
レジリエントファイルシステムの主な機能
, .
— Integrity streams ( ).
«allocate on write» — .
, , , .
, .
«data sriping» — , RAID .
— «disk scrubbing», .
.
, , , .
«NTFS».
.
«ReFS» , .
«Storage Spaces» — .
«NTFS»: «BitLocker», «USN» , «ACL» , «mount points»… , «ReFS», «API».
— Integrity streams ( ).
«allocate on write» — .
, , , .
, .
«data sriping» — , RAID .
— «disk scrubbing», .
.
, , , .
«NTFS».
.
«ReFS» , .
«Storage Spaces» — .
«NTFS»: «BitLocker», «USN» , «ACL» , «mount points»… , «ReFS», «API».
「ReFS」の特徴
チェックサムはデフォルトでメタデータに使用されるようになり、個々のファイルのデータにも適用されます。そのため、読み取り/書き込みの過程で、検証は「オンザフライ」で実行されます。ファイルシステムがファイルの破損を検出すると、コンピュータを再起動せずにエントリを即座に削除します。つまり、「ReFS」は、エラーが発生したときに自動的に修正するようになりました。
「ReFS」は、古いFSと比較して、情報の保存の信頼性が高くなっています。 B +ツリーは、ファイルとメタデータを格納するために使用されます。サイズ、パーティションおよびファイルの数は、最大64ビット値に制限されるようになりました。空白は、チャンクサイズ(小、中、大)ごとに分類された3つの異なるテーブルに格納されます。ファイル名とパスは「Unicode」で記述されます。32キロバイトを超えてはなりません。つまり、ファイル名は3万文字で指定できます。
停電保護。新しいファイル名(または他のメタデータ)を書き込んでいて、電気が切れて、それらを保存する時間がなかったとしましょう。「NTFS」では、メタデータを直接変更するため、ファイルが破損します。ただし、「ReFS」はメタデータのコピーを作成するだけで、「コピーオンライト」機能の特徴である保存が行われるまでメインのメタデータを変更しません。
ストレージスペースは、メディア仮想化機能です。これにより、1台のPC上の複数の物理ディスクまたはローカルネットワーク上の複数の物理ディスクから単一のスペースを作成できます。「ミラーリング」をRAIDアレイとして構成することもできます。
NTFSとの違い
ReFSは元々、大量のパーティション、ファイル、ディレクトリ、およびそれらの名前をサポートするように設計されていました。新しいFSには、最大262エクサバイトの情報と、「NTFS」(わずか16エクサバイト)を含めることができます。
また、暗号化、圧縮、重複排除、ディスククォータ、ハードリンク、および拡張属性もありません。それらのいくつかは新しいものに置き換えられました。たとえば、「ReFS」はBitLocker暗号化を完全にサポートしています。
現在、「ReFS」ファイルシステムでは、ディスクプール(ストレージスペース)のみをフォーマットできます。この場合、新しいFSがすべての栄光を示します。ただし、Windows 10では、通常のメディアを「ReFS」にフォーマットすることはできません。開発者は、特にサーバー向けの「ReFS」の重要性を強調しています。これは、サーバーOSまたは「LTSC」バージョンで利用できます。
Windows Server 2016では、通常のボリュームを「ReFS」にフォーマットできますが、ブートセクターは「NTFS」パーティションにある必要があるため、ブートディスクのフォーマットはできません。
ファイルシステムアーキテクチャ
ReFSの構造は、他のすべてのWindowsファイルシステムとは大きく異なります。主な構成要素はB +ツリーです。それらはシングルレベル(葉のように)とマルチレベル(木のように)です。これにより、FS構造に含まれる各要素に適切なスケーリングが提供されます。このスキームは、各要素の64ビットアドレス指定と同様に、それ以上の増加で問題を起こすことを不可能にします。
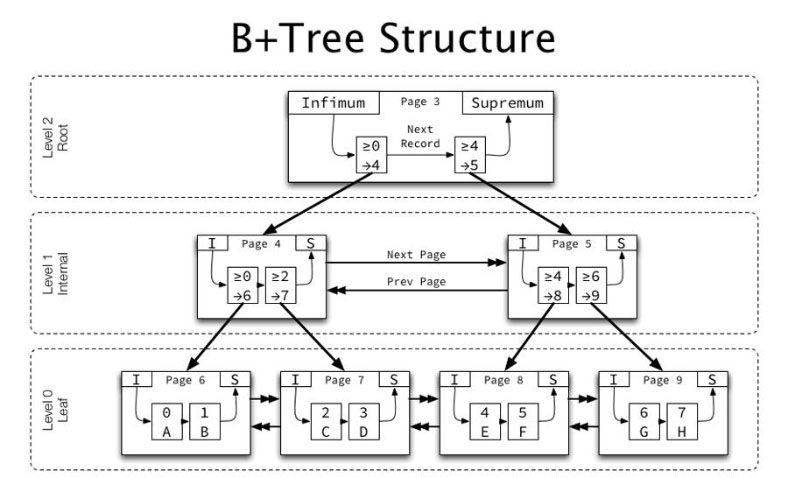
B +ツリーのルートレコードとして、残りのレコードはメタデータブロックに対して同じサイズ(16 kb)を持ちます。サイズ60バイト-中間(アドレス)ノードに割り当てられます。したがって、大規模なストレージ構造を適切に記述するために必要な層の数は少なくなります。これにより、FSのパフォーマンスを他の製品と比較して向上させることができました。
ReFSファイルシステムの構造
「ReFS」は、セクションの先頭にある特定の署名で識別できます

。0x4000バイト-すべてのReFSページの長さ。

最初のページ番号は0x1e、つまり、ブートパーティションの直後の0x78000バイトです。これは、固定オフセットの後に最初のメタデータを検索するようにアドバイスする標準のMicrosoftマッピングです。
削除されたデータ検索アルゴリズム
データ復旧ユーティリティは、署名ベースの分析アルゴリズムを使用して、「ReFS」フォーマットのディスク領域のフルスキャンを実行します。ディスクをブロックごとにチェックすることにより、準備ができたデータシーケンスを見つけ、それらを識別し、結果を出力します。 「ReFS」と「NTFS」のディスクを操作するためのAPIは同じであるため、データ復旧プロセスは非常に似ています。
最初に、「ボリュームヘッダー」が決定されます。これには、クラスターごとのセクター数とセクターの量が含まれます。メインバージョンはゼロセクターにあり、コピーは最後のセクターにあります。次に、「スーパーブロック」を読み取り、30番目のブロックに配置し、最後の2番目と3番目のブロックにも2つのコピーがあります。そこから、「チェックポイント」へのリンクとそのコピーが抽出され、最新の現在のバージョンは「仮想割り当てクロック」によって決定されます。
チェックポイントにはメインテーブルに関する情報が含まれ、次にヘッダー「ページヘッダー」とテーブルの完全なリストへのポインター(ポインター)を持つブロックが読み取られます。次に、「コンテナテーブル」を検索して仮想アドレスから物理アドレスを取得し、「オブジェクトIDテーブル」で検索を実行します。すべてのテーブルが見つかります。
ユーティリティはレベル0(つまり、bツリーシート)に下がり、ファイルデータを読み取ります。検索はページごとに実行されるため、失敗した場合、これらの要素は分析から除外され、スキャンプロセス自体がさらに進行します。したがって、データ復旧ユーティリティは、ディスクから「取得」できるすべての情報を見つけます。
すべての追加のビデオチュートリアルを含む完全な記事のソースを参照してください 。