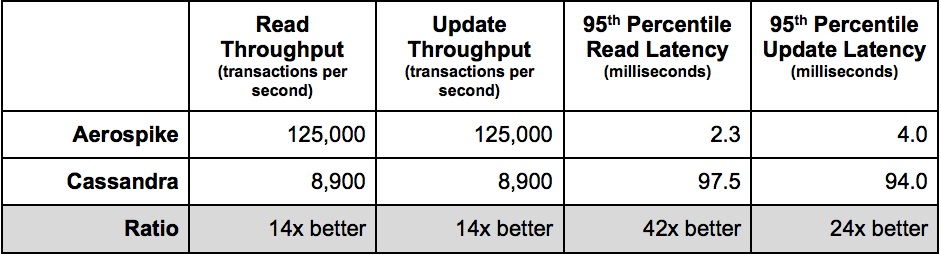
驚くべき偶然の一致で、Scylla(以下SC)もCSを簡単に打ち負かし、そのホームページで誇らしげに 発表しています。

したがって、クジラとゾウのどちらが誰を囲うのかという疑問が自然に生じます。
私の テストでは、HBaseの最適化バージョン(以下、HBと呼びます)はCSと同等に機能するため、ここでは勝利の候補にはなりませんが、すべての処理がHBに基づいており、リーダーと比較してその機能を理解します。
HBとCSが無料であることは明らかですが、一方で、同じパフォーマンスを達成するためにX倍のハードウェアが必要な場合は、データセンターのフロアを高価なものに割り当てるよりもソフトウェアに支払う方が有利です。加熱パッド。特にパフォーマンスについて話している場合、HDDは原則として、ランダムアクセス読み取りの少なくともある程度の許容速度を提供できないため(「HDDと高速ランダムアクセス読み取りに互換性がない理由」を参照 )、つまり実際のビッグデータに必要な量のSSDを購入することは、非常に高価な喜びです。
そこで、以下を行いました。 AWSクラウドのi3en.6xlarge構成で4台のサーバーをレンタルしました。各サーバーは、
CPU-24 vcpu
MEM- 19GBです。
SSD-2 x 7500 GB
誰かがそれを繰り返したい場合、ディスクの総量(7500 GB)の構成を採用することは、再現性にとって非常に重要であることにすぐに気付きます。そうしないと、ディスクを予測できないネイバーと共有する必要があり、非常に貴重な負荷であると思われるため、テストが確実に台無しになります。
次に、メーカーから自社のWebサイトで提供されたコンストラクターを使用してSCを展開しました 。次に、クラスターノードごとにYCSBユーティリティ(比較データベーステストのほぼ標準)をアップロードしました。
重要なニュアンスは1つだけです。ほとんどの場合、次のパターンを使用します。変更する前にレコードを読み取り、新しい値を書き込みます。
だから私は次のように更新を変更しました :
@Override
public Status update(String table, String key,
Map<String, ByteIterator> values) {
read(table, key, null, null); // << added read before write
return write(table, key, updatePolicy, values);
}
次に、4つのホストすべて(データベースサーバーが配置されているのと同じホスト)から同時にロードを開始しました。一部のデータベースのクライアントは他のデータベースよりも多くのCPUを消費することがあるため、これは意図的に行われます。クラスターのサイズが限られていることを考慮して、サーバーとクライアントの両方の部分の実装の全体的な効率を理解したいと思います。
テスト結果を以下に示しますが、次に進む前に、いくつかの重要なニュアンスを検討する価値があります。
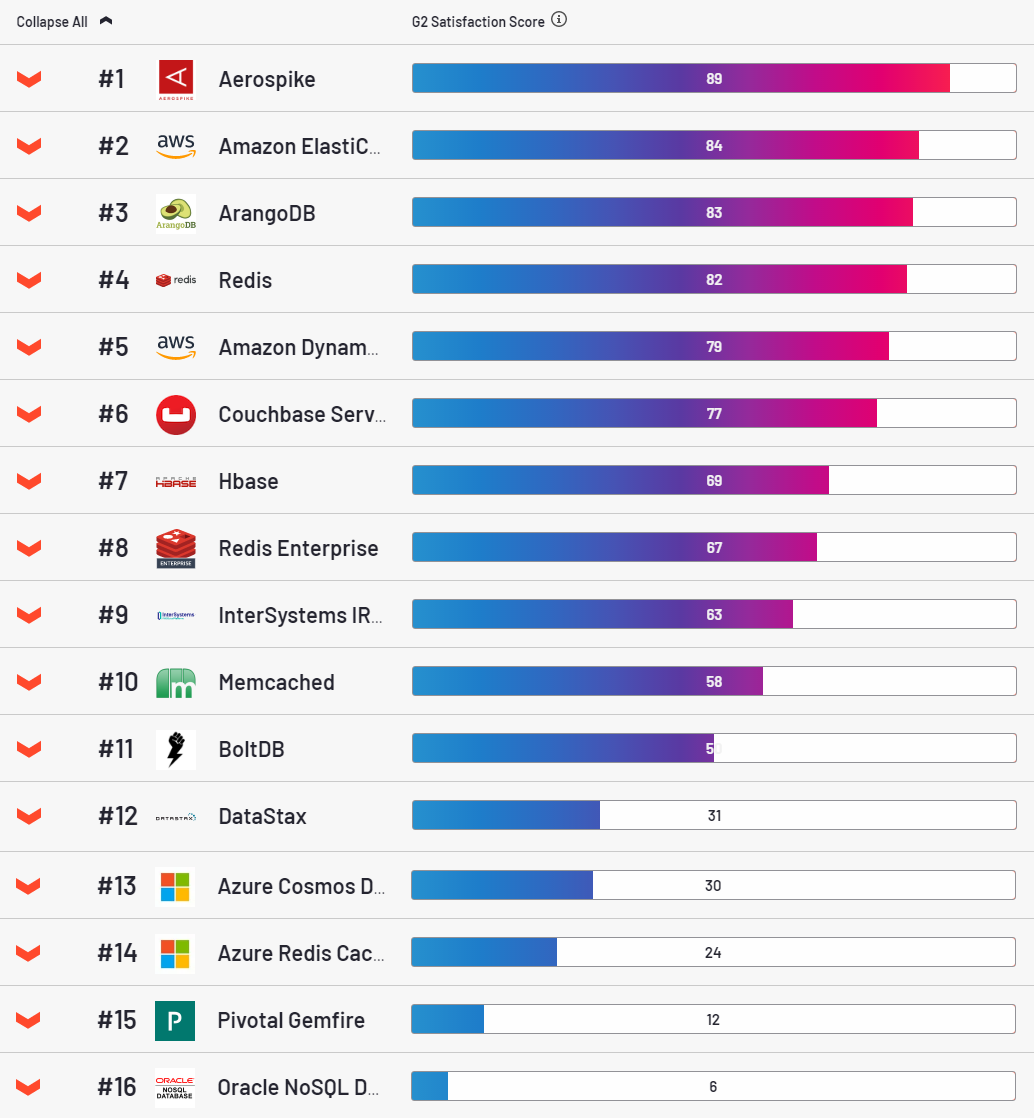
ASに関しては、これは非常に魅力的なデータベースであり、 g2リソースによると顧客満足度カテゴリのリーダー です。
率直に言って、私もどういうわけかそれが好きでした。このスクリプトで簡単に言えば 非常に簡単にクラウドに展開できます。安定していて、設定するのは楽しいことです。ただし、非常に大きな欠点が1つあります。キーごとに、64バイトのRAMが割り当てられます。少しは思えますが、工業用のボリュームでは問題になります。テーブルの一般的なエントリは500バイトです。私がほぼ*すべてのテストで使用したのはこの値の量です(*なぜほとんど以下で説明します)。
各レコードのコピーを3つ保存するため、1 PBのクリーンデータ(3 PBのダーティデータ)を保存するには、400TBのRAMを割り当てるだけで済みます。先に進む...何も?!ちょっと待ってください、それについて何かできることはありますか? -ベンダーに聞いた。
ハ、もちろん、あなたはたくさんのことをすることができます、あなたの指を曲げてください:
では、HBについて説明しましょう。これで、テスト結果を検討できます。 Hadoopをインストールするには、AmazonがEMRプラットフォームを提供します。これにより、必要なクラスターを簡単に展開できます。プロセスと開くファイルの数の制限を上げるだけで済みました。そうしないと、負荷がかかるとクラッシュし、hbase-serverが最適化されたアセンブリに置き換えられました(詳細はこちらをご覧 ください)。 2番目のポイントは、単一のリクエストを処理するときにHBが恥知らずに遅くなることです。これは事実です。したがって、バッチでのみ作業します。このテストでは、バッチ= 100です。テーブルには100の領域があります。
さて、そして最後の瞬間、すべてのデータベースは「強力な一貫性」モードでテストされました。 HBの場合、箱から出してすぐに使用できます。 ASは、エンタープライズバージョンでのみ使用できます(つまり、このテストで有効になりました)。 SCは書き込み整合性=すべてのモードで実行されました。複製係数はどこにでもあります3。
それでは、行きましょう。 ASに挿入:
10秒:360554操作。 36055.4現在の操作/秒;
20秒:698872操作; 33831.8現在の操作/秒;
...
230秒:7412626操作; 22938.8現在の操作/秒;
240秒:7542091操作; 12946.5現在の操作/秒;
250秒:7589682操作; 4759.1現在の操作/秒;
260秒:7599525操作; 984.3現在の操作/秒;
270秒:7602150操作; 262.5現在の操作/秒;
280秒:7602752操作; 60.2現在の操作/秒;
290秒:7602918操作; 16.6現在の操作/秒;
300秒:7603269操作; 35.1現在の操作/秒;
310秒:7603674操作; 40.5現在の操作/秒;
キーuser4809083164780879263の書き込み中にエラーが発生しました:com.aerospike.client.AerospikeException $タイムアウト:クライアントタイムアウト:タイムアウト= 10000反復= 1 failedNodes = 0 failedConns = 0 lastNode = 5600000A 127.0.0.1:3000
挿入中にエラーが発生し、再試行しません。試行回数:1挿入再試行制限:0
おっと、あなたは間違いなく
さて、続けましょう。 2億レコードのロードを開始し(INSERT)、次にUPDATE、次にGETを実行します。何が起こったのか(ops-1秒あたりの操作数):

重要!これは1つのノードの速度です!全部で4つあります。合計速度を取得するには、4を掛ける必要があります。
最初の列は10フィールドですが、これは完全に公正なテストではありません。それら。これは、インデックスがメモリ内にある場合であり、実際のビッグデータの状況では達成できません。
2番目の列は、10レコードを1にパックしています。正確に10倍の実際のメモリ節約がすでにあります。テストからはっきりとわかるように、このトリックは無駄ではなく、パフォーマンスが大幅に低下します。理由は明らかです。1つのレコードを処理するたびに、9つの隣接するレコードを処理する必要があります。オーバーヘッドが短くなります。
そして最後にオールフラッシュ、これはほぼ同じ写真です。フラッシュインサートはより悪いですが、キーアップデート操作はより速いので、さらにオールフラッシュと比較するだけです。
実際、すぐに猫を引っ張らないようにしましょう。

すべては一般的に明確ですが、ここに何を追加する必要があります。
- AS , .
- SC - , :

おそらくどこかに設定のわき柱があるか、カーネルのバグが表面化したのか、私にはわかりません。しかし、私はベンダーからのスクリプトに至るまですべてをセットアップしたので、原付は私のものではなく、すべての質問は彼のためのものです。
また、これは非常に控えめな量のデータであり、大量の場合は状況が変わる可能性があることを理解する必要があります。実験中、私は数百ドルを燃やしたので、熱意は長期的なリーダーテストと1台のサーバーに限定されたモードでのみ十分でした。
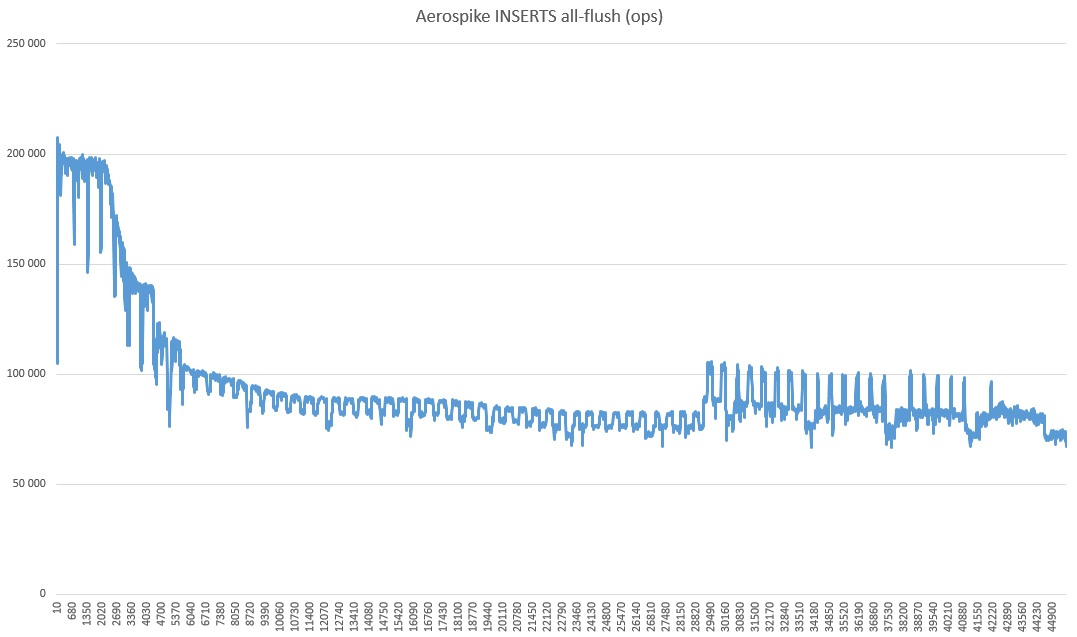
なぜそんなに沈静化したのか、そして最後の3分の1でどのようなリバイバルが自然の謎なのか。また、速度がテストよりも大幅に速く、少し速いことに気付くでしょう。これは、強力な整合性モードがオフになっているためだと思います(サーバーが1つしかないため)。
そして最後に、GET + WRITE(30億を超えるレコードに加えて、テストが殺到しました):
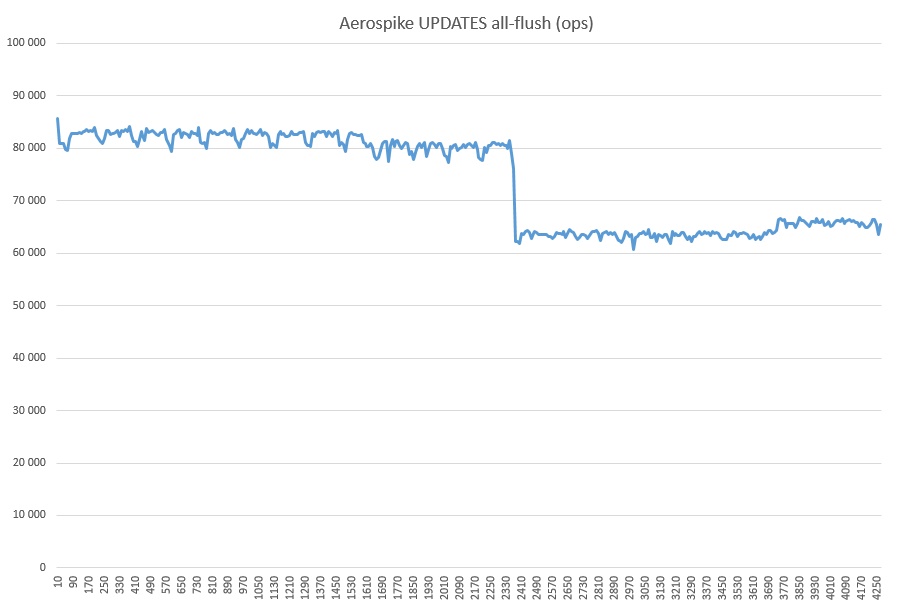
これはどのようなドローダウンなのか、私は心の中で推測していません。無関係なプロセスは開始されませんでした。オールフラッシュモードでのASテスト全体の使用率が100%だったため、おそらくSSDキャッシュと関係があります。

それで全部です。結論は一般的に明確であり、より多くのテストが必要です。同じ条件下で最も人気のあるすべてのデータベースにとって望ましいことです。インターネットでは、このジャンルはどういうわけかあまりありません。そして、それは良いことです。そうすれば、ベースベンダーは最適化するように動機付けられ、私たちは慎重に最適なベンダーを選択します。