初期のルーターは、バスにネットワークインターフェイスカード(NIC)が接続された通常のコンピューターでした。

図1-バスに接続されたネットワークインターフェイスカード。
ある時点まで、そのようなシステムは機能していました。このアーキテクチャでは、パケットはNICに入り、CPUによってNICからメモリに転送されました。 CPUは転送を決定し、パケットを外部NICに出力しました。 CPUとメモリは、デバイスのサポートが制限された一元化されたリソースです。バスも追加の制限でした。バスの帯域幅は、すべてのNICの帯域幅を同時にサポートする必要がありました。
ネットワークをスケールアップする必要がある場合、問題はすぐに発生し始めます。より高速なプロセッサを購入できますが、バスの電力をどのように増やしますか?バス速度を2倍にする場合は、各NICとCPUのバスインターフェイス速度を2倍にする必要があります。これにより、単一のNICの容量が増加しなくても、すべてのボードのコストが増加します。
レッスン1:ルーターのコストはその機能に比例して増加する必要があります
学んだ教訓にもかかわらず、アップスケーリングの便利な解決策は、別のバスとプロセッサを追加することでした。

図2-システムのスケーリングの問題の解決策は、新しいバスとプロセッサを追加することでした。
算術論理演算装置(ALU)は、その優れた価格性能比のために選択されたデジタル信号処理(DSP)チップでした。追加のバスは帯域幅を増やしましたが、アーキテクチャはとにかく規模が大きくなりませんでした。言い換えれば、生産性を向上させるためにALUとバスを追加することはできなかったでしょう。
ALUは依然として重要な制限であったため、次のステップは、フィールドプログラマブルゲートアレイ(FPGA)をアーキテクチャに追加して、最長プレフィックス一致(LPM)ルックアップの負荷を軽減することでした。

図3-次のステップは、フィールドプログラマブルゲートアレイを追加することでした。
これは役に立ちましたが、問題を完全に解決することはできませんでした。ALUはまだ圧倒されていました。LPMが負荷の大部分を占めていましたが、問題の一部を取り除いたとしても、集中型アーキテクチャは依然として適切に拡張できませんでした。
レッスン2:LPMはシリコンに実装でき、パフォーマンスの障害にはなりません
このレッスンにもかかわらず、次のステップは別の方向に進みました。ALUとFPGAを標準プロセッサに置き換えることです。設計者は、CPUとバスを追加してスケールアップしようとしました。わずかな電力の増加でも多大な労力を要し、システムは依然として集中型バスの帯域幅制限に悩まされていました。
インターネットの進化のこの段階で、より深刻な力が働き始めました。ウェブが一般の人々に人気になるにつれて、インターネットの可能性がより明らかになり始めました。 Telcosは地域のNSFnetネットワークを買収し、商業施設の建設を開始しました。特定用途向け集積回路(ASIC)は実証済みの技術になり、より多くの機能をシリコンに直接実装できるようになりました。ルーターの需要は急増しており、スケーラビリティを大幅に改善する必要性が、ついにエンジニアリングの保守性を打ち破りました。この需要を満たすために、多くの新興企業がさまざまな可能な解決策を生み出してきました。
スケジュールされたクロスバーは、選択肢の1つになりました。

図4-スケジュールされたクロスバー。
このアーキテクチャでは、各NICに入力と出力がありました。 NICプロセッサは転送を決定し、出力NICを選択して、スイッチ(クロスバー)にスケジューリング要求を送信しました。スケジューラーはNICからすべての要求を受け取り、最適なソリューションを考え出し、ソリューションをスイッチにプログラムし、入力を送信に向けました。
このスキームの問題は、各出力が一度に1つの入力を「リッスン」でき、インターネットトラフィックがパルス化することでした。 2つのパケットが同じ出口に到達する必要がある場合、そのうちの1つは待機する必要がありました。 1つのパケットを待機すると、他のパケットが同じ入力で待機し、その後、システムでヘッドオブラインブロッキング(HOLB)が発生し始め、ルーターのパフォーマンスが大幅に低下しました。
レッスン3:ルーターの内部構造は、負荷がかかった状態でも信号をブロックしてはなりません
特殊なチップへの移行により、設計者は内部セルベースの構造に移行するようになりました。これは、小さい固定サイズのセルの切り替えが、場合によっては大きい可変長のパケットを処理するよりもはるかに簡単だからです。ただし、スイッチングセルを使用すると、スケジューラをより高い頻度で実行する必要があり、スケジューリングがはるかに困難になります。
もう1つの革新的なアプローチは、NICをトーラスに組み込むことでした。

図5-トーラス型のNIC。
このようなスキームでは、各NICは4つのネイバーに接続されており、入力NICは、出力ラインカードに到達するために構造を通るパスを計算する必要がありました。このシステムには問題がありました-帯域幅は同じではありませんでした。南北方向の伝送幅は東西方向よりも広かった。インバウンドトラフィックパターンが東西に移動する場合、輻輳が発生します。
レッスン4:トラフィックの分散を予測できないため、ルーターの内部構造には帯域幅が均等に分散されている必要があります。
まったく異なるアプローチは、完全なNIC-NIC通信ネットワークを作成し、すべてのNICにセルを分散することでした。
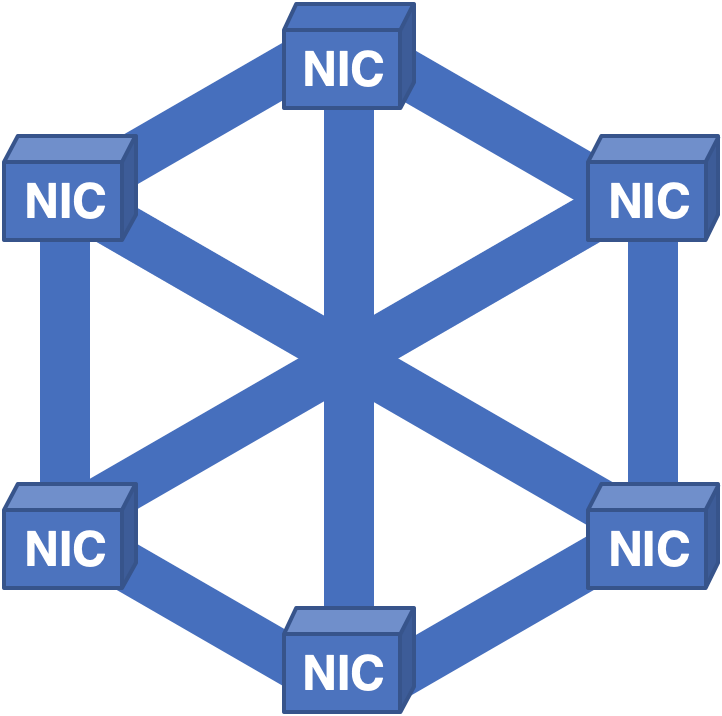
図6-すべてのNICにセルが分散された完全に接続された構造。
前のレッスンを学んだにもかかわらず、新しい問題が特定されました。このアーキテクチャでは、修理のためにボードを取り外す必要が生じるまで、すべてが十分に機能していました。各NICにはシステム内のすべてのパケットのセルが含まれているため、カードを取り外すと、どのパケットも再作成できず、短いが苦痛を伴うダウンタイムが発生しました。
レッスン5:ルーターに単一障害点があってはならない
このアーキテクチャを採用して、逆さまにしました。
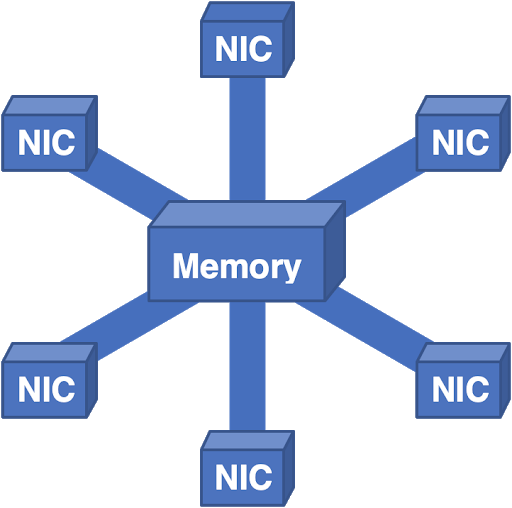
図7-ここでは、すべてのパケットが中央メモリに送られ、次に出力NICに送られます。
このシステムはかなりうまく機能しましたが、メモリのスケーリングが問題になりました。いくつかのコントローラーとメモリバンクを追加するだけでかまいませんが、ある時点で、全体的な帯域幅が物理設計には複雑になりすぎます。実際の物理的な制約に直面して、私たちは他の方向に考えることを余儀なくされました。
電話網は私たちのインスピレーションの源になっています。ずっと前に、Charles Closeは、より小さなスイッチのネットワークを構築することによってスケーラブルなスイッチを作成できることに気づきました。結局のところ、必要なすべての素晴らしいプロパティがClosネットワークに存在します。

図8-Closネットワーク。
ネットワークプロパティを閉じる:
- 力は規模とともに成長します。
- 単一障害点はありません。
- フォールトトレランスのために十分な冗長性を維持します。
- 構造全体に荷重を分散させることにより、過負荷に対処します。
私たちは常に入力と出力を一緒に実装するので、通常、この画像を点線に沿って折ります。これにより、Closネットワークが折りたたまれます。これは、マルチケースルーターで現在使用されているものです。NICとスイッチのレイヤーがある場合もあれば、スイッチの追加レイヤーがある場合もあります。

図9-折りたたまれたClosネットワーク。
残念ながら、このアーキテクチャにも独自の問題があります。スイッチ間で使用されるセルのフォーマットは独自のものであり、チップメーカーが所有しているため、チップセットに依存することになります。チップベンダーへの依存は、単一のルーターベンダーへの依存よりもはるかに優れているわけではなく、問題は同じです。つまり、デバイスの価格設定と可用性を単一のソースに結び付けることです。新しいセルスイッチは、相互運用性を維持するためにレガシー接続とセル形式、および新しい機器のすべてのリンクレートとセル形式を同時にサポートする必要があるため、ハードウェアのアップグレードは困難です。
各セルは、情報の送信先となる出力NICを示すようにアドレス指定する必要があります。このようなアドレス指定は有限であり、スケーラビリティの制限が生じます。マルチケースルーターの制御と管理は依然として完全に独自のものであり、ソフトウェアスタックに別の単一ベンダーの問題を引き起こしています。
幸い、アーキテクチャの哲学を変えることで、これらの問題を解決できます。過去50年間、ルーターの拡張に努めてきました。大きな雲を構築した経験から、スケールアウトの哲学がより成功することが多いことを学びました。
スケールアウトアーキテクチャは、巨大で非常に高速な単一サーバーを作成するのではなく、分割統治戦略を使用します。小さなサーバーのラックは、より信頼性が高く、柔軟性があり、費用効果が高い一方で、同じ仕事をすることができます。
このアプローチはルーターにも適用できます。メッシュ関連の問題を回避しながら、複数の小さなルーターをClosトポロジに並べて、同様のアーキテクチャ上の利点を実現することは可能ですか?結局のところ、これは特に難しいことではありません。

図10-セルスイッチをパケットスイッチに置き換え、スケーリングを容易にするためにClosトポロジを維持します。
セルスイッチをパケットスイッチに置き換え、Closトポロジを維持することで、スケーラビリティが容易になります。
スケーリングは、既存のレイヤーと並行して新しい入力ルーターとパケットスイッチを追加するか、スイッチレイヤーを追加するかの2つの次元で可能です。現在、個々のルーターはかなり標準化されているため、単一のベンダーに依存することはありません。すべてのリンクは標準のイーサネットを使用しているため、互換性の問題はありません。
アップグレードは簡単です。スイッチにさらに多くのチャネルが必要な場合は、より大きなスイッチに置き換えるだけです。別のチャネルをアップグレードする必要があり、チャネルの両端にこの機能がある場合は、光学系をアップグレードするだけです。各ルーターはレートマッパーとして機能するため、ファブリック内の異なるリンクの伝送速度の違いは問題になりません。
このアーキテクチャは、データセンターの世界ですでに人気があり、スイッチレイヤーの数に応じて、リーフスパインまたはスーパースパインアーキテクチャと呼ばれます。信頼性が高く、安定性があり、柔軟性があることが証明されています。
伝送面の観点から、これがアーキテクチャの実行可能な代替手段であることは明らかです。コントロールプレーンとコントロールプレーンには問題が残っています。コントロールプレーンをスケールアウトするには、制御プロトコルのスケールを1桁改善する必要があります。トポロジ全体を単一のノードとして記述するアーキテクチャのプロキシ表現を作成することにより、抽象化メカニズムを改善することにより、これを実装しようとしています。
同様に、Clos構造全体を単一のルーターとして制御できるようにするコントロールプレーンの抽象化の開発に取り組んでいます。この作業はオープンスタンダードとして行われるため、関連するテクノロジーはいずれもプロプライエタリではありません。
50年の間に、ルーターアーキテクチャは飛躍的に進化し、さまざまなテクノロジー間のトレードオフを見つける過程で多くの間違いが発生しました。明らかに、私たちの進化はまだ完了していません。各反復で、前世代の問題に取り組み、新しい課題を発見しました。
過去と現在の経験を注意深く研究することで、ハードウェアを完全に交換することなく、より柔軟で信頼性の高いアーキテクチャに向けて前進し、将来の改善を生み出すことができれば幸いです。