私たちの読者は、Go言語への関心の高まりに気づかずにはいられませんでした。前回の投稿の本に加えて、 このトピックに関して 興味深いことがたくさんあります 。今日は、Goでの手動メモリ管理の興味深い側面と、GoとC ++でのメモリ操作の同時実行を示す、「プロ向け」の資料の翻訳を提供したいと思います。
で Dgraph Labsの言語Goが喜んでそれが行くに間違っていないことを発表する準備ができて、5年またはゴー上のコードの200の000行の後に2015年の創業以来使用しました。この言語は、新しいシステムを作成するためのツールとしてだけでなく、従来はBashまたはPythonで記述されていたスクリプトをGoで記述することも奨励しています。 Goを使用すると、クリーンで読みやすく、保守しやすいコードのベースを作成できます。これは、最も重要なことですが、効率的で同時に処理しやすいものです。
ただし、Goには1つの問題があります。これは、作業の初期段階ですでに明らかになっています。それは、 メモリ管理です。..。 Goガベージコレクターについての苦情はありませんが、開発者の生活をどれだけ簡素化するか、他のガベージコレクターと同じ問題 があります。手動のメモリ管理と効率を競うことはできません。
メモリを手動で管理すると、メモリ使用量が少なくなり、予測可能なメモリ使用量が得られ、メモリの大きな新しいチャンクが急激に割り当てられた場合のメモリ使用量の急激な増加が回避されます。 Goでメモリを使用すると、自動メモリ管理に関する上記の問題がすべて発生します。
Rustのような言語は、安全な手動メモリ管理を提供するため、足がかりを得ることができます。これは大歓迎です。
私の経験では、ガベージコレクションツールを使用してメモリ使用量を最適化するよりも、手動でメモリを割り当てて潜在的なメモリリークを追跡する方が簡単です。手動のガベージコレクションは、事実上無制限のスケーラビリティを提供するデータベースを作成する手間をかけるだけの価値があります。
Goが大好きで、Go GCを使用してガベージコレクションを回避する必要があるため、Goでメモリを手動で管理する革新的な方法を見つける必要がありました。もちろん、ほとんどのGoユーザーは手動でメモリを管理する必要はありません。本当に必要な場合を除いて、これは避けることをお勧めし ます。そして、あなたがそれを必要とするとき- あなたはそれをする方法を知る必要があります。
Cgoでメモリを構築する
このセクションは、C配列のGoセグメントへの変換に関するCgowikiの記事をモデルにしています。goガベージコレクタからの介入を必要とせずに、mallocを使用してCでメモリを割り当て、unsafeを使用してそれをGoに渡すことができます。
import "C"
import "unsafe"
...
var theCArray *C.YourType = C.getTheArray()
length := C.getTheArrayLength()
slice := (*[1 << 28]C.YourType)(unsafe.Pointer(theCArray))[:length:length]
ただし、上記はgolang.org/cmd/cgoに記載されている警告で可能です。
: . Go nil C ( Go) C, , C Go. , C Go, Go . C, Go.
したがって、mallocの代わりに、
calloc
少し重い対応物を使用し ます。 呼び出し元に返す前にメモリをゼロにリセットするという警告がありますが、
calloc
これ
malloc
とまったく同じように機能 します。
まず、Go viaCgoにバイトセグメントを割り当てて解放するCalloc関数とFree関数を最も単純な形式で実装しました。これらの機能をテストするために、継続的なメモリ使用量テストが開発され、テストされました。 ..。このテストは、無限ループの形で、メモリ割り当て/解放サイクルを繰り返しました。最初にランダムなサイズのメモリフラグメントが割り当てられ、割り当てられたメモリの合計が16GBに達すると、これらのフラグメントは1GBのメモリのみが割り当てられるまで徐々に解放されました。 。
同等のCプログラムは期待どおりに機能しました。私たちは、
htop
その後、その後、16ギガバイトに再び成長し、1ギガバイトまで低下し、そのためには、プロセスに割り当てられたメモリの量(RSS)は最初の16ギガバイトになる方法を説明しました。ただし、Goプログラム
Calloc
は
Free
、各ループの後に、より多くのメモリを使用していました(下の図を参照)。
これは、
C.calloc
デフォルトの呼び出しに「スレッド認識」がないためにメモリが断片化されていることが原因であることが示唆されています 。これを避けるために、試してみることにしました
jemalloc
。
jemalloc
jemalloc
malloc
断片化の防止とスケーラブルな同時実行性の維持に焦点を当てた一般的な実装 です。jemalloc
2005年にFreeBSDでアロケーターとして最初に使用され、libc
その後、その予測可能な動作により、多くのアプリケーションで使用されるようになりました。- jemalloc.net
jemalloc
呼び出し
calloc
とで 使用するように APIを切り替えました
free
。さらに、このオプションは完全に機能しました
jemalloc
。メモリの断片化がほとんどないストリームをネイティブにサポートします。メモリの割り当てと割り当て解除のサイクルをテストしたメモリテストは、テストの実行に伴う小さなオーバーヘッドを除けば、合理的な範囲内にとどまりました。
jemallocを使用し、名前の競合を回避していることを強調する
je_
ために、インストール時にプレフィックスを追加し て、APIが
je_calloc
and
je_free
ではなく
calloc
andを 呼び出すようにします
free
。
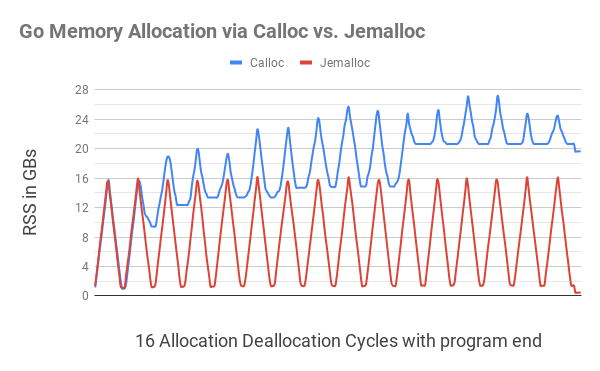
この図は、Goメモリを
C.calloc
深刻なメモリの断片化につながり、プログラムは11番目のサイクルまでに最大20GBのメモリを消費します。同等のコードで
jemalloc
は、目立った断片化は見られず、1GBに近い各サイクルに適合しました。
プログラムの終わりに近づくと(右端に小さな波紋があります)、割り当てられたすべてのメモリが解放された後でも、プログラム
C.calloc
は20GB弱のメモリを消費しましたが、
jemalloc
コストはわずか400MBでした。
jemallocをインストールするには、ここからダウンロードして、次のコマンドを実行します。
./configure --with-jemalloc-prefix='je_' --with-malloc-conf='background_thread:true,metadata_thp:auto' make sudo make install
コード全体
Calloc
は次のようになります。
ptr := C.je_calloc(C.size_t(n), 1)
if ptr == nil {
// NB: throw panic, ,
// . , – , Go,
// .
throw("out of memory")
}
uptr := unsafe.Pointer(ptr)
atomic.AddInt64(&numBytes, int64(n))
// C Go, .
return (*[MaxArrayLen]byte)(uptr)[:n:n]
このコードはリストレットパッケージに含まれています 。結果のコードがバイトチャンクを割り当てるためにjemallocに切り替えることができるように、アセンブリタグが追加されました
jemalloc
。デプロイメント操作をさらに簡素化するために
jemalloc
、適切なLDFLAGSフラグを設定することにより、ライブラリを結果のGoバイナリに静的にリンク しました。
Go構造体をバイトセグメントに分解する
これで、バイトセグメントを割り当てて解放する方法ができました。次に、それを使用してGoで構造をレイアウトします。最も単純な例(完全なコード)から始めることができます。
type node struct {
val int
next *node
}
var nodeSz = int(unsafe.Sizeof(node{}))
func newNode(val int) *node {
b := z.Calloc(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = val
return n
}
func freeNode(n *node) {
buf := (*[z.MaxArrayLen]byte)(unsafe.Pointer(n))[:nodeSz:nodeSz]
z.Free(buf)
}
上記の例では、を使用してCで割り当てられたメモリにGo構造体をレイアウトしました
newNode
。
freeNode
構造が完成するとすぐにメモリを解放できる適切な関数を作成しました 。 Go言語の構造には、最も単純なデータ型
int
と次のノード構造へのポインターが含まれてい ます。これらはすべてプログラムで設定でき、これらのエンティティにアクセスできます。 2Mノードオブジェクトを選択し、それらからリンクリストを作成して、jemallocが期待どおりに機能することを示しました。
Goのデフォルトのメモリ割り当てでは、ヒープの31 MiBが2Mオブジェクトのリンクリストに割り当てられていますが、を介して何も割り当てられていないことがわかります
jemalloc
。
$ go run . Allocated memory: 0 Objects: 2000001 node: 0 ... node: 2000000 After freeing. Allocated memory: 0 HeapAlloc: 31 MiB
アセンブリタグを使用すると
jemalloc
、30 MiBバイトのメモリがを介して割り当てられ
jemalloc
、リンクリストが解放された後、この値はゼロに低下することがわかり ます。Goはメモリから399KiBのみを割り当てます。これは、おそらくプログラム実行のオーバーヘッドが原因です。
$ go run -tags=jemalloc . Allocated memory: 30 MiB Objects: 2000001 node: 0 ... node: 2000000 After freeing. Allocated memory: 0 HeapAlloc: 399 KiB
Allocatorを使用したCallocコストの償却
上記のコードは、Goでのメモリ割り当てに最適です。 ただし、これはパフォーマンスの低下を犠牲にして行われます。で両方のコピーを駆動すると
time
、
jemalloc
プログラムなしで1.15秒で処理されたことがわかり ます。
jemalloc
彼女は5.29以上で、5倍遅くしたので 。
$ time go run . go run . 1.15s user 0.25s system 162% cpu 0.861 total $ time go run -tags=jemalloc . go run -tags=jemalloc . 5.29s user 0.36s system 108% cpu 5.200 total
この速度低下は、メモリ割り当てごとにCgo呼び出しが行われ、Cgo呼び出しごとにオーバーヘッドが発生するという事実に起因する可能性があります。これらに対処するために、アロケータのライブラリが書かれていた 、またに含まリストレット/ zのパッケージ 。 このライブラリは、1回の呼び出しでより大きなメモリセグメントを割り当てます。各セグメントは多くの小さなオブジェクトに対応できるため、高価なCgo呼び出しが不要になります。
アロケータはバッファから開始し、使い果たされるとすぐに、最初のバッファの2倍のサイズの新しいバッファを作成します。割り当てられたすべてのバッファの内部リストを維持します。最後に、ユーザーがデータを使い終わったら、Releaseを呼び出して、これらすべてのバッファーを一挙に解放できます。注:アロケーターはメモリをまったく移動しません。これにより、構造体へのすべてのポインターが引き続き機能します。
このようなメモリ管理は不器用に見え、操作方法やと比較する
tcmalloc
と
jemalloc
、このアプローチははるかに簡単です。メモリを割り当てると、1つの構造だけを解放することはできません。アロケータが使用するすべてのメモリを一度に解放することしかできません。
Allocatorが本当に得意なのは、何百万もの構造を安価に割り当て、仕事をするためにたくさんのGoを関与させることなく、仕事が終わったときにそれらを解放することです。新しいアロケータビルドタグを使用して上記のプログラムを実行すると、Goメモリバージョンよりもさらに高速に実行されます。
$ time go run -tags="jemalloc,allocator" . go run -tags="jemalloc,allocator" . 1.09s user 0.29s system 143% cpu 0.956 total
Go 1.14以降では、フラグ
-race
によりメモリ内の構造体の配置チェックが可能になります。アロケータには
AllocateAligned
メモリを返すメソッド があり、これらのチェックに合格するにはポインタを正しく配置する必要があります。構造が大きい場合、一部のメモリが失われる可能性がありますが、ワードの正しい区切りにより、CPU命令はより効率的に機能し始めます。
メモリ管理に別の問題がありました。たまたま、メモリが1つの場所に割り当てられ、まったく別の場所で解放されます。これらの2つのポイント間のすべての通信は、構造を介して実行でき、特定のオブジェクトを転送することによってのみ区別できます
Allocator
。これに対処するために、各オブジェクトに一意のIDを割り当てます。
Allocator
これらのオブジェクトは参照に保存します
uint64
。新しい各オブジェクト
Allocator
は、それ自体への参照を参照してグローバルディクショナリに格納されます。アロケータオブジェクトは、この参照を使用して呼び出し、データが不要になったときに解放できます。
リンクを適切に配置する
手動で割り当てられたメモリからGo割り当てメモリを参照しないでください。
上記のように手動で構造体を割り当てる場合、その構造体内にGo-allocatedメモリへの参照がないことを確認することが重要です。上記の構造を少し変更してみましょう。
type node struct {
val int
next *node
buf []byte
}
root := newNode(val)
上で定義した関数を使用して、ノードを手動で選択してみましょう 。次にインストール
root.next = &node{val: val}
して、リンクリスト内の他のすべてのノードをGoメモリを介して割り当てると、必然的に次のシャーディングエラーが発生します。
$ go run -race -tags="jemalloc" . Allocated memory: 16 B Objects: 2000001 unexpected fault address 0x1cccb0 fatal error: fault [signal SIGSEGV: segmentation violation code=0x1 addr=0x1cccb0 pc=0x55a48b]
Goによって割り当てられたメモリは、有効なGo構造体がそれを指していないため、ガベージコレクションの対象になります。参照はCで割り当てられたメモリからのみであり、Goヒープには適切な参照が含まれていないため、上記のエラーが発生します。したがって、構造を作成して手動でメモリを割り当てる場合は、再帰的にアクセス可能なすべてのフィールドも手動で割り当てられるようにすることが重要です。
たとえば、上記の構造がバイトセグメントを使用している場合、アロケータを使用してそのセグメントを割り当て、GoメモリとCメモリの混合を回避しました。
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = -1
n.buf = allocator.Allocate(16) // 16
rand.Read(n.buf)
ギガバイトの専用メモリを処理する方法
Allocator
何百万もの構造を手動で選択するのに適しています。ただし、数十億の小さなオブジェクトを作成して並べ替える必要がある場合もあります。 Goでこれを行うには、ヘルプがあっても
Allocator
、次のようなコードを記述する必要があります。
var nodes []*node
for i := 0; i < 1e9; i++ {
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
nodes = append(nodes, n)
}
sort.Slice(nodes, func(i, j int) bool {
return nodes[i].val < nodes[j].val
})
// .
これらの1Bノードはすべて手動で割り当てられますが
Allocator
、これはコストがかかります。また、Goの各メモリセグメントにお金をかける必要があります。これは、8GBのメモリ(ノードポインタあたり8バイト)が必要なため、それ自体が非常に高価です。
これらの実際的な状況に対処するために、
z.Buffer
メモリマップファイルが作成されているため、Linuxはシステムの必要に応じて メモリページをスワップおよびフラッシュできます。を実装し
io.Writer
、に依存しないようにし
bytes.Buffer
ます。
さらに重要なことに、それ
z.Buffer
はより小さなデータセグメントを強調する新しい方法を提供します。あなたが電話するとき
SliceAllocate(n)
、
z.Buffer
選択するセグメントの長さを記録してから、そのセグメントを
(n)
選択します。これにより
z.Buffer
、セグメントの境界を理解しやすくなり、を使用してセグメントを正しく反復できます
SliceIterate
。
可変長データのソート
並べ替えについては、最初にからセグメントオフセットを取得しようとし
z.Buffer
ました。比較のためにセグメントを参照しますが、並べ替えはオフセットのみです。オフセットを受け取ると、それ
z.Buffer
を読み取り、セグメントの長さを見つけて、このセグメントを返すこと ができます。したがって、このようなシステムでは、メモリのシャッフルに頼ることなく、セグメントをソートされた形式で返すことができます。革新的であると同時に、このメカニズムはメモリに大きなプレッシャーをかけます。これは、対象のオフセットをGoメモリにプッシュするためだけに8GBのメモリペナルティを支払う必要があるためです。
私たちの仕事を制限する最も重要な要因は、サイズがすべてのセグメントで同じではなかったことです。さらに、これらのセグメントには順番にしかアクセスできず、逆方向やランダムにはアクセスできず、オフセットを事前に計算して保存することはできませんでした。インプレースソートのほとんどのアルゴリズムは、すべての値が同じサイズであり、任意の順序でアクセスでき、それらがスワップされるのを妨げるものは何もないことを前提としています。
sort.Slice
in Goも同様に機能するため、にはあまり適していませんでした
z.Buffer
。
これらの制限を考慮すると、マージソートアルゴリズムは目前のタスクに最も適していると結論付けられました。マージソートを使用すると、バッファで作業し、操作を順番に実行できます。追加のメモリオーバーヘッドは、バッファの半分のサイズにすぎません。インデントをメモリに移動するよりも安価であるだけでなく、メモリのオーバーヘッド(バッファサイズの半分)の観点から予測可能性が大幅に向上することが判明しました。さらに良いことに、マージソートを実行するために必要なオーバーヘッドは、それ自体がメモリにマップされます。
マージソートを使用することのもう1つの非常に良い効果があります。オフセットの並べ替えでは、オフセットを繰り返し処理してバッファを処理する間、オフセットをメモリに保持する必要があります。これにより、メモリへの負荷が増大するだけです。マージソートを使用すると、列挙が開始されるまでに必要なすべての追加メモリが解放されます。つまり、バッファを処理するためのメモリが増えます。
z.Bufferは
Calloc
、を介したメモリ割り当て、およびユーザーが指定した特定の制限を超えた後の自動メモリマッピングもサポート します。したがって、このツールはあらゆるサイズのデータでうまく機能します。
buffer := z.NewBuffer(256<<20) // 256MB Calloc.
buffer.AutoMmapAfter(1<<30) // mmap 1GB.
for i := 0; i < 1e9; i++ {
b := buffer.SliceAllocate(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
}
buffer.SortSlice(func(left, right []byte) bool {
nl := (*node)(unsafe.Pointer(&left[0]))
nr := (*node)(unsafe.Pointer(&right[0]))
return nl.val < nr.val
})
// .
buffer.SliceIterate(func(b []byte) error {
n := (*node)(unsafe.Pointer(&b[0]))
_ = n.val
return nil
})
メモリリークをキャッチする
この議論全体は、メモリリークのトピックに触れなければ不完全です。結局のところ、メモリを手動で割り当てると、メモリを解放するのを忘れた場合、これらすべての場合にメモリリークが避けられなくなります。どうやってそれらを捕まえることができますか?
私たちは長い間、単純なソリューションを使用してきました。そのような呼び出し中に割り当てられたバイト数を追跡するアトミックカウンターを使用しました。この場合、を使用してプログラムに手動で割り当てたメモリの量をすばやく確認できます
z.NumAllocBytes()
。メモリテストの終わりまでにまだ余分なメモリが残っている場合は、リークを意味します。
リークを見つけることができたとき、最初にjemallocメモリプロファイラーを使用しようとしました。しかし、これが役に立たないことがすぐに明らかになりました。彼はCgoの境界にぶつかっていたため、コールスタック全体を確認できませんでした。プロファイラーに表示されるのは、同じ呼び出し
z.Calloc
と からのメモリ割り当てと解放動作だけ
z.Free
です。
Goランタイムのおかげで、発信者をキャッチして通話に
z.Calloc
マッピングする ためのシンプルなシステムをすばやく構築することができました
z.Free
。このシステムにはミューテックスロックが必要なため、デフォルトでは有効にしないことにしました。代わりに、ビルドフラグを使用しました
leak
開発者アセンブリのリークのデバッグメッセージを有効にします。したがって、リークは自動的に検出され、発生した場所を正確にコンソールに表示します。
// .
pc, _, l, ok := runtime.Caller(1)
if ok {
dallocsMu.Lock()
dallocs[uptr] = &dalloc{
pc: pc,
no: l,
sz: n,
}
dallocsMu.Unlock()
}
// , , .
// ,
// , .
$ go test -v -tags="jemalloc leak" -run=TestCalloc
...
LEAK: 128 at func: github.com/dgraph-io/ristretto/z.TestCalloc 91
出力
説明された技術の助けを借りて、中庸が達成されます。使用可能なメモリに大きく依存する重要なコードパスにメモリを手動で割り当てることができます。同時に、それほど重要ではない方法で自動ガベージコレクションを利用できます。Cgoまたはjemallocの処理があまり得意でない場合でも、Goの比較的大きなメモリチャンクでこれらの手法を使用できます。効果は同等です。
上記のすべてのライブラリは、Ristretto / zパッケージのApache2.0ライセンスの下で利用できます 。メモリテストとデモコードはcontribフォルダーにあります 。