みなさん、こんにちは。データサイエンスがCOVID-19を予測するために何を提供できるかについてのこのシリーズの記事を続けます。最初の記事は こちらです。今日は、COVID-19の蔓延のダイナミクスを予測するための2番目のクラスのモデルについて説明します。それらは発生率の増加についての仮定に基づいており、中長期的な状況を説明しています。CFTシニアデータエンジニアのNikolayKobaloと話をしています。
私たちの状況を思い出してみましょう。
与えられたもの:巨大なデータサイエンス能力、3人の才能あるスペシャリスト。
見つける: 1週間先のCOVID-19の広がりを予測する方法。
2番目の解決策に移りましょう。
-コリャ、こんにちは。この問題を解決するために使用したモデルを教えてください。
-私は、私の意見では、その機会に最も適したモデルの1つを採用しました。モデルは微分方程式の形式で表され、次の4つの関数で構成され
ます。1。この感染症に感染しやすい人の数。
2.保因者、つまり、すでに感染しているが、まだ感染していない人の数。
3.他人に感染する病気の人の数。
4.回収された数。
ご覧のとおり、このモデルはcovidによる死亡率を考慮していません。モデルの詳細は私のgithubで見ることができます: https://github.com/rerf2010rerf/COVID-19-forecast/blob/master/public.ipynb
このモデルはSEIRと呼ばれ、流行の広がりを説明するコンパートメントモデルのファミリーに属しています。このファミリのモデルでは、さまざまな種類の感染を説明できます。たとえば、免疫が発達している(または逆に発達していない)もの。または、潜伏期間がある(またはない)人。 COVID-19の場合、潜伏期間と病気の人に生じた免疫力を備えたモデルを使用しました。
すべての一夫多妻制モデルは、一次微分方程式のシステムです。 SEIRの場合、次のようになります。

ここで:
S(t)-(感受性)-感染しやすい人の数。
E(t)-(露出)-キャリアの数、つまり潜伏期間のために病気がまだ現れていない感染者。
私(t)-(感染性)-感染しました。
R(t)-(回復済み)-回復済み。
N = S + E + I + R-人口サイズ。それは一定のままです、すなわち誰もこの病気で死ぬことはないと想定されています。
μは自然死亡率です。
αは、病気の潜伏期間の逆数です。
γは平均回復時間の逆数です。
βは、感染につながる接触の強度の係数です。
SEIRモデルの個人のライフサイクルは次のようになります。

健康であるがまだ病気ではない人(感受性)は、感染した(感染性)人から感染する可能性があります。健康な人が感染する確率は、βパラメータで表されます。
感染者は感染キャリア(暴露)の状態になります。保因者とは、病気がまだ現れていない、つまり潜伏期間がある人のことです。運送業者は誰にも感染できません。病気にかかりやすい人々の保因者の状態への移行は、モデルの最初の2つの方程式によって記述されます(用語β(I / N)を使用)。
感染後1 /α日(潜伏期間)後、保菌者は感染状態(感染性)になります。
1 /γ日(回復時間)後、感染者は回復状態になります。回復した人は免疫力を発達させ、もはやこの感染症にかかることはありません。
このモデルは、母集団内の母集団の自然死亡率も提供します。 SEIRモデルの死亡率は出生率とバランスが取れているため、総人口は変化しません。同時に、新生児には免疫がないため、人口の回復した人々の数は減少します。したがって、人口の中で回復した人々の数は時間とともに減少します。死亡率はパラメータμで表されます。
-モデルに係数があります。それで、あなたは何か仮定をしましたか?
-私の仮定の1つは、人口の自然死亡率は無視できるということでした。 μ= 0。この仮定は有効と思われます。これは、感染の広がりを数か月という短期間で予測したいためです。
さらに、選択されたモデルは、回復した人が感染の影響を受けなくなる、つまり、再び感染することはできないと想定しています。
-ちなみに、これはそうですか?
-そうですね。いくつかの再感染がすでに記録されていますが、ほとんどの場合、これは発生しません。したがって、そうだと言えます。
-そして、あなたの「接触強度係数」は何ですか?
「ここで私は人々が互いに接触して感染する強さを意味します。大まかに言えば、これは、一方が感染し、もう一方が感染していない2人が出会ったときに、2人目が最終的に病気になる確率です。
- いくらですか? 1つに近い?
-いいえ、データに応じてこのパラメータを選択しました。それは自己隔離のレベルに依存します。たとえば、人口の大部分が他の人と接触しない場合、係数は低くなり、人口が活発に相互に通信する場合、係数は増加します。
- はい。回復時間もありますか?アルファとガンマの両方?
-私は1 / 5.1に等しいアルファを取りました、これはCOVID-19の既知のパラメーターでした(日数での潜伏期間の逆パラメーター)。そして、データに応じて色域を選択しました。これが「回復期」です。ちなみに、「接触の強さ」もデータに基づいています。
- しかたがない。それでは、モデルによってどのような仮定がなされているかを教えてください。各方程式はどういう意味ですか?
-最初の式は、感染しやすい数の変化を表しています。特に、第3項は、感染者と感受性者との接触が強ければ強いほど、感受性者の数が早く減少することを示しています。さらに、誰かが感染し、その後感染した場合、その人はこの数に含まれなくなります。流行の初めには、それは人口の人々の数に等しいです。
次に、感染しやすい人からキャリアの数を取得します。つまり、人は感染した人と通信し、感染し、感染のキャリアになります。これは、2番目の式で説明されています。保菌者の成長率が高いほど、感受性者と感染者との接触が強くなり、逆に、現時点で残っている保菌者が少なくなると言われています。
3番目の式は、感染者の成長率が高いほど、現在(感染している)キャリアが多くなり、感染が少ないほど、すでに感染していることを示しています。
4番目の式は、回復した人の成長率を表しています。回復率が高いほど、感染が多くなり(回復できる人)、回復が少ないほど、すでに回復しています。
-状況の進展の説明のように聞こえます。
-実際には、さまざまなモデルがあります。これがSEIRモデルであり、感染しにくいSIRがあります。より多くのパラメーターを持つモデルがあります。感染による死亡率を提供するモデルがありますが、私はそれを使用しませんでした。
-このモデルはどこで見つけましたか?
-グーグル。ウィキペディアに記事があります。追加の記事が見つかりました。
-グラフィックも提示しました。
-このグラフは一例です。実際のデータに基づくものではありません。モデルがどのように動作するかを示しているだけです。彼女は、誰もが最終的に病気になり、元気になると予測しています。

-さて、あなたはそれをすべて取りました、そしてそれから何ですか?
-国別のデータを取得しました。彼は死亡率がゼロであると仮定しました。有限差分の形でdifoursを書き直しました。

このソリューションの有限差分演算子として、両側差分が使用されます。
初期データには、1日あたりの回収者数Rが記載されており、感染したIの数は、確認された症例数から回収者数を引いた数に等しい。したがって、最後の式から、MALE目的関数(ΔR-γI)を最適化することでγを見つけることができます。
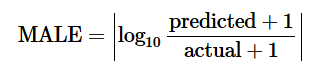
検疫措置がエピデミックの進展にどのように影響するかを追跡するために、私は自分のタスクを少し複雑にし、β係数をβ(t)関数に置き換えました-結局、検疫が国に導入されると、感染率は低下するはずです、つまり、この場合、βは一定ではありません。 difurを解くためのすべての初期条件がすでにあるので、最適化を使用して関数β(t)を見つけることができます。
-今日は違いの日ですか?
-日から前日を引いたもの。データをプラグインして、未知の係数を計算しました。
-ベータとガンマ?
-アルファ5。1日かかりました。したがって、ベータとガンマ、つまり接触の強さと回復の時間を見つける必要がありました。
-そして、あなたはどうなりましたか?
-グラフがあります。それぞれの地域とそれぞれの国は異なっていることが判明しました。国ごとに分けて決めました。左側はデータのグラフです(黒-それは本物で、赤-感染して回復し、モデルによって予測されました)。感染+回復-E + Rであることが判明しました。右側はベータ係数のグラフです。ちなみに、ベータは時間に依存することになっています。ここで、βの最大のジャンプは、3月30日の検疫の時間と一致します。
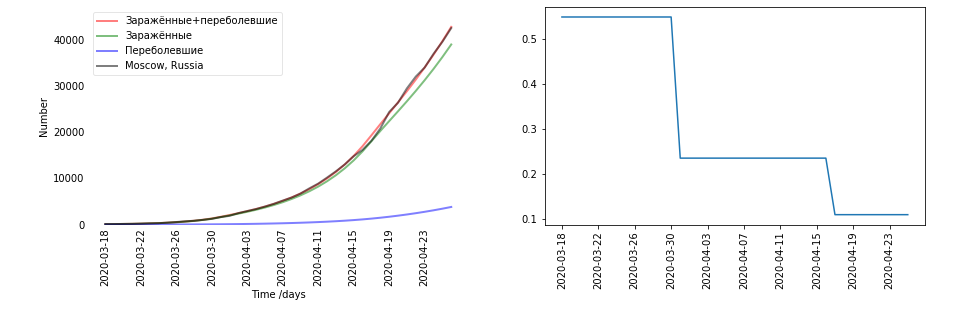
-そして、あなたはそれをデータに従って数えましたか、それともそう仮定しましたか?
-これはすでにデータに基づいて計算されています。これはまさにモスクワでの訓練の結果です。
-時間のしきい値を自分で設定しましたか?
-関数はこんな二段式だと思いました。そして最適化。データを適合させて、最適な関数を見つけます。また、ラングの数が異なる関数を使用してみましたが、2段階の関数の方が良い結果が得られました。
-たとえば、イタリアなどの国を見てみましょう。さて、ここであなたは別の絵を持っています

...-イタリアでは、検疫は明らかにうまくいきました。そして、病気になっている人が増えています。モデルは、検疫が3月9日に導入されたことを確認しました。
-最終的な予測には何を選びましたか?
-最終的な予測では、一定の接触強度を選択し、最後の2つのポイントを使用してモデルを作成しました。つまり、私たちは以前の歴史全体を知っていますが、最後のポイントだけを取ります。
-これはその週の予測ですか?
- はい。そして、以前に起こったことは、モデルがどのように動作するかを確認することでした。そして、私はすでにどの機能をとるのが良いか、そしていくつのポイントを研究するべきかを見ました。
-おそらく、これまでの予測をしたいのであれば、別の決定を受け取ったでしょう。状況がさらに発展する方法を示す何かがありますか?
- はい。しかし、そこではあまり面白くありません。彼女はモスクワの誰もが9月までに病気になるだろうと予測した。
-あるミートアップで、あなたの予測によれば、ピークは7月にあるはずだとあなたは言いました。実際、すべてが少し早く起こった。モデルが考慮しなかったものは何だと思いますか?
-おそらくベータ版。おそらく、検疫が強化されています。人々が病気で、感染せず、感染しないという事実のために、接触の強度が低下した可能性があります。ベータはどういうわけかそれに依存する必要があります。そしてここではそれは考慮されていません。
-つまり、1つのベータですべてを規制できるということですか?
-既知のデータによると-はい、ベータとガンマを調整することで可能です。
-あなたのモデルは次の波を予測していますか?
-いいえ、すべてが安定しています。成長し、成長し、成長し、誰もが病気になります。季節性の要素もありますが。たとえば、秋の時期(インフルエンザなどで免疫力が低下したとき)。しかし、モデルはこれらすべてを考慮に入れていません。
-モデルの長所と短所は何ですか?
-モデルのコンパイル時には、既知のデータはほとんどありませんでした。現在、回復期間と潜伏期間の両方がすでにわかっています(当時は5.1でしたが、今ではより正確に測定されています)。プロから:それはプロセス自体、それがどのように進むかを示しています。また、イタリア、ドイツなどの他の国の例で、これらのベータがどのように影響したかをさらに詳しく調査すると、このモデルを改良して、より正確な長期予測を作成することができます。
, data science – .
, , . - – , , , , .
, , . .彼は最もクールなモデルを作りました;)