 CLIPは、それらすべてで同等に機能します。
CLIPは、追加のトレーニング例なしで、さまざまな視覚的分類タスクを実行するように適合させることができます。CLIPを新しい問題に適用するには、エンコーダーに視覚的表現の名前を付けるだけで、これらの表現の線形分類器が生成されます。これは、教師がトレーニングしたモデルよりも精度が劣りません。
Githubには、モデルが画像をどの程度適切にグループ化しているかを示すUnsplashの写真の実装がすでにあり ます。設計者はすでにそれを使用してムードボードを設計できます。
マイクロソフトによるDeBERTa
可用性: ソース/ プロジェクトページ
いつものように、OpenAIからのニュースは他の発表を覆い隠しましたが、コミュニティで活発に議論された別のイベントがありました。 MicrosoftのDeBERTaモデルは、SuperGLUE自然言語理解(NLU)テストで人間のベースラインを上回りました。
10個のパラメーターに基づくベンチマークは、アルゴリズムが読み取った内容を「理解」して評価を行うかどうかを決定します。非専門家の平均スコアは89.8ポイントであり、モデルが解決する必要のある問題は英語の試験に匹敵します。 DeBERTaは90.3を示し、GoogleのT5 + Meenaがそれに続きました。
したがって、モデルは2回目の人間の追い越しに成功しましたが、DeBERTaのトレーニングパラメータが15億であり、T5の8分の1であることは注目に値します。
このモデルは、元のトランスフォーマーとは異なる、分割されたアテンションメカニズムを表します。各トークンは、1つのベクトルに加算されないコンテンツベクトルと位置によってエンコードされ、個別のマトリックスがそれらと連携します。
NeuralMagicEye
アクセシビリティ: プロジェクトページ/ コード/ コラボ
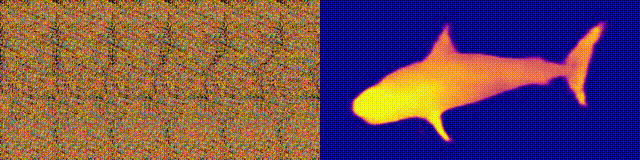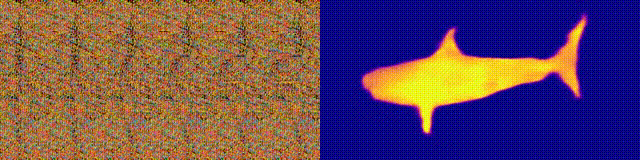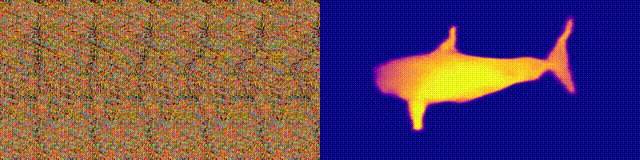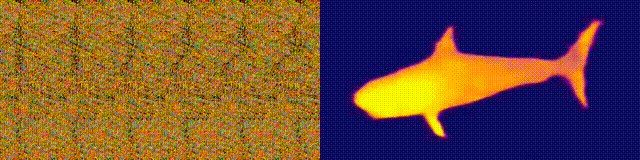
ステレオグラム付きのマジックアイアルバムを覚えていますか?これは、ステレオペアの両方の部分が同じ画像にあり、ラスター構造でエンコードされているオートステレオグラムの場合にのみ類似しているため、3次元の錯覚を作成できます。
研究の著者は、オートステレオグラムの深さを再構築し、その内容を理解するためにCNNモデルをトレーニングしました。ステレオ効果を実現するには、準周期的なテクスチャの不一致を検出して評価するようにモデルをトレーニングする必要がありました。モデルは、教師なしで3Dモデルからのデータセットでトレーニングされました。
この方法では、オートステレオグラムの深度を正確に復元できます。研究者たちは、これが視覚障害を持つ人々を助け、ステレオグラムが画像の透かしとして使用できることを望んでいます。
StyleFlow

アクセシビリティ: ソースコード
これまで何度も見てきたように、無条件のGAN(StyleGANなど)は、高品質で写実的な画像を作成できます。ただし、出力の品質を維持しながら、セマンティック属性を使用して生成プロセスを管理することはほとんど不可能です。複雑で紛らわしいGANレイテンシーのため、1つの属性を編集すると、他の属性に望ましくない変更が加えられることがよくあります。このモデルは、この問題の解決に役立ちます。たとえば、視野角、照明の変化、表情、顔の毛、性別、年齢を変更できます。
トランスフォーマーを飼いならす
アクセシビリティ: プロジェクトページ/ ソースコード
トランスフォーマーは、さまざまなアプリケーションで優れた結果を提供することができます。ただし、計算能力の点では非常に要求が厳しいため、高解像度の画像での作業には適していません。研究の著者は、変圧器を誘導的に変位した畳み込みネットワークと組み合わせ、高解像度で画像化することができました。
ポーズの埋め込み

アクセシビリティ: ソースコード
ランニングであれ、本を読んでいる場合であれ、日常の活動は、空間における人の体の位置と向きからなる一連の姿勢と考えることができます。ポーズ認識は、AR、ジェスチャ制御などの多くの可能性を開きます。ただし、2D画像から得られるデータは、カメラの視点によって異なります。Google AIのこのアルゴリズムは、さまざまな角度からポーズの類似性を認識し、ポーズの2D表示の要点をビュー不変の埋め込みと一致させます。
学ぶことを学ぶ
アクセシビリティ: ソースコード
ボトルを拾ったりテーブルに置いたりする方法を学ぶには、他の人がそれをしているのを見る必要があります。このようなオブジェクトの操作方法を学ぶために、マシンはタスクの構成要素を正常に完了するために手動でプログラムされた報酬を必要とします。ロボットがボトルをテーブルに置くことを学ぶ前に、ボトルを垂直に動かすことを学ぶことで報酬を得る必要があります。そのような一連の反復の後でのみ、彼はボトルを配置することを学びます。Facebookは、いくつかの人間の観察セッションでマシンをトレーニングする方法を導入しました。
これが今年の最初の月の明るさです。読んでいただきありがとうございます。今後のリリースにご期待ください。