category_encodersライブラリのTargetEncoderの何が問題になっていますか?
この記事は、客観的な確率的コーディングが実際にどのように機能するかを説明した前の記事の続きです。この記事では、category_encodersライブラリの標準ソリューションがどのような場合に誤った結果をもたらすかを確認し、さらに、正しいマルチクラスの目的確率コーディングの理論とコード例を研究します。行く!
1. TargetEncoderが間違っているのはいつですか?
このデータを見てください。色は特徴であり、目標は...目標です。私たちの目標は、ターゲットに基づいて色をエンコードすることです。

このために、通常の目的確率エンコーディングを実行してみましょう。
import category_encoders as ce
ce.TargetEncoder(smoothing=0).fit_transform(df.Color,df.Target)
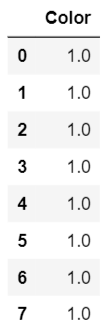
うーん...見栄えが悪いですよね?すべての色が1に変更されました。なぜですか?これは、TargetEncoderが確率ではなく、各色のすべてのターゲット値の平均をとるためです。
TargetEncoderは、0と1のバイナリターゲットがある場合は正しく機能しますが、次の2つの場合に失敗します。
ターゲットがバイナリであるが0/1ではない場合(少なくとも、たとえば1と2)。
上記の例のように、ターゲットがマルチクラスの場合。
じゃあ何をすればいいの ?!
理論
, n . , . n , . n-1 , , . - , , .
.
.
1: - .
enc=ce.OneHotEncoder().fit(df.Target.astype(str)) y_onehot=enc.transform(df.Target.astype(str)) y_onehot
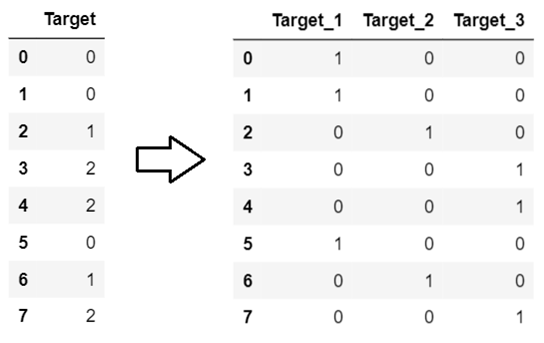
, Target_1 0 Target. 1 Target 0, 0 . Target_2 1 Target.
2: , .
class_names = y_onehot.columns
for class_ in class_names:
enc = ce.TargetEncoder(smoothing = 0)
print(enc.fit_transform(X,y_onehot[class_]))
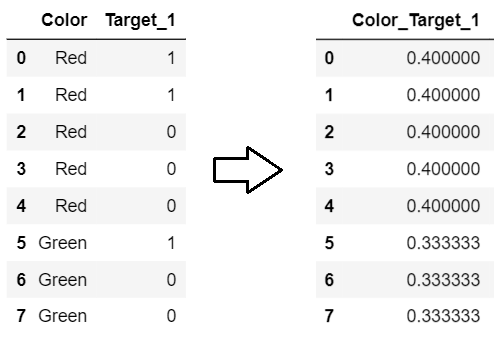
0
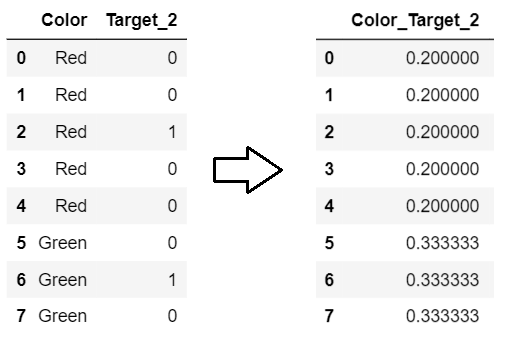
1

2
3: , , 1 2 .
!
, :

, Color_Target. , , . , , , Color_Target_3 ( - ) .
, ?!
以下は、タイプSeriesのデータテーブルとターゲットラベルオブジェクトを入力として受け取る関数です。df関数は、数値変数とカテゴリ変数の両方を持つことができます。
def target_encode_multiclass(X,y): #X,y are pandas df and series
y=y.astype(str) #convert to string to onehot encode
enc=ce.OneHotEncoder().fit(y)
y_onehot=enc.transform(y)
class_names=y_onehot.columns #names of onehot encoded columns
X_obj=X.select_dtypes('object') #separate categorical columns
X=X.select_dtypes(exclude='object')
for class_ in class_names:
enc=ce.TargetEncoder()
enc.fit(X_obj,y_onehot[class_]) #convert all categorical
temp=enc.transform(X_obj) #columns for class_
temp.columns=[str(x)+'_'+str(class_) for x in temp.columns]
X=pd.concat([X,temp],axis=1) #add to original dataset
return X
概要
この記事では、category_encoderライブラリのTargetEncoderの何が問題になっているのかを示し、元の記事でマルチクラス変数のターゲット設定について説明し、例を挙げてすべてを示し、プラグインできる実用的なモジュラーコードを提供しました。応用。