
機械学習が今日解決する問題は、多くの場合複雑であり、多数の機能(機能)が含まれています。初期データは複雑で多様であるため、単純な機械学習モデルを使用しても必要な結果が得られないことがよくあります。したがって、実際のビジネスケースでは複雑な非線形モデルが使用されます。このようなモデルには重大な欠点があります。その複雑さのために、モデルがこの特定のクラスをアカウント操作に割り当てたロジックを確認することはほとんど不可能です。モデルの解釈可能性は、その作業の結果を顧客に提示する必要がある場合に特に重要です。顧客は、自分のビジネスに対してどのような基準が決定されたかに基づいて知りたいと思うでしょう。
, sklearn, xgboost, lightGBM (). , . , , ? ? , . SHAP. SHAP . , .
. , . 213 , .
kaggle .
:
%%time
# LOAD TRAIN
X_train=pd.read_csv('train_transaction.csv',index_col='TransactionID', dtype=dtypes, usecols=cols+['isFraud'])
train_id= pd.read_csv('train_identity.csv',index_col='TransactionID', dtype=dtypes)
X_train = X_train.merge(train_id, how='left', left_index=True, right_index=True)
# LOAD TEST
X_test=pd.read_csv('test_transaction.csv',index_col='TransactionID', dtype=dtypes, usecols=cols)
test_id = pd.read_csv('test_identity.csv',index_col='TransactionID', dtype=dtypes)
fix = {o:n for o, n in zip(test_id.columns, train_id.columns)}
test_id.rename(columns=fix, inplace=True)
X_test = X_test.merge(test_id, how='left', left_index=True, right_index=True)
# TARGET
y_train = X_train['isFraud'].copy()
del train_id, test_id, X_train['isFraud']; x = gc.collect()
# PRINT STATUS
print('Train shape',X_train.shape,'test shape',X_test.shape)
X_train.head()

, , , , .
, () , , . , , , .
.
:
if BUILD95:
feature_imp=pd.DataFrame(sorted(zip(clf.feature_importances_,cols)), columns=['Value','Feature'])
plt.figure(figsize=(20, 10))
sns.barplot(x="Value", y="Feature", data=feature_imp.sort_values(by="Value", ascending=False).iloc[:50])
plt.title('XGB95 Most Important Features')
plt.tight_layout()
plt.show()
del clf, h; x=gc.collect()

, , . : ? . , , . , , SHAP. , , : 20 . 50 .
:
import shap
shap.initjs()
shap_test = shap.TreeExplainer(h).shap_values(X_train.loc[idxT,cols])
shap.summary_plot(shap_test, X_train.loc[idxT,cols],
max_display=25, auto_size_plot=True)
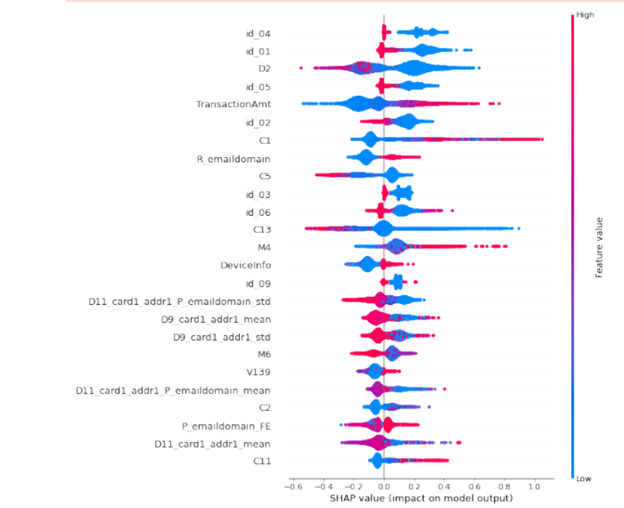
, . 2 . «0», «1». , . , . , , , : , , . , email.
得られたデータに基づいて、モデルを軽量化すること、つまり、モデルの予測結果に大きな影響を与えるパラメーターのみを残すことができます。さらに、データの特定のサブグループ(たとえば、さまざまな地域の顧客、さまざまな時間帯のトランザクションなど)の機能の重要性を評価することが可能になります。さらに、このツールを使用して、個々のケースを分析できます。たとえば、「外れ値」と極値を分析します。SHAPは、ネガティブな現象を分類するときに落下ゾーンを見つけるのにも役立ちます。このツールは、他のアプローチと組み合わせて、モデルをより軽く、より良い品質にし、結果を解釈可能にします。