ただし、完全にアセンブリ言語でプログラムを作成することは、長く、退屈で困難なだけでなく、ややばかげています。これは、開発時間を短縮し、プログラミングプロセスを簡素化するために、この目的のために高水準の抽象化が考案されたためです。したがって、ほとんどの場合、個別に最適化された関数はアセンブリ言語で記述され、C ++やC#などの高級言語から呼び出されます。
これに基づいて、最も便利なプログラミング環境は、すでにMASMが含まれているVisualStudioになります。masmの横にあるチェックボックスをオンにすると、[ビルドの依存関係-ビルドのカスタマイズ...]プロジェクトのコンテキストメニューからC / C ++プロジェクトに接続でき、アセンブラープログラム自体が.asmのファイルに配置されます。拡張機能(アイテムタイプをMicrosoft Macro Assemblerに設定する必要があるプロパティ)。これにより、不要なジェスチャなしでアセンブリ言語プログラムをコンパイルおよび呼び出すことができるだけでなく、エンドツーエンドのデバッグを実行して、c ++またはc#(アセンブリリスト内のブレークポイントを含む)から直接アセンブラソースに「フォールスルー」することができます。 、およびウォッチウィンドウの通常の変数とともにレジスタの状態を追跡します。
構文の強調表示
Visual Studioには、アセンブラーやその他の最新のIDE構造の成果のための組み込みの構文強調表示がありません。ただし、サードパーティの拡張機能を提供することはできます。
AsmHighlighterは、歴史的に、最小限の機能と不完全なコマンドセットを備えた最初のものです。AVXが欠落しているだけでなく、いくつかの標準的なもの、特にfsqrtも欠落しています。この事実により、私は独自の拡張機能である
ASM AdvancedEditorを作成するようになりました 。コードセクションの強調表示と折りたたみ(コメント "; ["、 "; [+"、 ";]"を使用)に加えて、コードにカーソルを合わせるとポップアップするレジスタにヒントをバインドします(コメントも使用)。次のようになります。
;rdx=
またはこのように:
mov rcx, 8;=
コマンドのヒントもありますが、実験的な形式です。拡張機能自体を作成するよりも、コマンドを完全に入力する方が時間がかかることがわかりました。
また、コードの強調表示されたセクションに注釈を付けたりコメントしたりするための通常のボタンが機能しなくなったことが突然判明しました。したがって、この機能が同じボタンにぶら下がっている別の拡張機能を作成 する必要があり、このアクションまたはそのアクションの必要性が自動的に選択されます。
Asm男-少し遅れて現れました。その中で、作者は別の方法で、タグの追跡を含む、組み込みのコマンド参照とオートコンプリートに注力しました。コード折り畳みもそこにあります(「#region / #endregion」による)が、コメントのレジスターへのバインドはまだないようです。
32対。64
64ビットプラットフォームが登場して以来、2つのバージョンのアプリケーションを作成することが一般的になっています。これをやめる時が来ました!どのくらいの遺産を引き出すことができますか。同じことが拡張機能にも当てはまります。博物館ではSSE2のないプロセッサしか見つかりません。さらに、SSE2がないと64ビットアプリケーションは機能しません。プラットフォームごとに最適化された関数の4つのバリアントを作成する場合、プログラミングの喜びはありません。
64ビットプラットフォームの利点は、「ワイド」レジスタにはまったくありませんが、これらのレジスタの数が2倍になっているという事実は、汎用とXMM / YMMの両方でそれぞれ16個です。これにより、プログラミングが簡素化されるだけでなく、メモリアクセスが大幅に削減されます。
FPU
以前はFPUなしではどこにもありませんでした、tk。実数の関数は結果をスタックの一番上に残し、64ビットプラットフォームでは、SSE2拡張のxmmレジスタを使用して参加せずに交換が行われます。Intelはまた、ガイドラインでSSE2を優先してFPUを廃止することを積極的に推奨しています。ただし、注意点があります。FPUを使用すると、80ビットの精度で計算を実行できます。これは場合によっては重要になる可能性があります。したがって、FPUのサポートはどこにも行き渡っておらず、時代遅れのテクノロジーと見なす価値はありません。たとえば、斜辺の 計算は、オーバーフローを恐れることなく「正面から」行うことができます。
つまり
fld x fmul st(0), st(0) fld y fmul st(0), st(0) faddp st(1), st(0) fsqrt fstp hypot
FPUのプログラミングにおける主な問題は、スタックの編成です。簡単にするために、スタックの現在の状態でコメントを自動的に生成する小さなユーティリティが作成されまし た(構文の強調表示のために、同様の機能をメインの拡張機能に直接追加することが計画されていましたが、それを回避することはできませんでした)
最適化の例:ハートレー変換
最新のC ++コンパイラは、配列内の数値の合計やベクトルの回転などの単純なタスクのコードを自動的にベクトル化し、コード内の対応するパターンを認識するのに十分なほどスマートです。したがって、プリミティブタスクでパフォーマンスを大幅に向上させることは、機能しないことではありません。逆に、超最適化されたプログラムは、コンパイラが生成したものよりも実行速度が遅いことが判明する場合があります。しかし、これから広範囲にわたる結論を引き出すべきではありません-アルゴリズムがもう少し複雑になり、最適化が明確でなくなるとすぐに、コンパイラーを最適化する魔法はすべて消えます。 2021年に手動で最適化することで、パフォーマンスを10倍に向上させることは可能です。
したがって、タスクとして、アルゴリズムを使用します(遅い) ハートレー変換:
コード
static void ht_csharp(double[] data, double[] result)
{
int n = data.Length;
double phi = 2.0 * Math.PI / n;
for (int i = 0; i < n; ++i)
{
double sum = 0.0;
for (int j = 0; j < n; ++j)
{
double w = phi * i * j;
sum += data[j] * (Math.Cos(w) + Math.Sin(w));
}
result[i] = sum / Math.Sqrt(n);
}
}
自動ベクトル化(後で説明します)にとっても非常に簡単ですが、最適化の余地が少しあります。最適化されたバージョンは次のようになります。
コード(コメントは削除されました)
ht_asm PROC local sqrtn:REAL10 local _2pin:REAL10 local k:DWORD local n:DWORD and r8, 0ffffffffh mov n, r8d mov r11, rcx xor rcx, rcx mov r9, r8 dec r9 shr r9, 1 mov r10, r8 sub r10, 2 shl r10, 3 finit fld _2pi fild n fdivp st(1), st fstp _2pin fld1 fild n fsqrt fdivp st(1), st ; mov rax, r11 mov rcx, r8 fldz @loop0: fadd QWORD PTR [rax] add rax, 8 loop @loop0 fmul st, st(1) fstp QWORD PTR [rdx] fstp sqrtn add rdx, 8 mov k, 1 @loop1: mov rax, r11 fld QWORD PTR [rax] fld st(0) add rax, 8 fld _2pin fild k fmulp st(1),st fsincos fld1;=u fldz;=v mov rcx, r8 dec rcx @loop2: fld st(1) fmul st(0),st(4) fld st(1) fmul st,st(4) faddp st(1),st fxch st(1) fmul st, st(4) fxch st(2) fmul st,st(3) fsubrp st(2),st fld st(0) fadd st, st(2) fmul QWORD PTR [rax] faddp st(5), st fld st(0) fsubr st, st(2) fmul QWORD PTR [rax] faddp st(6), st add rax, 8 loop @loop2 fcompp fcompp fld sqrtn fmul st(1), st fxch st(1) fstp QWORD PTR [rdx] fmulp st(1), st fstp QWORD PTR [rdx+r10] add rdx,8 sub r10, 16 inc k dec r9 jnz @loop1 test r10, r10 jnz @exit mov rax, r11 fldz mov rcx, r8 shr rcx, 1 @loop3:;[ fadd QWORD PTR [rax] fsub QWORD PTR [rax+8] add rax, 16 loop @loop3;] fld sqrtn fmulp st(1), st fstp QWORD PTR [rdx] @exit: ret ht_asm ENDP
注意:ループ展開、SSE / AVX、コサインテーブル、「高速」変換アルゴリズムによる複雑さの軽減はありません。唯一の明示的な最適化は、FPUレジスタで直接アルゴリズムの内部ループでの正弦/余弦の反復計算です。
積分変換について話しているので、速度に加えて、計算の精度と累積誤差のレベルにも関心があります。この場合、計算は非常に簡単です。2つの変換を続けて実行することにより、(理論的には)初期データを取得する必要があります。実際には、それらはわずかに異なり、分析結果から得られた結果の標準偏差から誤差を計算することが可能になります。
c ++プログラムの自動最適化の結果は、コンパイラのパラメータ設定と有効な拡張命令セット(SSE / AVXなど)の選択にも大きく依存します。ただし、2つのニュアンスがあります。
- 最近のコンパイラは、コンパイル段階で可能なすべてを計算する傾向があります。したがって、アルゴリズムの代わりにコンパイルされたコードで、事前に計算された値を確認することは非常に可能です。これにより、パフォーマンスを測定するときに、コンパイラに100500の利点がもたらされます。回数。これを回避するために、私の測定では外部関数zero()を使用します。これにより、入力パラメーターがあいまいになります。
- « AVX» — , AVX. . – , AVX .
最も興味深い最適化パラメーターは浮動小数点モデルです。これは、正確|厳密|高速の値を取ります。 Fastの場合、コンパイラーはその裁量で任意の数学的変換(反復計算を含む)を実行できます。実際、このモードでのみ自動ベクトル化が行われます。
したがって、Visual Studio 2019コンパイラ、AVX2ターゲットフレームワーク、浮動小数点モデル=正確です。さらに興味深いことに、10,000個の要素の配列でc#プロジェクトから測定します
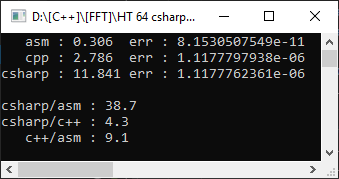
。C#は、予想どおり、C ++よりも低速であり、アセンブラー関数は9倍高速であることが判明しました。ただし、喜ぶには時期尚早です。浮動小数点モデル=高速に設定しましょう。

ご覧のとおり、これはコードを大幅に高速化するのに役立ち、手動最適化からの遅延はわずか1.8倍でした。しかし、変わっていないのはエラーです。他のオプションでは有効数字4桁のエラーが発生しました。これは、数学計算で重要です。
この場合、私たちのバージョンはより速く、より正確であることがわかりました。しかし、これは常に当てはまるわけではありません。結果を保存するためにFPUを選択すると、ベクトル化による最適化の可能性が必然的に失われます。また、理にかなっている場合にFPUとSSE2を組み合わせることを禁止する人は誰もいません(特に、乗算中に10倍のスピードアップを受けた、ダブルダブル演算の実装でこのアプローチを使用し ました)。
ハートレー変換のさらなる最適化は別の平面にあり、(任意のサイズの場合)Bluesteinアルゴリズムが必要です。これは、中間計算の精度にとっても重要です。このプロジェクトはGitHubからダウンロードできます。 ボーナスとして、FPU / SSE2 / AVX(教育目的)の配列を合計/スケーリングするための関数もいくつかあります。
何を読むか
アセンブラに関する文献をまとめて。ただし、いくつかの重要な情報源があります
。1.Intelの 公式ドキュメント。余計なことは何もありません。タイプミスの可能性は最小限です(印刷された文献ではどこにでもあります)。
2. 公式ドキュメントから取得したオンラインディレクトリ。
3. 最適化の専門家として認められているAgnerFoghのサイト。組み込み関数を使用して最適化されたC ++コードのサンプルも含まれています。
4. シンプルなFPU。
5.40 アセンブリ言語プログラミングの基本的な実践。
6.64 ビットバージョンのWindowsのプログラミングを開始するために知っておく必要のあるすべてのこと。
付録:組み込み関数を使用しないのはなぜですか?
隠しテキスト
, , , - — , SIMD- . — .
:
:
- . DOS , – .
- . – .
- . , , (FPU). . , //etc.
- - – , , . , , .
- , C++ , - SIMD-. 32- XMM8 XMM0 / XMM7 – . — , , , . – , C++.
- , . , – Microsoft , C++.