この記事は私のような初心者を対象と しています。
開始
まず、問題を見てみましょう。私自身もこの国に住んでいるので、あまり知られていないイスラエルのニュースサイトを利用しました。広告なしでニュースを読みたいので、面白いニュースではありません。それで、ニュースを掲載しているサイトがあります。赤でマークされたニュースと普通のニュースがあります。普通のものは何も面白くなく、赤でマークされたものはまさにジュースです。私たちのサイトを考えてみましょう。
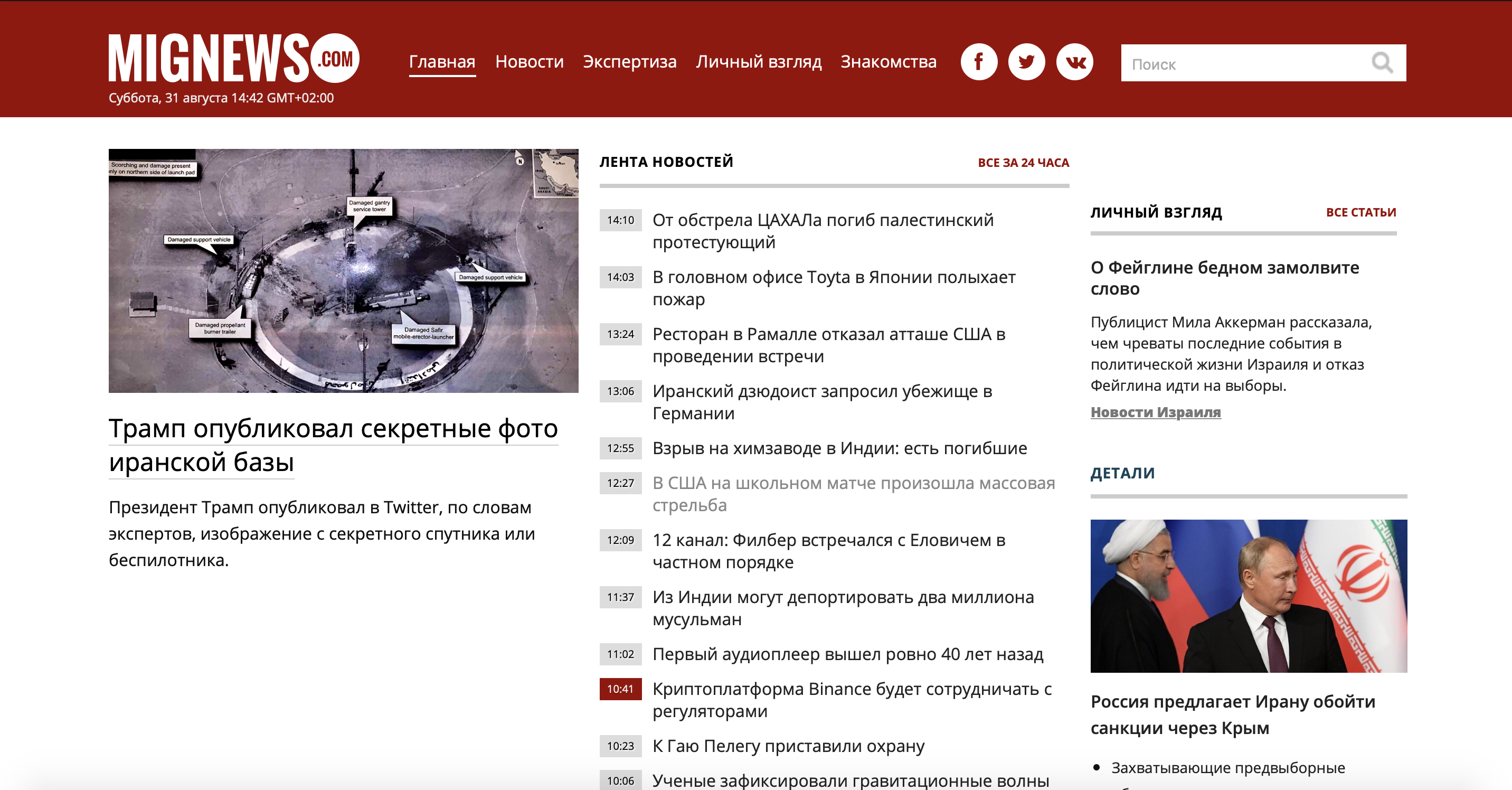
ご覧のとおり、サイトは十分に大きく、不要な情報がたくさんありますが、ニュースコンテナを使用するだけで済みます。モバイル版のサイト
を使用して、同じ時間と労力を節約しましょ う。

ご覧のとおり、サーバーは広告やゴミのない美しいニュースのコンテナを提供してくれました(ちなみに、これはメインサイトよりも多く、私たちに有利です)。
私たちが何を扱っているのかを理解するために、ソースコードを見てみましょう。

ご覧のとおり、各ニュースは別々に「a」タグにあり、「lenta」クラスがあります。「a」タグを開くと、「span」タグの中に「time2」または「time2time3」クラスと公開時刻が含まれていることがわかります。タグを閉じると、次のように表示されます。ニューステキスト自体。
重要なニュースと重要でないニュースを区別するものは何ですか?同じクラス「time2」または「time2time3」。「time2time3」とマークされたニュースは私たちの赤いニュースです。タスクの本質は明らかなので、練習に移りましょう。
練習
パーサーを操作するために、賢い人々は「BeautifulSoup4」ライブラリーを思いつきました。これには、より多くのクールで便利な機能がありますが、次回はさらに多くの機能があります。また、さまざまなhttpリクエストを送信できるRequestsライブラリも必要です。ダウンロードに行きます。
(最新のpipバージョンがあることを確認してください)
pip install beautifulsoup4
pip install requests
コードエディタに移動して、ライブラリをインポートします。
from bs4 import BeautifulSoup
import requests
まず、URLを変数に保存しましょう。
url = 'http://mignews.com/mobile'
次に、GET()リクエストをサイトに送信し、受信したデータを「page」変数に保存しましょう。
page = requests.get(url)
接続を確認しましょう:
print(page.status_code)
コードはステータスコード「200」を返しました。これは、正常に接続され、すべてが正常であることを意味します。
次に、2つのリストを作成しましょう(後で説明します)。
new_news = [] news = []
BeautifulSoup4を使用してページにフィードし、「html.parcer」がどのように役立つかを引用符で囲みます。
soup = BeautifulSoup(page.text, "html.parser")
彼がそこで何を保存したかを示すように彼に頼んだ場合:
print(soup)
ページのすべてのhtmlコードを取得します。
それでは、BeautifulSoup4の検索機能を使用してみましょう。
news = soup.findAll('a', class_='lenta')
ここに書いたものを詳しく見てみましょう。
以前に作成した「news」リスト(私が返すことを約束した)で、「a」タグと「news」クラスを使用してすべてを保存します。見つかったものをすべてコンソールに出力するように要求すると、ページにあったすべてのニュースが表示されます。ご覧のとおり

、ニューステキストとともに、タグ「a」、「span」、「classes」が表示されます。 lenta 'と' time2 '、そして' time2 time3 'は、一般的に、彼が私たちの望みに従って見つけたすべてのものです。
続けましょう:
for i in range(len(news)):
if news[i].find('span', class_='time2 time3') is not None:
new_news.append(news[i].text)
ここでは、forループで、ニュースのリスト全体を繰り返し処理します。インデックス[i]の下のニュースで、タグ「span」とクラス「time2 time3」が見つかった場合、このニュースのテキストを新しいリスト「new_news」に保存します。
BeautifulSoupがプレーンテキストへの検索に使用する「bs4.element.ResultSet」からリスト内の行を再フォーマットするために「.text」を使用していることに注意してください。
データ形式がどのように機能するかを誤解し、デバッグの使用方法がわからないためにこの問題に長い間立ち往生した場合は、注意してください。したがって、これでこのデータを新しいリストに保存し、リストのすべてのメソッドを使用できるようになりました。これは通常のテキストであり、通常は必要な処理を行うためです。
データを表示しましょう:
for i in range(len(new_news)):
print(new_news[i])
これが

私たちが得るものです: 私たちは投稿時間と興味深いニュースだけを受け取ります。
次に、カートにボットを作成してこのニュースをアップロードするか、デスクトップに最新のニュースを含むウィジェットを作成します。一般的に、あなたはニュースについて学ぶための便利な方法を思い付くことができます。
この記事が、初心者がパーサーで何ができるかを理解し、学習を少し進めるのに役立つことを願っています。
ご清聴ありがとうございました。私の経験を共有できてうれしく思います。