表形式データ用のディープ高性能ニューラルネットワークTabNet
前書き
ディープニューラルネットワーク(GNN)は、音声認識、自然通信、コンピュータービジョン[2-3]などの人工知能システム(SRI)を作成するための最も魅力的なツールの1つになりました。特に、自動選択により重要なGNSの機能、データからの接続を定義します。ニューラルネットワークアーキテクチャ(ネオコグニトロニック、畳み込み、深い信頼など)、GNSを学習するためのモデルとアルゴリズム(オートエンコーダー、ボルツマンマシン、制御された反復など)が開発されています。 GNSは、主に勾配消失問題のためにトレーニングが困難です。
この記事では、「デシジョンツリー」を表示するように設計された表形式データ用のGNS(TabNet)の新しい正規アーキテクチャについて説明します。目標は、階層的手法(解釈可能性、まばらな特徴選択)とGNSベースの手法(段階的およびエンドツーエンドの学習)の利点を継承することです。具体的には、TabNetは、高性能と解釈可能性という2つの重要なニーズに対応します。多くの場合、高性能では不十分です。GNSは、ツリーのようなメソッドを解釈して置き換える必要があります。
TabNetは、完全に接続されたレイヤーのニューラルネットワークであり、次のようなシーケンシャルアテンションメカニズムを備えています。
トレーニングデータセットから取得した、インスタンスごとのオブジェクトのまばらな選択を使用します。
各決定ステップが、選択された機能に基づく決定の一部に寄与することができる順次多段階アーキテクチャを作成します。
選択した関数の非線形変換を通じて学習能力を向上させます。
より正確な測定とより多くの改善ステップを含む、アンサンブルをシミュレートします。
特定のアーキテクチャの各レイヤー(図1)は、特性を変換するための完全に接続されたレイヤーを備えたブロックを含むソリューションステップです。これは、機能トランスフォーマーと、入力された元の特性の重要性を判断するためのアテンションメカニズムです。

1.関数のコンバーター
1.1。バッチ正規化
- . . , (, ), , . (covariate shift).
. , — . ( ) , . , , , .
. , — , . , , ( , – ) . . - (batch normalization), 2015 [4].
- .
1. d: x = (x1, . . . , xd). k- x ( ):

2. . , . , , (

[−1, 1] ).
, :

γ, β .
3. , , -,


4. .
-:
, , ;
, ;
, ;
.
1.2. GLU
[5] Gated Linear Unit, , , LSTM-.
GLU
, , , . H = [h0 ,..., hN] w0, ... ,wN, P (wi |hi). f H hi = f(hi - 1 , wi - 1) , i ( , ).
f H = f * w , , , , , . . , , [5] , , .
. 2 . , D |V| x e, |V| - ( ), e - . w0, … , wN, E = [Dw0, … , DwN]. h0 , …hL

m, n – , , k - , X ∈ R N×m - hl ( , ),
, σ - ⊗ .
, hi . , . , k-1, , - , , k - .

X * W + b, σ(X * V + c). LSTM, X * W + b , . (GLU). E H = hL◦. . .◦h0 (E).
(GLU) , .
3.3 LSTM
LSTM (long short-term memory, – ) — , . LSTM , , [5].
LSTM . — , !
. , , tanh.
LSTM
LSTM .
LSTM , . , « ». h x 0 1 C. 1 « », 0 — « ».
. , . , . , .
, . . , « », , . tanh - C, . .
, .
C. , .
f, , . i*C. , , .
, .
, , . . , , . tanh ( [-1, 1]) .
, , , . , , ( ) .
TabNet

3.4. Split:
Feature Transformer , . , , Attentive Transformer , . (backpropagation) , «» , ( ). , . , Attentive Transformer . , "" , , .
SPLIT
: (. . 1) .
, , ( ), , .
. 3 . FC BN (GLU) , . √0.5 , , . . BN, , , BN BV mB. , , BN. , , . 3,
:
. softmax ( argmax ).
4.
. (), ( ) Softmax, , , : , - , — .
, , ht, t=1 …m, d , .
C d di−1 .
s — hi « ».
, s softmax. e=softmax(s)
softmax :
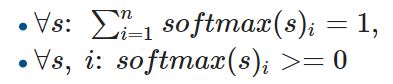
:

cc , hi ei.
. , , , , , . Softmax, Sparsemax. , , - , Softmax , . «» «» , - .
5. SPARSEMAX
, z z, . :

τ(z) S(z), p. softmax , , , softmax .
, . softmax , sparsemax :
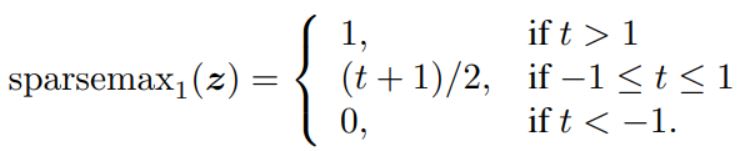
, :

, sparsemax , , :

|S(z)| - S(z).
, , , , Sparsemax.
,
6.
, , , , - . . , , . ( ), () , , , .
:
. , , , , . : M[i] · f. (. . 1) , , a[i − 1]:
Sparsemax [6] , .
,
h[i] - , . 4., FC, BN, P[i] - , , :

γ - : γ = 1, γ, . P[0] ,
- . ( ), P[0] , . :
ϵ - . λ, , .
, , . , , , - . , [5] , .
TabNet - . TabNet . , () , .
, , , .
.. // . : . 2017. .6, №3. .28–59. DOI: 10.14529/cmse170303
LeCun Y., Bengio Y., Hinton G. Deep Learning // Nature. 2015. Vol.521. Pp.436–444. DOI: 10.1038/nature14539.
Rav`ı D., Wong Ch., Deligianni F., et al. Deep Learning for Health Informatics // IEEE Journal of Biomedical and Health Informatics. 2017. Vol.21, No.1. PP.4–21. DOI: 10.1109/JBHI.2016.2636665.
Sergey Ioffe, Christian Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal // Proceedings of The 32nd International Conference on Machine Learning (2015), pp.448-456.
Sercan O. Arik, Tomas Pfister. TabNet: Attentive Interpretable Tabular Learning // ICLR 2020 Conference Blind Submission 25 Sept 2019 (modified: 24 Dec 2019). URL:https://drive.google.com/file/d/1oLQRgKygAEVRRmqCZTPwno7gyTq22wbb/view?usp=sharing
Andre F. T. Martins and Ram´on Fern´andez Astudillo. 2016. From Softmax´ to Sparsemax: A Sparse Model of Attention and Multi-Label Classification. arXiv:1602.02068.