
テーブル内のすべてのレコードの属性値を更新するにはどうすればよいですか?テーブルに主キーまたは一意キーを追加するにはどうすればよいですか?テーブルを2つに分割するにはどうすればよいですか?方法...
アプリケーションが移行のためにしばらく利用できない可能性がある場合、これらの質問への回答は難しくありません。しかし、データベースを停止したり、他の人がデータベースを操作するのを邪魔したりせずに、ホット移行する必要がある場合はどうでしょうか。
PostgreSQLでのスキーマとデータの移行中に発生するこれらの質問やその他の質問に、実用的なアドバイスの形で答えようとします。
この記事-SmartDataConf会議でのデコードパフォーマンス( ここでプレゼンテーションを見つけることができます。ビデオはやがて表示されます)。テキストが多かったので、資料は2つの記事に分けられます。
- 基本的な移行
- 大きなテーブルを更新するためのアプローチ。
最後に、ピボットテーブルのチートシートの形式で記事全体の要約があります。
コンテンツ
問題の核心
列を
追加するデフォルトの
列を 追加する列を削除
するインデックスを
作成するパーティションテーブルにインデックスを
作成するNOTNULL制約を
作成する外部キーを
作成する一意の制約を
作成する主キーを作成する クイックマイグレーションチートシート
問題の本質
データベースで動作するアプリケーションがあるとします。最小構成では、アプリケーション自体とデータベースの2つのノードで構成できます。

このスキームでは、アプリケーションの更新はダウンタイムとともに発生することがよくあります。同時に、データベースを更新することができます。このような状況では、主な基準は時間です。つまり、サービスが利用できない時間を最小限に抑えるために、できるだけ早く移行を完了する必要があります。
アプリケーションが大きくなり、ダウンタイムなしでリリースを実行する必要が生じた場合は、複数のアプリケーションサーバーの使用を開始します。それらは好きなだけ持つことができ、それらは異なるバージョンになります。この場合、下位互換性を確保する必要があります。

成長の次の段階で、データは1つのデータベースに収まりなくなります。シャーディングによって、データベースのスケーリングも開始します。実際には、複数のデータベースを同期的に移行することは非常に難しいため、これは、ある時点でそれらが異なるデータスキーマを持つことを意味します。したがって、アプリケーションサーバーが異なるコードと異なるデータスキーマを持つデータベースを持っている可能性がある異種環境で作業します。
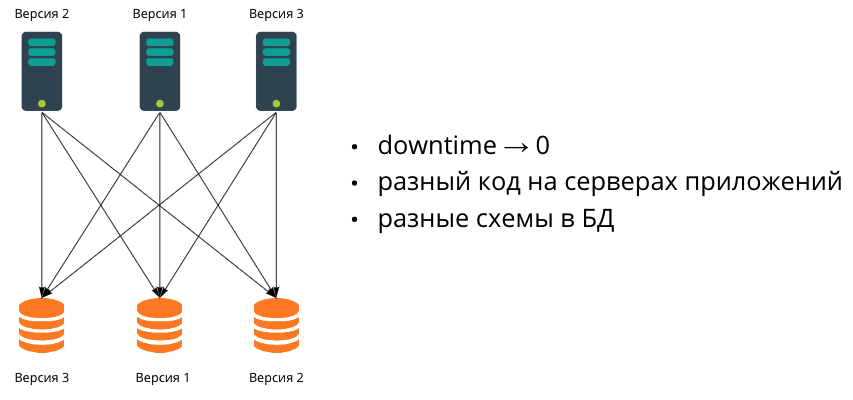
この記事で説明するのはこの構成についてであり、開発者が作成する最も一般的な移行(単純なものからより複雑なものへ)について検討します。
私たちの目標は、アプリケーションのパフォーマンスへの影響を最小限に抑えてSQL移行を実行することです。データまたはデータスキーマを変更して、アプリケーションが引き続き実行され、ユーザーが気付かないようにします。
列の追加
ALTER TABLE my_table ADD COLUMN new_column INTEGER --
おそらく、データベースを操作する人なら誰でも同様の移行を作成しました。 PostgreSQLについて言えば、この移行は非常に安価で安全です。コマンド自体は、最高レベルのロック(AccessExclusive)をキャプチャしますが、 内部ではテーブル自体のデータを書き換えずに新しい列に関するメタ情報を追加するだけなので、非常に迅速に実行されます。ほとんどの場合、これは気付かれずに発生します。ただし、移行時にこのテーブルで動作する長いトランザクションがある場合、問題が発生する可能性があります。問題の本質を理解するために、PostgreSQLでロックが単純化された方法でどのように機能するかの小さな例を見てみましょう。この側面は、他のほとんどの移行を検討するときにも非常に重要になります。
大きなテーブルがあり、そこからすべてのデータを選択するとします。データベースとテーブル自体のサイズによっては、数秒または数分かかる場合があります。

テーブル構造の変更から保護する最も弱いAccessShareロックは、トランザクション中に取得され ます。
この時点で、このテーブルに対してALTERTABLEクエリを実行しようとしている別のトランザクションが発生します。前述のように、ALTER TABLEコマンドはAccessExclusiveロックを取得しますが、これは他のロック とはまったく互換性があり ません。彼女は列に並ぶ。
このロックキューは厳密な順序で「レーキ」されます。他のクエリがALTERTABLEの後に来る場合(たとえば、SELECTも)、それ自体は最初のクエリと競合しませんが、それらはすべてALTERTABLEのキューに入れられます。その結果、アプリケーションは「立ち上がり」、ALTERTABLEが実行されるのを待ちます。
そのような状況で何をしますか?SET lock_timeoutコマンドを使用して、ロックの取得にかかる時間を制限できます 。このコマンドは、ALTER TABLEの前に実行します(LOCALキーワードは、設定が現在のトランザクション内でのみ有効であることを意味します。それ以外の場合は、現在のセッション内で有効です)。
SET LOCAL lock_timeout TO '100ms'
また、100ミリ秒以内にコマンドがロックの取得に失敗した場合、失敗します。次に、成功することを期待して再起動するか、アプリケーションにこれが含まれていない場合に、トランザクションに時間がかかる理由を調べます。いずれにせよ、重要なことは、アプリケーションをクラッシュさせなかったことです。
厳密なロックを取得するコマンドの前に、タイムアウトを設定すると便利であると言えます。
デフォルト値で列を追加する
-- PG 11
ALTER TABLE my_table ADD COLUMN new_column INTEGER DEFAULT 42
このコマンドが古いバージョンのPostgreSQL(11未満)で実行されると、テーブル内のすべての行が上書きされます。明らかに、テーブルが大きい場合、これには長い時間がかかる可能性があります。また、実行時に厳密なロック(AccessExclusive)がキャプチャされるため 、テーブルへのすべてのクエリもブロックされます。
PostgreSQLが11以降の場合、この操作は非常に安価です。事実、11番目のバージョンでは最適化が行われ、そのおかげで、テーブルを書き換える代わりに、デフォルト値が特別なテーブルpg_attributeに格納され、後でSELECTを実行すると、この列のすべての空の値がその場でこの値に置き換えられます。この場合、後で他の変更によってテーブルの行が上書きされると、値がこれらの行に書き込まれます。
さらに、11番目のバージョンから、すぐに新しい列を作成してNOTNULLとしてマークすることもできます。
-- PG 11
ALTER TABLE my_table ADD COLUMN new_column INTEGER DEFAULT 42 NOT NULL
PostgreSQLが11より古い場合はどうなりますか?
移行はいくつかのステップで実行できます。まず、制約とデフォルト値のない新しい列を作成します。前に述べたように、それは安くて速いです。同じトランザクションで、デフォルト値を追加してこの列を変更します。
ALTER TABLE my_table ADD COLUMN new_column INTEGER;
ALTER TABLE my_table ALTER COLUMN new_column SET DEFAULT 42;
この1つのコマンドの2つへの分割は少し奇妙に思えるかもしれませんが、新しい列がデフォルト値ですぐに作成されると、テーブル内のすべてのレコードに影響し、値が既存の列(この場合のように作成されたものだけであっても)は、新しいレコードにのみ影響します。
したがって、これらのコマンドを実行した後、すでにテーブルにあった値を更新する必要があります。大まかに言えば、次のようなことをする必要があります。
UPDATE my_table set new_column = 42 --
しかし、大きなテーブルを更新すると、テーブル全体が長時間ロックされるため、このようなUPDATEの「正面から」は実際には不可能です。2番目の記事(将来的にはリンクがあります)では、PostgreSQLで大きなテーブルを更新するためにどのような戦略が存在するかを見ていきますが、今のところ、何らかの方法でデータを更新し、古いデータとnewは、デフォルトで必要な値になります。
列の削除
ALTER TABLE my_table DROP COLUMN new_column --
ここでのロジックは、列を追加する場合と同じです。テーブルデータは変更されず、メタ情報のみが変更されます。この場合、列は削除済みとしてマークされ、クエリに使用できません。これは、PostgreSQLで列が削除されたときに、物理スペースが解放されない(VACUUM FULLを実行しない限り)、つまり、古いレコードのデータがテーブルに残っているが、アクセスすると使用できないという事実を説明しています。テーブルの行が上書きされると、割り当て解除が徐々に発生します。
したがって、移行自体は単純ですが、原則として、バックエンド側でエラーが発生することがあります。列を削除する前に、いくつかの簡単な準備手順を実行する必要があります。
- まず、この列にあるすべての制限(NOT NULL、CHECK、...)を削除する必要があります。
ALTER TABLE my_table ALTER COLUMN new_column DROP NOT NULL
- 次のステップは、バックエンドの互換性を確保することです。カラムがどこにも使用されていないことを確認する必要があります。たとえば、Hibernateでは、アノテーションを使用してフィールドをマークする必要があります
@Transient
。使用しているJOOQでは、タグを使用してフィールドが例外に追加されます<excludes>
。
<excludes>my_table.new_column</excludes>
また、クエリを注意深く調べる必要があります。"SELECT *"
フレームワークはすべての列をコード内の構造にマップでき(その逆も可能)、したがって、存在しない列にアクセスするという問題に再び直面する可能性があります。
変更がすべてのアプリケーションサーバーに送信されたら、列を削除できます。
インデックスの作成
CREATE INDEX my_table_index ON my_table (name) -- ,
PostgreSQLを使用している人は、このコマンドがテーブル全体をロックすることをおそらく知っています。ただし、非常に古いバージョン8.2以降、CONCURRENTLYキーワード があります。これにより、非ブロッキングモードでインデックスを作成できます。
CREATE CONCURRENTLY INDEX my_table_index ON my_table (name) --
コマンドは遅くなりますが、並列要求には干渉しません。
このチームには1つの注意点があります。失敗する可能性があります—たとえば、重複する値を含むテーブルに一意のインデックスを作成する場合です。インデックスは作成されますが、無効としてマークされ、クエリでは使用されません。インデックスのステータスは、次のクエリで確認できます。
SELECT pg_index.indisvalid
FROM pg_class, pg_index
WHERE pg_index.indexrelid = pg_class.oid
AND pg_class.relname = 'my_table_index'
このような状況では、古いインデックスを削除し、テーブルの値を修正してから再作成する必要があります。
DROP INDEX CONCURRENTLY my_table_index
UPDATE my_table ...
CREATE CONCURRENTLY INDEX my_table_index ON my_table (name)
インデックスの再構築のみを目的としたREINDEXコマンドは 、バージョン12まではブロッキングモードでのみ機能するため、使用できなくなることに注意してください。PostgreSQL 12は並行サポートを追加し、使用できるようになりました。
REINDEX INDEX CONCURRENTLY my_table_index -- PG 12
パーティションテーブルでのインデックスの作成
パーティションテーブルのインデックスの作成についても説明する必要があります。PostgreSQLには、バージョン10で登場した継承と宣言型の2種類のパーティショニングがあります。簡単な例で両方を見てみましょう。
テーブルを日付でパーティション化し、各パーティションに1年間のデータが含まれるとします。
継承による分割の場合、おおよそ次のようなスキームになります。
親テーブル:
CREATE TABLE my_table (
...
reg_date date not null
)
2020年と2021年の子パーティション:
CREATE TABLE my_table_y2020 (
CHECK ( reg_date >= DATE '2020-01-01' AND reg_date < DATE '2021-01-01' ))
INHERITS (my_table);
CREATE TABLE my_table_y2021 (
CHECK ( reg_date >= DATE '2021-01-01' AND reg_date < DATE '2022-01-01' ))
INHERITS (my_table);
各パーティションのパーティションフィールドによるインデックス :
CREATE INDEX ON my_table_y2020 (reg_date);
CREATE INDEX ON my_table_y2021 (reg_date);
テーブルにデータを挿入するためのトリガー/ルールの作成はそのままにしておきましょう。
ここで最も重要なことは、各パーティションが実質的に独立したテーブルであり、個別に管理されていることです。したがって、新しいインデックスの作成も通常のテーブルと同様に行われます。
CREATE CONCURRENTLY INDEX my_table_y2020_index ON my_table_y2020 (name);
CREATE CONCURRENTLY INDEX my_table_y2021_index ON my_table_y2021 (name);
次に、宣言型パーティショニングを見てみましょう。
CREATE TABLE my_table (...) PARTITION BY RANGE (reg_date);
CREATE TABLE my_table_y2020 PARTITION OF my_table FOR VALUES FROM ('2020-01-01') TO ('2020-12-31');
CREATE TABLE my_table_y2021 PARTITION OF my_table FOR VALUES FROM ('2021-01-01') TO ('2021-12-31');
インデックスの作成はPostgreSQLのバージョンによって異なります。バージョン10では、以前のアプローチと同様に、インデックスは個別に作成されます。したがって、既存のテーブルの新しいインデックスの作成も同じ方法で行われます。
バージョン11では、宣言型パーティション分割が改善され、テーブルが一緒に提供されるようになり ました。親テーブルにインデックスを作成すると、将来作成されるすべての既存および新規パーティションのインデックスが自動的に作成 されます。
-- PG 11 ()
CREATE INDEX ON my_table (reg_date)
これは、パーティションテーブルを作成する場合に役立ちますが、既存のテーブルに新しいインデックスを作成する場合には役立ちません。インデックスの作成中にコマンドが強力なロックを取得するためです。
CREATE INDEX ON my_table (name) --
残念ながら、CREATE INDEXは、パーティション表のCONCURRENTLYキーワードをサポートしていません。制限を回避し、ブロックせずに移行するには、次のようにします。
- ONLYオプションを使用して親テーブルにインデックスを作成する
CREATE INDEX my_table_index ON ONLY my_table (name)
このコマンドは、パーティションのインデックスを作成せずに、空の無効なインデックスを作成します。 - 各パーティションのインデックスを作成します。
CREATE CONCURRENTLY INDEX my_table_y2020_index ON my_table_y2020 (name); CREATE CONCURRENTLY INDEX my_table_y2021_index ON my_table_y2021 (name);
- パーティションのインデックスを親テーブルのインデックスにアタッチします。
ALTER INDEX my_table_index ATTACH PARTITION my_table_y2020_index; ALTER INDEX my_table_index ATTACH PARTITION my_table_y2021_index;
制限事項
次に、制約を確認してみましょう。NOTNULL、外部キー、一意のキー、および主キーです。
NOTNULL制約の作成
ALTER TABLE my_table ALTER COLUMN name SET NOT NULL --
この方法で制約を作成すると、テーブル全体がスキャンされます。すべての行でnull以外の条件がチェックされ、テーブルが大きい場合は時間がかかることがあります。このコマンドがキャプチャする強力なブロックは、完了するまですべての同時リクエストをブロックします。
何ができるの? PostgreSQLには別のタイプの制約である CHECKがあり、これを使用して目的の結果を得ることができます。この制約は、行列で構成されるブール条件をテストします。私たちの場合、条件は取るに足らないものです-
CHECK (name IS NOT NULL)
。しかし、最も重要なことは、CHECK制約が無効化(キーワード
NOT VALID
)をサポートしていること です。
ALTER TABLE my_table ADD CONSTRAINT chk_name_not_null
CHECK (name IS NOT NULL) NOT VALID -- , PG 9.2
この方法で作成された制限は、新しく追加および変更されたレコードにのみ適用され、既存のレコードはチェックされないため、テーブルはスキャンされません。
既存のレコードも制約を満たしていることを確認するには、それを検証する必要があります(もちろん、最初にテーブルのデータを更新することによって)。
ALTER TABLE my_table VALIDATE CONSTRAINT chk_name_not_null
このコマンドは、テーブルの行を反復処理し、すべてのレコードがnullではないことを確認します。ただし、通常のNOT NULL制約とは異なり、このコマンドでキャプチャされるロックはそれほど強力ではありません(ShareUpdateExclusive)。挿入、更新、および削除の操作をブロックしません。
外部キーの作成
ALTER TABLE my_table ADD CONSTRAINT fk_group
FOREIGN KEY (group_id) REFERENCES groups(id) --
外部キーが追加されると、子テーブルのすべてのレコードで親の値がチェックされます。テーブルが大きい場合、このスキャンは長くなり、両方のテーブルで保持されているロックも長くなります。
幸い、PostgreSQLの外部キーはNOT VALIDもサポートしています。つまり、前にCHECKで説明したのと同じアプローチを使用できます。無効な外部キーを作成しましょう:
ALTER TABLE my_table ADD CONSTRAINT fk_group
FOREIGN KEY (group_id) REFERENCES groups(id) NOT VALID
次に、データを更新して検証を実行します。
ALTER TABLE my_table VALIDATE CONSTRAINT fk_group_id
一意の制約を作成する
ALTER TABLE my_table ADD CONSTRAINT uk_my_table UNIQUE (id) --
前に説明した制約の場合と同様に、コマンドは厳密なロックをキャプチャします。このロックの下で、テーブル内のすべての行が制約(この場合は一意性)と照合されます。
内部的には、PostgreSQLは一意のインデックスを使用して一意の制約を適用することを知っておくことが重要です。つまり、制約が作成されると、その制約を処理するために、同じ名前の対応する一意のインデックスが作成され ます。次のクエリを使用して、制約のサービングインデックスを見つけることができます。
SELECT conindid index_oid, conindid::regclass index_name
FROM pg_constraint
WHERE conname = 'uk_my_table_id'
同時に、まったく同じものを作成するという制約のほとんどで使用さ れ、インデックスとそれに続くバインディングが非常に迅速に制限されます。さらに、すでに一意のインデックスを作成している場合は、USINGINDEXキーワードを使用してインデックスを作成することでこれを自分で行うことができます。
ALTER TABLE my_table ADD CONSTRAINT uk_my_table_id UNIQUE
USING INDEX uk_my_table_id -- , PG 9.1
したがって、考え方は単純です。前に説明したように、一意のインデックスを同時に作成し、それに基づいて一意の制約を作成します。
この時点で、疑問が生じる可能性があります -インデックスが必要なことを正確に実行するのに、なぜ制約を作成するのですか?値の一意性を保証しますか?比較から部分インデックスを除外すると 、機能の観点から、結果は実際にはほとんど同じになります。私たちが見つけた唯一の違いは、制約は延期できるが 、インデックスは延期できないということです。古いバージョンのPostgreSQL(9.4まで)のドキュメントには 脚注がありました一意性制約を作成するための好ましい方法は、明示的に制約を作成する
ALTER TABLE ... ADD CONSTRAINT
ことであり、インデックスの使用は実装の詳細と見なす必要があるという情報があります。ただし、最近のバージョンでは、この脚注は削除されています。
主キーの作成
一意であることに加えて、主キーは非NULL制約を課します。列に元々そのような制約があった場合、それを主キーに「変換」することは難しくありません。また、一意のインデックスを同時に作成し、次に主キーを作成します。
ALTER TABLE my_table ADD CONSTRAINT uk_my_table_id PRIMARY KEY
USING INDEX uk_my_table_id -- id is NOT NULL
列には「公正な」NOTNULL制約が必要であることに注意することが重要です。前述のCHECKアプローチは機能しません。
制限がない場合は、PostgreSQLの11番目のバージョンまで何もする必要はありません。ロックせずに主キーを作成する方法はありません。
PostgreSQL 11以降を使用している場合、これは、既存の列を置き換える新しい列を作成することで実現できます。だから、一歩一歩。
デフォルトではnullではなく、デフォルト値を持つ新しい列を作成します。
ALTER TABLE my_table ADD COLUMN new_id INTEGER NOT NULL DEFAULT -1 -- PG 11
トリガーを使用して、古い列と新しい列のデータの同期を設定します。
CREATE FUNCTION on_insert_or_update() RETURNS TRIGGER AS
$$
BEGIN
NEW.new_id = NEW.id;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trg BEFORE INSERT OR UPDATE ON my_table
FOR EACH ROW EXECUTE PROCEDURE on_insert_or_update();
次に、トリガーの影響を受けなかった行のデータを更新する必要があります。
UPDATE my_table SET new_id = id WHERE new_id = -1 --
上記の更新を伴うリクエストは「額に」書かれていますが、大きなテーブルではこれを行う価値はありません。長いブロッキングがあります。前述のように、2番目の記事では、大きなテーブルを更新するためのアプローチについて説明します。今のところ、データが更新され、残っているのは列を交換することだけだと仮定しましょう。
ALTER TABLE my_table RENAME COLUMN id TO old_id;
ALTER TABLE my_table RENAME COLUMN new_id TO id;
ALTER TABLE my_table RENAME COLUMN old_id TO new_id;
PostgreSQLでは、DDLコマンドはトランザクションです。つまり、列の名前を変更、追加、削除することができ、同時に、並列トランザクションはその操作の過程でこれを認識しません。
列を変更した後も、インデックスを作成して「クリーンアップ」する必要があります。トリガー、関数、古い列を削除します。
移行を含むクイックチートシート
強力なロック(ほとんどすべて
ALTER TABLE ...
)をキャプチャするコマンドの前に、次のコマンド を呼び出すことをお勧めします。
SET LOCAL lock_timeout TO '100ms'
| 移行 | 推奨されるアプローチ |
|---|---|
| 列の追加 | |
| デフォルト値[およびNOTNULL]で列を追加する | PostgreSQL 11の場合:
PostgreSQL 11より前:
|
| 列の削除 |
|
| インデックスの作成 | 失敗した場合:
|
| パーティションテーブルでのインデックスの作成 | PG 10での継承+宣言によるパーティショニング:
PG 11を使用した宣言型パーティショニング:
|
| NOTNULL制約の作成 |
|
| 外部キーの作成 |
|
| 一意の制約を作成する |
|
| 主キーの作成 | 列がISNOT NULLの場合:
PG 11で列がNULLの場合:
|
次の記事では、大きなテーブルを更新する方法について説明します。
誰でも簡単に移行できます!