
Apple Matrixコプロセッサ(AMX)に関する出版物はすでにかなりの数あります。しかし、ほとんどの人にとってはあまり明確ではありません。コプロセッサーのニュアンスをわかりやすい言葉で説明しようと思います。
なぜAppleはこのコプロセッサについてあまり話さないのですか?何がそんなに秘密なの?また、SoC M1のニューラルエンジンについて読んだことがある場合は、AMXの何がそれほど珍しいのかを理解するのに苦労するかもしれません。
しかし、最初に、基本的なことを覚えておきましょう( 行列が何であるかをよく知っていて、Habréにそのような読者のほとんどがいると確信している場合は、最初のセクションをスキップできます-約Transl。)。
マトリックスとは何ですか?
簡単に言えば、これは数字の表です。Microsoft Excelで作業したことがある場合は、行列の類似性を処理したことを意味します。行列と数値のある通常のテーブルの主な違いは、行列を使用して実行できる操作と、その特定の本質にあります。マトリックスは、さまざまな形で考えることができます。たとえば、文字列として、それは行ベクトルです。または、列として、それは非常に論理的には列ベクトルです。

行列の加算、減算、スケーリング、乗算を行うことができます。加算は最も簡単な操作です。各アイテムを個別に追加するだけです。乗算は少し注意が必要です。これが簡単な例です。
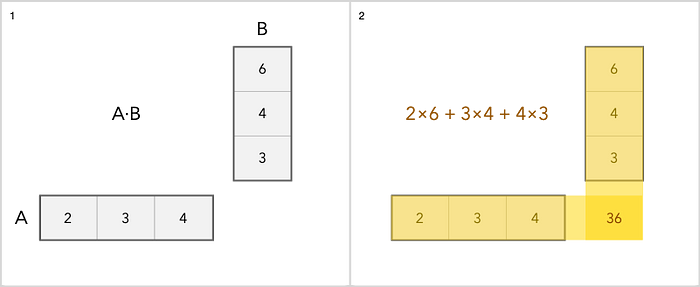
行列を使用したその他の演算については、ここで読むことができ ます。
なぜ行列について話しているのですか?
実際には、これらは次の分野で広く使用されています
。•画像処理。
•機械学習。
•手書きと音声認識。
•圧縮。
•オーディオとビデオを操作します。
機械学習に関しては、このテクノロジーには強力なプロセッサーが必要です。そして、チップにいくつかのコアを追加することはオプションではありません。これで、カーネルは特定のタスクに対して「シャープ」になります。

プロセッサ内のトランジスタの数が制限されているため、チップに追加できるタスク/モジュールの数も制限されています。一般に、プロセッサにコアを追加するだけでもかまいませんが、それによって、すでに高速な標準計算が高速化されます。そのため、Appleは別のルートを取り、画像処理、ビデオデコード、機械学習タスク用のモジュールを強調することにしました。これらのモジュールは、コプロセッサーとアクセラレーターです。
AppleMatrixコプロセッサーとNeuralEngineの違いは何ですか?
Neural Engineに興味がある場合は、機械学習の問題を処理するための行列演算も実行することをご存知でしょう。しかし、もしそうなら、なぜあなたはマトリックスコプロセッサーも必要としたのですか?多分それは同じことですか?私は何か混乱していますか?状況を明確にし、違いを説明し、両方のテクノロジーが必要な理由を説明します。
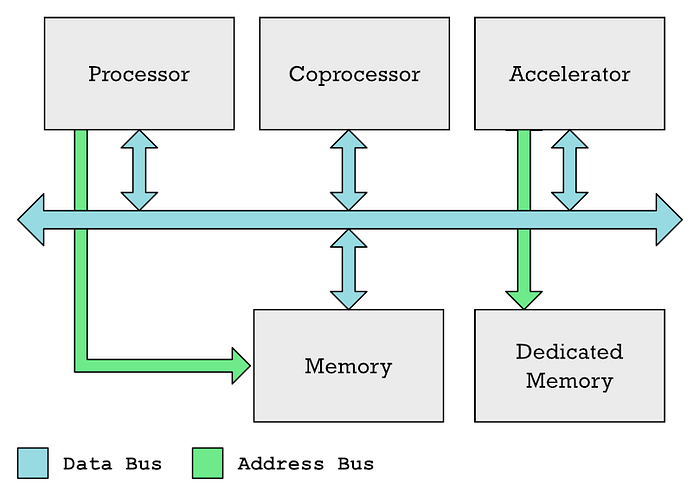
メインプロセッシングユニット(CPU)、コプロセッサー、およびアクセラレーターは、通常、共通のデータバスを介して通信できます。通常、CPUはメモリへのアクセスを制御しますが、GPUなどのアクセラレータには専用のメモリがあることがよくあります。
以前の記事では、「コプロセッサー」と「アクセラレーター」という用語を同じ意味で使用していたことを認めますが、これらは同じものではありません。したがって、GPUとニューラルエンジンは異なるタイプのアクセラレータです。
どちらの場合も、CPUが処理したいデータで満たす必要のある特別なメモリ領域と、アクセラレータが実行する必要のある命令のリストでCPUが満たす必要のあるメモリの別の領域があります。プロセッサはこれらのタスクを完了するのに時間がかかります。これらすべてを調整し、データを入力してから、結果が受信されるのを待つ必要があります。
そして、そのようなメカニズムは大規模なタスクには適していますが、小規模なタスクにはこれはやり過ぎです。

これは、アクセラレータに対するコプロセッサの利点です。コプロセッサは、メモリ(または特にキャッシュ)からCPUに送られるマシンコード命令の流れを監視します。コプロセッサーは、処理を強制された特定の命令に応答することを強制されます。一方、CPUはこれらの命令をほとんど無視するか、コプロセッサーによる処理を容易にします。
利点は、コプロセッサーによって実行される命令を通常のコードに含めることができることです。 GPUの場合、すべてが異なります。シェーダープログラムは別々のメモリバッファーに配置され、GPUに明示的に転送する必要があります。これには通常のコードを使用できません。そのため、AMXは単純なマトリックス処理タスクに最適です。
ここでの秘訣は、マイクロプロセッサの命令セットアーキテクチャ(ISA)で命令を定義する必要があるということです。したがって、コプロセッサーを使用する場合は、アクセラレーターを使用する場合よりもプロセッサーとの統合が緊密になります。
ちなみに、ARMの作成者は、ISAにカスタム命令を追加することに長い間抵抗してきました。そして、これはRISC-Vの利点の1つです。しかし、2019年に、開発者は次のように述べて諦めました。「新しい命令は標準のARM命令と組み合わされています。ソフトウェアの断片化を回避し、一貫したソフトウェア開発環境を維持するために、ARMは、クライアントが主にライブラリ呼び出しでカスタム命令を使用することを期待しています。」
これは、公式ドキュメントにAMX命令の説明がないことの良い説明かもしれません。ARMは、Appleが顧客(この場合はApple)によって提供されたライブラリに命令を含めることを単に期待しています。
マトリックスコプロセッサーとベクターSIMDの違いは何ですか?
一般に、マトリックスコプロセッサをベクトルSIMDテクノロジと混同することはそれほど難しくありません。これは、ARMを含むほとんどの最新のプロセッサに見られます。SIMDはSingleInstruction MultipleDataの略です。

SIMDを使用すると、マトリックスに密接に関連する複数の要素に対して同じ操作を実行する必要がある場合に、システムパフォーマンスを向上させることができます。一般に、ARMNeonまたはIntelx86 SSEまたはAVX命令を含むSIMD命令は、行列の乗算を高速化するためによく使用されます。
ただし、SIMDベクトルエンジンは、ALU(算術論理演算ユニット)とFPU(浮動小数点ユニット)がCPUの一部であるのと同様に、マイクロプロセッサコアの一部です。さて、すでにマイクロプロセッサの命令デコーダは、どの機能ブロックをアクティブにするかを「決定」しています。

ただし、コプロセッサーは別個の物理モジュールであり、マイクロプロセッサー・コアの一部ではありません。たとえば、以前のIntelの8087は、浮動小数点演算を高速化することを目的とした別個のチップでした。

浮動小数点命令を検出するためにメモリからプロセッサに送られるデータを処理する別のチップを備えた、このような複雑なシステムを誰かが開発するのは奇妙だと思うかもしれません。
しかし、胸は単純に開きます。事実、元の8086プロセッサには29,000個のトランジスタしかありませんでした。8087にはすでに45,000個ありましたが、最終的には、テクノロジーによってFPUをメインチップに統合し、コプロセッサーを排除することができました。
しかし、AMXがM1Firestormコアの一部ではない理由は完全には明らかではありません。たぶん、Appleは非標準のARM要素をメインプロセッサの外に移動することを決定したのかもしれません。
しかし、なぜAMXはあまり話題にならないのでしょうか。
AMXが公式ドキュメントに記載されていない場合、どうすればそれを知ることができますか? M1の素晴らしいリバースエンジニアリングを行い、コプロセッサーを発見した開発者DougallJohnsonに感謝します。彼の作品はここで説明されてい ます。結局のところ、Appleは、行列に関連する数学演算用に、Accelerateのような特殊なライブラリやフレームワークを作成しました 。これらすべてには、次の要素が含まれます。
• vImage –フォーマット間の変換、画像の操作など、より高レベルの画像処理。
• BLAS線形代数(行列とベクトルを扱う数学と呼ばれるもの)の一種の業界標準です。
• BNNS-ニューラルネットワークの実行とトレーニングに使用されます。
• vDSP-デジタル信号処理。フーリエ変換、畳み込み。これらは、画像または音声を含む信号を処理するときに実行される数学演算です。
• LAPACK–線形方程式の解法など、高レベルの線形代数関数。
Johnsonは、これらのライブラリがAMXコプロセッサを使用して計算を高速化することを理解していました。そのため、彼はライブラリのアクションを分析および監視するための専用ソフトウェアを開発しました。最終的に、彼は文書化されていないAMXマシンコード命令を見つけることができました。
また、ARM LTDが原因で、Appleはこれらすべてを文書化していない。あまり多くの情報を宣伝しないようにします。実際、カスタム関数が実際に広く使用されている場合、前述のように、これはARMエコシステムの断片化につながる可能性があります。
Appleには、これらすべてを実際に宣伝することなく、後で必要に応じてシステムの動作を変更する機会があります。たとえば、AMX命令を削除または追加します。開発者にとっては、Accelerateプラットフォームで十分であり、残りはシステムが自動的に実行します。したがって、Appleはハードウェアとソフトウェアの両方を制御できます。
AppleMatrixコプロセッサーの利点
ここにはたくさんのことがあります。要素の機能の優れた概要は、機械学習、インテリジェンス、知覚を専門とするNodLabsによって作成されました。特に、AMX2とNEONのパフォーマンス比較テストを実施しました。
結局のところ、AMXは、行列を使用した操作を2倍の速度で実行するために必要な操作を実行します。もちろん、これはAMXが最適であることを意味するのではなく、機械学習とハイパフォーマンスコンピューティングに最適です。
要するに、Appleのコプロセッサは、AppleARMに機械学習と高性能コンピューティングの優位性をもたらす印象的なテクノロジーであるということです。
