みなさん、こんにちは。今日は、データサイエンスがCOVID-19を予測するために提供できるものについての最後の記事です。
最初の記事は こちらです。2番目はここにあり ます。
今日、私たちはアレクサンダー・ゼルベンコフと、COVID-19の蔓延を予測するという彼の決定について話し合っています。
私たちの条件は次のとおりです。
与えられた:巨大なデータサイエンス能力、3人の才能のあるスペシャリスト。
見つける:1週間先のCOVID-19の広がりを予測する方法。
そして、これがアレクサンダー・ゼルベンコフの決定です
-アレクサンダー、こんにちは。まず、あなた自身とあなたの仕事について少し教えてください。
-私はLamodaでデータ分析および機械学習グループの責任者として働いています。私たちは、カタログ内の製品をランク付けするための検索エンジンとアルゴリズムに取り組んでいます。データサイエンスは、私がモスクワ州立大学の計算数学およびサイバネティックス学部で勉強していたときに興味を持っていました。
-知識とスキルが役に立ちました。あなたは高品質のモデルを作りました:過剰適合しないように十分に単純です。どのようにしてこれを達成できましたか?
-時系列の予測の問題は十分に研究されており、それにどのようなアプローチを適用できるかは理解できます。私たちのタスクでは、サンプルは機械学習の基準では非常に小さいです-トレーニングデータで数千の観測があり、毎週560の予測を行う必要があります(翌週の各日に80の地域で予測)。このような場合、実際にうまく機能するより粗いモデルが使用されます。実際、私はきちんとしたベースラインに行き着きました。
モデルとして、木の勾配ブースティングを使用しました。木製のすぐに使えるモデルは傾向を予測する方法を知らないことに気付くかもしれませんが、増分ターゲットに切り替えると、傾向を予測することが可能になります。次のX日間で、現在の日と比較してケースの数がどれだけ増加するかを予測するようにモデルを教える必要があることがわかります。ここで、1から7までのXが予測期間です。
もう1つの特徴は、モデルの予測の品質が対数スケールで評価されたことです。つまり、ペナルティは、どれだけ間違っていたかではなく、モデルの予測が不正確であることが判明した回数に対するものでした。そして、これには次のような影響がありました。すべての地域の予測の最終的な品質は、小さな地域の予測の精度に大きく影響されました。
各地域のタイムラインはわかっていました。過去の各日の症例数と、人口や都市住民の割合など、文字通りいくつかの定性的特性です。基本的にはそれだけです。検証を行い、ブースティングのトレーニングで停止する価値がある場所を判断するのが正常である場合、そのようなデータを再トレーニングすることは困難です。
-どのグラデーションブースティングライブラリを使用しましたか?
-私は昔ながらの方法です-XGBoost。私はLightGBMとCatBoostについて知っていますが、そのようなタスクでは、選択はそれほど重要ではないように思えます。
- はい。しかし、それでもターゲットです。あなたはターゲットのために何を取りましたか?これは2日間の関係の対数ですか、それとも絶対値の対数ですか。
-対象として、症例数の対数の差をとった。たとえば、今日が100件、明日が200件の場合、1日先を予測するときは、2倍の成長の対数を予測することを学ぶ必要があります。
一般に、最初の数週間はウイルスの拡散が指数関数的に増加することが知られています。つまり、対数目盛の増分をターゲットとして使用すると、実際には、定数に予測期間を掛けたものを毎日予測することが可能になります。勾配ブースティングは用途の広いモデルであり、そのようなタスクにうまく対処します。
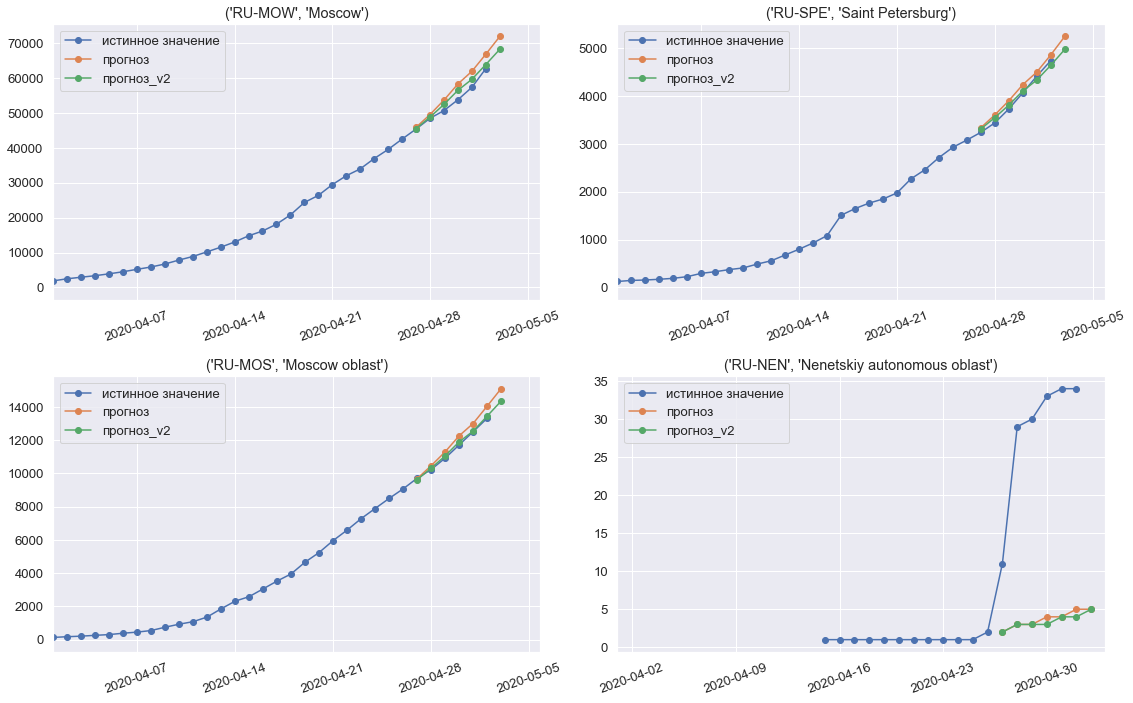
コンテストの最終週の第3週のモデル予測
-どのトレーニングサンプルを取得しましたか?
-地域を予測するために、国別の分布に関する情報を取得しました。すでにどこかで急激な成長が鈍化し、国々が高原に入り始めたので、これは助けになったようです。ロシアの地域では、いくつかの孤立した症例があった初期の期間を切り落としました。トレーニングには2月のデータを使用しました。
-どのように検証されますか?
-時系列に関しては、時間内に検証され、通常どおりに実行されます。過去2週間をテストに使用しました。先週を予測する場合、トレーニングにはそれ以前のすべてのデータを使用します。最後から2番目のデータを予測する場合、過去2週間を除いて、すべてのデータを使用します。
-他のものを使用しましたか?ある日、10日目または20日目、そこからの意味ですか?
-重要な主な要因は、過去N日間の平均、中央値、増加など、さまざまな統計でした。地域ごとに個別に計算できます。同じ要素を個別に追加して、すべての地域について一度に計算することもできます。
-検証に関する質問。安定性や精度をもっと重視していますか?基準は何でしたか?
-検証用に選択された過去2週間に取得されたモデルの平均品質を調べました。いくつかの要因を追加すると、ブースト構成を固定し、ランダムシードパラメーターのみを変更すると、予測の品質が大幅に向上する可能性があるという画像が得られました。つまり、大きな分散が得られました。再訓練せず、より安定したモデルを取得するために、最終的には、最終的なモデルでそのような疑わしい要素を使用しませんでした。
-何を覚えていますか?びっくり?うまくいった機能、またはある種のブーストトリック?
-私は2つの教訓を学びました。まず、線形とブースティングの2つのモデルをブレンドすることを決定したとき、同時に、各地域について、これら2つのモデルが使用された係数(異なることが判明)は先週単純に設定されました-つまり、7日間です。実際、私は7日間、各地域に1〜2個の係数を設定しました。しかし、発見はこれでした:私がこれらの設定をしなかった場合と比較して、予測ははるかに悪いことが判明しました。一部の地域では、モデルが大幅に再トレーニングされた結果、その地域の予測が悪いことが判明しました。大会の第3段階で、私はこれをしないことに決めました。
そして2点目:最初の病人から、10番目の病人からの特徴として、最初からの日数が役立つようです。それらを追加しようとしましたが、検証時に状況が悪化しました。私はそれをこのように説明しました:サンプルの値の分布は時間とともに変化します。ウイルスの拡散の開始から20日目に研究する場合、この機能の値の分布を予測するときは7日先に進み、おそらく、これはそのような要因をで使用することを許可しません利益。
-都市人口の割合が何らかの役割を果たしているとおっしゃいました。そして、他に何がありますか?
-はい、ロシアの国と地域の両方の都市人口のシェアは常に使用されています。この要因は一貫して予測の質にわずかな後押しを与えました。その結果、時系列自体を除いて、最終モデルには何も取り入れませんでした。その他を追加しようとしましたが、機能しませんでした。
-あなたの意見は何ですか:SARIMAは前世紀ですか?
-自己回帰モデル-移動平均-の設定はより難しく、それらに追加の要素を追加するのはより費用がかかりますが、(S)ARIMA(X)モデルを使用すると、適切な予測を行うことができると確信しています。しかし、ブーストと比較してそれほど良くはありません。
-そして、1週間よりも長い期間、あなたは予測をすることができます、あなたはどう思いますか?
- 面白そうですね。当初、主催者は長期的な予測を収集するという考えを持っていました。今月は、私が行ったアプローチをまだ試すことができるターニングポイントのようです。
-次に何が起こると思いますか?
-モデルを再構築する必要があります。ちなみに、私の解決策はここにあります:
github.com/Topspin26/sberbank-covid19-challenge
国際社会からの最新のCOVIDデータサイエンスニュースについては、https: //www.kaggle.com/tags/covid19にアクセスして ください。そしてもちろん、我々は(に招待opendatascience.slack.comで#coronavirusチャンネルにご招待いたします ods.ai)。