
重複処理は、アナリストの作業で最も苦痛なトピックの1つです。私たちのプラットフォームでは、NSIの専門家の負荷を軽減し、データ処理を行う同僚の生産性を高めるために、このプロセスを可能な限り自動化しようとしています。今日は、最も一般的で基本的な参考書の1つである「counterparties」ディレクトリの例を使用して、プラットフォームが単一のゴールデンレコードの形成にどのように役立つかを見ていきます。
典型的なシナリオの1つを考えてみましょう。大規模なB2Bディストリビューターがさまざまなサプライヤーから商品を受け取り、それらをクライアント(法人)に販売するとします。人。実際には、サプライヤによるメンテナンスですべてが多かれ少なかれ良好である場合、クライアントベースの処理には専門家の専任チーム全体が必要になることがあります。これは通常、企業が複数のシステム(ERP、CRM、オープンソースなどの顧客データのソース)を使用しているためです。社内に複数の部門があり、それぞれが独自の顧客ベースを維持している場合、作業は特に困難です。同じ領域..。この場合、顧客データの一部は1つのベースの再配布で複製され、異なる顧客ベース間でも暗黙的に交差します。 ERPシステムでは、いわゆるマスターレコードを取得するために、重複レコードの深刻な処理が必要です。あなたが将来一緒に働くことができる。 Unidataプラットフォームには、重複レコードを検索して処理するための特別なメカニズムがあり、このようなタスクを正常に処理します。
始めましょう
プラットフォームは、使用されるドメインのメタモデルに基づいています。ドメインは、レジストリ、ディレクトリの構造化されたセットです。それらの属性とそれらの間の関係。これらは一緒になってドメインのデータ構造を記述します。メタモデル自体については後で説明しますが、プラットフォームで既存のデータモデルの重複レコードを操作する方法を説明します。この例では、「カウンターパーティ」のレジスタがあります。主な属性は、カウンターパーティの名前(通常は短くて完全)、TIN、KPP、法定住所と実際の住所、法人の登録住所などです。
プラットフォームは、統合メカニズムを使用して重複を処理します。統合の本質は、重複を見つけるための特定のルールを設定し、データソースを定義し、データソースごとに、ソースシステムから受信した情報の信頼レベルに関与する特別な重みを設定し、次にによって検出された重複を設定することです。システムは単一の参照レコードにマージされます。この場合、重複するレコードは検索結果から消えますが、参照レコードの履歴には残ります。すべての設定はプラットフォーム管理者インターフェースで行われ、プログラミングは必要ありません。レコードのマージが誤って行われた場合、マージを元に戻す可能性が常にあります。したがって、重複を伴う作業のほとんどはシステム自体によって引き継がれ、ユーザーはこのプロセスのみを制御できます。示された例の場合に統合メカニズムを適用することを考えてみましょう。
ユニダタプラットフォームが同社の統合バスに導入されたとしましょう。統合バスは、CRMシステム、ERPシステム、およびモバイル販売システムからカウンターパーティに関するデータを受信します。プラットフォームは、重複を削除し、データを強化および調和してから、参照レコードを受信システムに転送します。
ケース1.TINとKPPのマッチング
重複するカウンターパーティを見つける最も簡単な方法は、TINとKPPで比較することです。ほとんどの場合、1つのTINでも十分です。重複レコードを検索するためのこのようなルールを実装するには、INN属性とKPP属性の完全一致ルールを設定するだけで十分です。
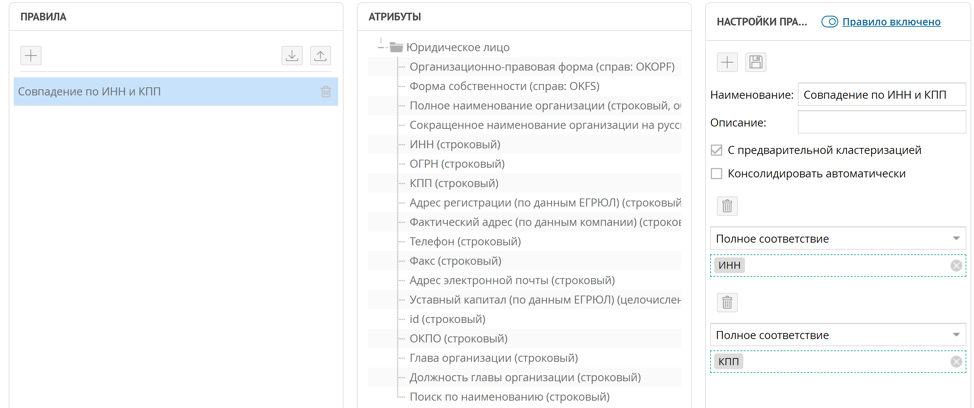
このルールによれば、新しいレコードがプラットフォームに到着すると、ルールが「事前クラスタリング」に設定されている場合、構成された重複検索ルールが自動的に起動されます。 INNとKPPの一致によって検出されたすべてのレコードのタプルは、重複クラスターに収集されます。重複クラスターウィンドウで、Unidataを使用すると、重複レコードからマスターレコードを作成できます。
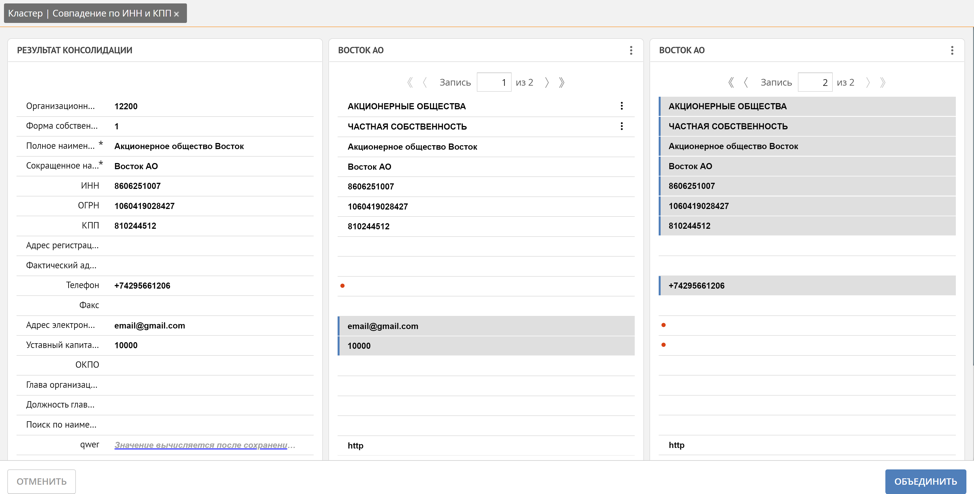
ここで、ユーザーはどのレコードが自動的に参照になるかを手動で追跡し、必要に応じて、参照レコードに含める必要がある重複レコードの属性の値を手動でマークするか、レコード全体をマークすることで修正できます。さらに、Unidataは、同様のレコードに基づいて欠落値を強化するためのメカニズムをサポートしています。たとえば、電話、郵便、株式資本は、2つの異なる重複レコードから自動的に取得されました。
すでに述べたように、プラットフォームは、重複のクラスターを形成するときに、参照レコードがどのように形成されるかを自動的に決定します。これは、前述のソースシステムの信頼の重みによるものです。レコードが由来するシステムの重みが高いほど、その属性の値は参照レコードにとってより重要です。ただし、特定のソースシステムの特定の属性の値が他のすべての属性よりも優先される場合がよくあります。たとえば、クライアントの実際の配信アドレスを、クライアントの領域で直接ネゴシエートするエージェントに信頼します。住所を正確に知っています。つまり、この例ではモバイル販売システムです。このような問題を解決するために、プラットフォームには、データソースだけでなく、各データソースのコンテキストでのレコード属性にも重みを設定する機能があります。この重みの組み合わせにより、参照レコードを生成するためのルールを柔軟に構成できます。

ケース2.法人名によるあいまいな対応
TINは必須の属性ですが、クライアントの情報が長期間更新されておらず、組織的および法的形式が変更されたと仮定します。この場合、異なるTINのエントリがすでにプラットフォームに到着し、TINの一致は機能しません。この場合、プラットフォームでは、属性の値(この場合は法人の名前)によってあいまい一致ルールを形成できます。

この操作は非常にリソースを消費するため、あいまい検索には予備的なクラスタリングがありません。つまり、新しいレコードが追加されても、このルールはすぐには機能しません。あいまい検索ルールを開始するには、重複を検索する特別な操作を使用します。これは、管理者またはシステムによってスケジュールに従って手動で開始されます。重複が見つかった後、形成されたクラスターは、データオペレーターインターフェイスの特別なセクションで表示できます。
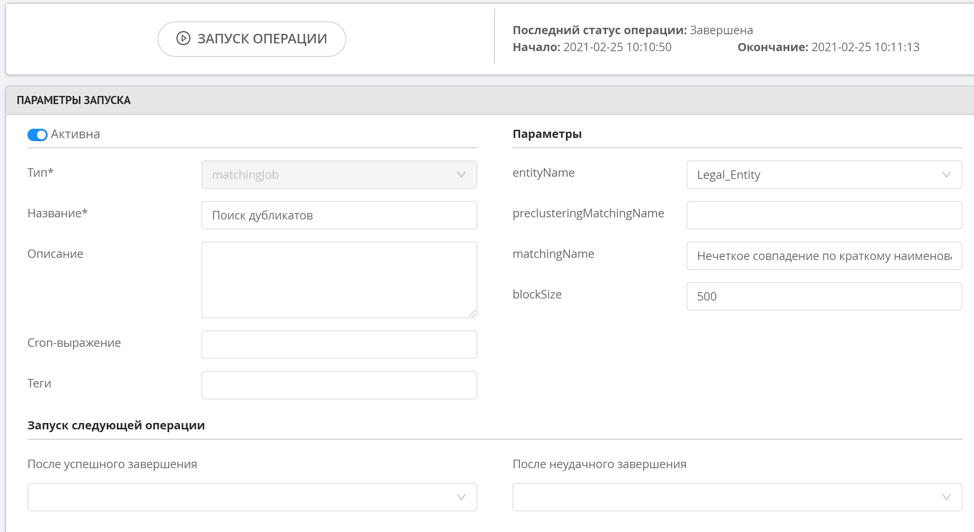

ファジー重複検索は、1〜2文字異なる、または2つ以下の順列(レーベンシュタイン距離)を必要とする類似の文字列値を決定するように機能します。nグラムで検索する可能性もあります。このアプローチにより、文字列が互いに非常に異なる場合に可能なすべての文字列操作を計算するためのリソースをロードせずに、高精度で類似のレコードを見つけることができます。
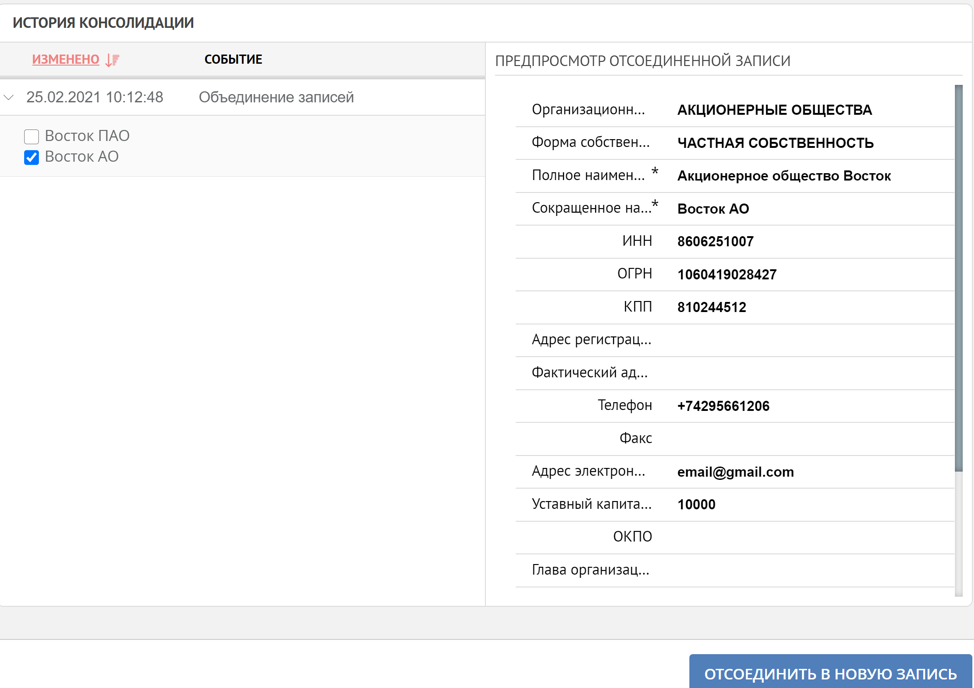
したがって、単純な典型的なケースで、重複レコードを処理するときのプラットフォームの原則を示しました。重複処理は、完全にユーザーの制御下で実行することも、自動的に実行することもできます。データの統合が誤って行われた場合、冒頭で述べたように、システムは常に参照レコードの形成の履歴を表示し、必要に応じて逆のプロセスを開始する機会があります。
私たちはそれだけにとどまらず、重複を処理する際に新しいアルゴリズムとアプローチを研究し、さまざまなエンタープライズシステムで最高のデータ品質を確保するよう努めています。