
多くの場合、開発で既製のツールを使用することは、次善の解決策になります。だからそれは私たちと一緒に起こりました。データパイプラインを管理するために、独自のシステムであるWombatを開発することにしました。何が起こったのか、そして既製のソリューションを使用することを拒否したことが私たちに何をもたらしたのかをお伝えします。
独自のシステムを開発している理由
独自のデータパイプライン管理システムを作成することは明らかな選択ではありません。今日、この問題を解決できる既製のソリューションはたくさんあります。Airflow、MLflow、Kubeflow、Luigi、その他多数です。私たちはこれらのシステムの多くを実験し、どれも私たちに適していないという結論に達しました。
たとえば、最も一般的なソリューションであるAirflowについて考えてみます。これは、パイプラインを記述するためのAPI、wokflowコレクター、コントロールパネルとインターフェイス、タスクスケジューラとタスクオーケストレーター、そして最後にAirflowコンポーネントの監視という6つの主要なブロックを組み合わせたものです。しかし、パイプラインを管理するには、この機能では不十分でした。
私たちにとって、パイプライン管理システムとビルドシステムおよびCIの統合、Kubernetesとの統合、アーティファクトの管理機能、データ検証などの機能は非常に重要でした。

完成したシステムの機能を必要なレベルまで構築するのにかかる費用を把握し、独自のシステムを開発する方がはるかに簡単で迅速であることに気づきました。私たちはそれをウォンバットと呼びました-動物がとてもかわいいので、そして第二に、それはオーストラリアの自然の救世主と考えられているので。そして私たちにとって、開発とデータを扱うすべての段階を組み合わせることができるシステムもまた、真の救済となるでしょう。
どのような問題を解決しましたか
これまで、開発チームでは、DevOpsエンジニアが本番環境のサービスをサポートしてきました。また、パイプラインの操作に慣れています。パイプラインは、コードではなく、yamlなどの形式の構成で記述されます。この不一致のため、サポートを共有するか、非古典的な継続的インテグレーションシステムで作業するようにエンジニアをトレーニングする必要があります。
有向非巡回グラフの形式のパイプラインは、標準のCIおよびDevOpsツールで使用される形式で完全に記述されているため、これはすべて冗長で不要な作業になります。

私たちが直面した2番目の問題は、アーティファクトの保存とバージョン管理でした。データパイプライン管理システムでアーティファクトを操作すると、2つの非常に便利な機会を得ることができます。パイプラインでの操作の結果を再利用し、データを使用して実験を再現し、新しい実験を整理する時間を節約します。
アーティファクトの保存の編成が自動化されていない場合、遅かれ早かれ新しいアーティファクトが古いアーティファクトを上書きし始めるか、本番マシンの空き領域が不足し始めます。さらに、本番環境では、ストレージの信頼性とフォールトトレランスを確保するために特定の要件を適用する必要があります。これは、もう1つのコストのかかるプロセスです。
そのため、パイプラインの管理に関連するすべてのタスクをバックグラウンドで実行し、データスペシャリストが他のプロジェクトの成果物を処理できるようにすると同時に、データストレージのコストを考慮しないソリューションを取得したいと考えました。
3番目の問題は、データストリームの入力です。はい、Pythonを使用すると、プロトタイプを開発し、さまざまな仮説を高速でテストできます。ただし、データを操作するとき、予期しない驚きを望まない場合は、操作しているタイプに注意を払う必要があります。本番環境でのこのような問題の数を減らすには、データスキーマの記述からデータフレームスキーマの記述までのサポートが必要です。データの入力は、開発用と本番用で別々に行う必要があります。
最後に何が起こったのか
従来、Wombatアーキテクチャは次のように表すことができます。

この図は、システムの役割を示しています。これは、パイプラインの記述とCIシステムの間の中間層であり、本番環境でパイプラインを操作するのに役立ちます。
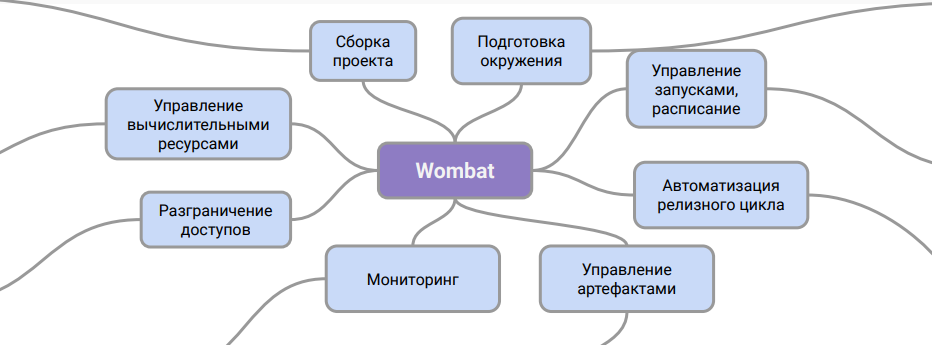
この作業スキームのおかげで、エンジニア向けの追加のトレーニングやこのプロセスにデータスペシャリストを関与させることなく、DevOps部門のパイプラインのサポートを整理できます。さらに、データアーティファクトとそのバージョン管理の保存に関する問題が解決されます。
現在、データサイエンティストにネイティブな形式で、プロトタイピングと実験の初期段階にツールを導入できる機能を開発しています。これにより、パイロットと本番環境へのプロジェクトの立ち上げが大幅にスピードアップします。
近い将来、このツールをオープンソースでリリースする準備をしています。私たちのプロジェクトについてのご意見や、最新のデータパイプラインシステムでの作業経験を共有していただければ幸いです。
また、この記事は本質的に技術的というよりも情報提供であることに気づき、近い将来、より詳細で筋金入りのテキストを準備する予定です。あなたが見たいものをコメントに書いて、技術的な用語で見つけてください。私たちは考慮に入れ、説明し、書きます。ご清聴ありがとうございました!
PS私たちはまだ才能のあるプログラマーに興味を持っています。 さあ、おもしろい!