Webアプリケーションのパフォーマンスを向上させるには、WebAssemblyをAssemblyScriptと組み合わせて使用して、Webアプリケーションのパフォーマンスが重要なJavaScriptコンポーネントを書き直します。「そしてそれは本当に役に立ちますか?」あなたは尋ねます。
残念ながら、この質問に対する明確な答えはありません。それはすべてあなたがそれらをどのように使うかに依存します。多くの選択肢があります。答えが否定的な場合もあれば、肯定的な場合もあります。ある状況では、AssemblyScriptよりもJavaScriptを選択する方が適切であり、別の状況では、その逆です。これは、さまざまな条件の影響を受けます。
この記事では、これらの条件を分析し、いくつかのソリューションを提案し、いくつかのテストコード例でテストします。
私は誰で、なぜ私はこのトピックをやっているのですか?
(このセクションはスキップできます。これ以上の資料を理解するために必須ではありません)。
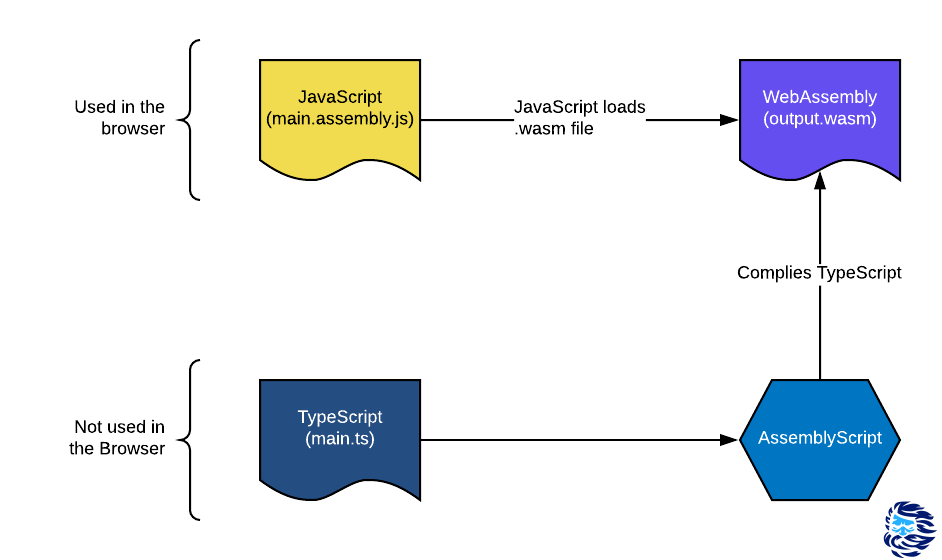
私はAssemblyScript言語が本当に好きです 。私はある時点で開発者を財政的に支援し始めました。彼らには小さなチームがあり、誰もがこのプロジェクトに真剣に情熱を注いでいます。 AssemblyScriptは、WebAssembly(Wasm)にコンパイルできる非常に若いTypeScriptのような言語です。これはまさにその利点の1つです。以前は、Wasmを使用するために、Web開発者はC、C ++、C#、Go、Rustなどの外国語を学習する必要がありました。これは、静的型付けを使用するこのような高級言語は、からWebAssemblyにコンパイルできるためです。非常に始まりです。
AssemblyScript(ASC)はTypeScript(TS)に似ていますが、その言語に関連付けられておらず、JSにコンパイルされません。 TSからASCへの「移植」プロセスを容易にするために、構文とセマンティクスの類似性が必要です。この移植は、基本的に型注釈の追加に要約されます。
私は常にJSコードを取得し、それをASCに移植し、Wasmにコンパイルし、パフォーマンスを比較することに興味を持っていました。同僚のIngvarが画像をぼかすためのJavaScriptスニペットを送ってくれたとき、私 はそれを使うことにしました。このトピックをさらに深く調査する価値があるかどうかを確認するために、少し実験を行いました。それは価値があることが判明しました。その結果、この記事が掲載されました。
AssemblyScriptについて詳しく知るには、公式 Webサイトを チェックするか、 Discord チャンネルに参加するか 、YouTubeチャンネルの紹介ビデオ をご覧ください。そして次に進みます。
WebAssemblyの利点
上で書いたように、長い間、Wasmの主なタスクは、高レベルの汎用言語で記述されたコードをコンパイルする機能でした。たとえば、 Squoosh(オンライン画像処理ツール)では、C / C ++およびRustエコシステムのライブラリを使用しています。これらのライブラリは元々Webアプリケーションで使用するために設計されたものではありませんが、WebAssemblyによって可能になります。
さらに、一般的な信念によれば、Wasmバイナリを使用するとWebアプリケーションの作業を高速化できるため、Wasmでソースコードをコンパイルすることも必要です。少なくとも、理想的な(実験室の)条件下では、WebAssemblyとJavaScriptのバイナリ がピークパフォーマンスのほぼ等しい値を提供します。これは、戦闘Webプロジェクトではほとんど不可能です。
私の意見では、WebAssemblyを平均的な作業パフォーマンス値の1つの最適化ツールと考える方が理にかなっています。最近ではありますが、WasmにはSIMD命令と共有メモリストリームを使用する機能があります。これにより、競争力が高まるはずです。しかし、いずれにせよ、私が上で書いたように、それはすべて特定の状況と初期条件に依存します。
以下では、そのようないくつかの条件について検討します。
ウォーミングアップの欠如
V8 JSエンジンはソースコードを処理し、それを抽象構文木(AST)として表示します。構築されたASTに基づいて、最適化されたIgnitionインタープリターがバイトコードを生成します。結果のバイトコードはSparkplugコンパイラによって取得され、出力で、まだ最適化されていないマシンコードを大きなフットプリントで生成します。コードの実行中に、V8は使用されるオブジェクトのフォーム(タイプ)に関する情報を収集し、最適化コンパイラTurboFanを実行します。オブジェクトに関して収集された情報に基づいて、ターゲットアーキテクチャ用に最適化された低レベルのマシン命令を生成します。 この記事の翻訳を
調べることで、JSエンジンがどのように機能するかを理解でき ます。

JSエンジンパイプライン。一般的なスキーマ
一方、WebAssemblyは静的型付けを使用するため、そこからマシンコードをすぐに生成できます。V8エンジンには、Liftoffと呼ばれるストリーミングWasmコンパイラがあります。Ignitionと同様に、最適化されていないコードをすばやく準備して実行するのに役立ちます。その後、同じターボファンが起動してマシンコードを最適化します。Liftoffをコンパイルした後よりも高速に実行されますが、生成に時間がかかります。
JavaScriptパイプラインとWebAssemblyパイプラインの基本的な違い:Wasmには静的型付けがあり、すべてが事前にわかっているため、V8エンジンはオブジェクトと型に関する情報を収集する必要はありません。これにより時間を節約できます。
最適化解除の欠如
TurboFanがJavaScript用に生成するマシンコードは、型の仮定が維持されている場合にのみ使用できます。たとえば、TurboFanが数値パラメータを持つ関数fのマシンコードを生成したとします。次に、数値ではなくオブジェクトを使用してこの関数の呼び出しが発生すると、エンジンは再びIgnitionまたはSparkplugを使用します。これは最適化解除と呼ばれます。
WebAssemblyの場合、プログラムの実行中にタイプを変更することはできません。したがって、このような最適化を解除する必要はありません。そして、Wasmがサポートするタイプ自体は、有機的にマシンコードに変換されます。
大規模プロジェクトのバイナリを最小化する
Wasmは元々 、コンパクトなバイナリファイル形式を念頭に置いて設計されました。したがって、このようなバイナリはすぐに読み込まれます。しかし、多くの場合、それでも私たちが望む以上の結果が得られます(少なくともネットワークで受け入れられるボリュームに関しては)。ただし、gzipまたはbrotliを使用すると、これらのファイルは適切に圧縮されます。
何年にもわたって、JavaScriptは、配列、オブジェクト、辞書、イテレーター、文字列処理、プロトタイプの継承など、箱から出してすぐに多くのことを学びました。これはすべてそのエンジンに組み込まれています。たとえば、C ++言語は、はるかに広い範囲を誇ることができます。また、WebAssemblyにコンパイルするときにこれらの言語抽象化のいずれかを使用するたびに、内部の対応するコードをバイナリに含める必要があります。これが、WebAssemblyバイナリが急増している理由の1つです。
WasmはC ++(または他の言語)について実際には何も知りません。したがって、Wasmランタイムは標準のC ++ライブラリを提供せず、コンパイラはそれを各バイナリファイルに追加する必要があります。しかし、そのようなコードは一度だけ接続する必要があります。したがって、大規模なプロジェクトの場合、これは結果として得られるWasmバイナリのサイズに大きな影響を与えません。これは、最終的には他のバイナリよりも小さいことがよくあります。
すべての場合において、バイナリのサイズのみを比較することによって情報に基づいた決定を下すことができるわけではないことは明らかです。たとえば、AssemblyScriptソースコードがWasmにコンパイルされている場合、バイナリは実際には非常にコンパクトであることがわかります。しかし、どれくらい速く実行されますか?私は、速度とサイズという2つの基準に基づいて、JSバイナリとASCバイナリの異なるバージョンを一度に比較するタスクを設定しました。
AssemblyScriptへの移植
すでに書いたように、TypeScriptとASCは構文とセマンティクスが非常に似ています。JSとの類似点があると簡単に推測できるため、移植は主に型注釈の追加(または型の置換)に関するものです。Glurの移植を開始するには 、画像をぼかすためのJSライブラリ。
データ型マッピング
組み込みのAssemblyScriptタイプは、Wasm仮想マシン(WebAssembly VM)タイプと同様に実装されます。たとえば、TypeScriptで数値タイプが64ビット浮動小数点数として実装されている場合(IEEE754標準に準拠)、ASCにはいくつかの数値タイプがあります:u8、u16、u32、i8、i16、i32 、f32、およびf64。さらに、一般的な複合データ型(string、Array、ArrayBuffer、Uint8Arrayなど)は 、 AssemblyScript標準ライブラリにあります。これらは、特定の予約があれば、TypeScriptとJavaScriptに存在します。ここでは、タイプマッピングテーブルAssemblyScript、TypeScript、Wasm VMについては考慮しません。これは、別の記事のトピックです。私が注意したい唯一のことは、ASCがStaticArrayタイプを実装していることです。これについては、JSとWebAssemblyVMで類似物を見つけていません。
最後に、glurライブラリのサンプルコードに目を向けます。
JavaScript:
function gaussCoef(sigma) {
if (sigma < 0.5)
sigma = 0.5;
var a = Math.exp(0.726 * 0.726) / sigma;
/* ... more math ... */
return new Float32Array([
a0, a1, a2, a3,
b1, b2,
left_corner, right_corner
]);
}
AssemblyScript:
function gaussCoef(sigma: f32): Float32Array {
if (sigma < 0.5)
sigma = 0.5;
let a: f32 = Mathf.exp(0.726 * 0.726) / sigma;
/* ... more math ... */
const r = new Float32Array(8);
const v = [
a0, a1, a2, a3,
b1, b2,
left_corner, right_corner
];
for (let i = 0; i < v.length; i++) {
r[i] = v[i];
}
return r;
}
AssemblyScriptコードフラグメントには、コンストラクターを介して配列を初期化する方法がないため、最後に追加のループが含まれています。ASCは関数のオーバーロードを実装していないため、この場合、コンストラクターFloat32Array(lengthOfArray:i32)は1つだけです。AssemblyScriptにはコールバックがありますが、クロージャがないため、.forEach()を使用して配列に値を入力する方法はありません。そのため、一度に1つの要素をコピーするには、通常のforループを使用する必要がありました。
上のコードスニペットでお気づきかもしれません AssemblyScript Math, Mathf. , 64- , — 32-. Math . - , , f32. . .
:
理解するのに長い時間がかかりました。タイプの選択は非常に重要です。画像のぼかしには畳み込み操作が含まれ、それはすべてのピクセルを通過するforループの全体です。すべてのピクセルインデックスが正の場合、ループカウンターも正になると考えるのは素朴でした。それらにu32タイプ(32ビットの符号なし整数)を選択するべきではありませんでした。これらのループのいずれかが反対方向に実行されると、無限になります(プログラムはループします)。
let j: u32;
// ... many many lines of code ...
for (j = width — 1; j >= 0; j--) {
// ...
}
移植に関して他の問題は見つかりませんでした。
D8シェルベンチマーク
さて、バイリンガルのコードスニペットの準備ができました。これで、ASCをWasmにコンパイルして、最初のベンチマークを実行できます。
d8について一言: これはV8エンジンのコマンドシェルです(それ自体には独自のインターフェイスがありません)。これにより、WasmとJSの両方で必要なすべてのアクションを実行できます。原則として、d8はノードと比較できます。ノードは突然標準ライブラリを切り落とし、純粋なECMAScriptのみが残りました。ロケールにV8のコンパイル済みバージョンがない場合(コンパイル方法は ここ で説明されています)、d8を使用することはできません。 d8をインストールするには、 jsvu ツールを使用します。
ただし、このセクションのタイトルには「ベンチマーク」という単語が含まれているため、ここに何らかの免責事項を記載することが重要です。受け取った数値と結果は、選択した言語で記述したコードを参照しています。私が作成したテストスクリプトを使用したコンピューター(2020 MacBook Air M1)。結果はせいぜい大まかなガイドラインです。したがって、それらに基づいて、WebAssemblyを使用したAssemblyScriptまたはV8を使用したJavaScriptのパフォーマンスの一般化された定量的推定値を提供するのは無謀です。
別の質問があるかもしれません:なぜd8を選択し、ブラウザーまたはノードでスクリプトを実行しなかったのですか?ブラウザとノードの両方が、私の実験には十分に無菌ではないと思います。必要な無菌性に加えて、d8はV8エンジンのパイプラインを制御することを可能にします。テストの途中でパフォーマンス特性が変化しないように、任意の最適化シナリオをキャプチャして、たとえば、Ignitionのみ、SparkplugまたはLiftoffのみを使用できます。
実験手法
上で書いたように、パフォーマンステストを実行する前にJavaScriptエンジンを「ウォームアップ」する機会があります。このウォームアッププロセス中に、V8は必要な最適化を行います。そのため、測定を開始する前にブラープログラムを5回実行し、次に50回の実行を実行し、最も速い5回と最も遅い5回の実行を無視して、潜在的な外れ値と多すぎる外れ値を削除しました。
何が起こったのか見てみましょう:

一方では、LiftoffがIgnitionやSparkplugと比較してより高速なコードを生成したことを嬉しく思いました。しかし、最適化を使用してWasmでコンパイルされたAssemblyScriptが、JavaScriptバンドルであるTurboFanよりも数倍遅いことが判明したという事実に戸惑いました。
後で私はそれでも力が最初は等しくなかったことを認めました:エンジニアの巨大なチームが長年JSとそのV8エンジンに取り組んでおり、最適化やその他の賢いことを実装しています。 AssemblyScriptは、小さなチームを持つ比較的若いプロジェクトです。 ASCコンパイラ自体はシングルパスであり、Binaryenライブラリにすべての最適化の努力を注ぎます ..。これは、ほとんどの高レベルのセマンティクスがすでにコンパイルされた後、WasmVMバイトコードレベルで最適化が行われることを意味します。ここでV8には明らかな利点があります。ただし、ぼかしコードは非常に単純です-これは、メモリからの値を使用した通常の算術演算です。ASCとWasmは、このタスクでよりうまくいくはずだったようです。ここで何が問題なのですか?
もっと深く掘り下げましょう
私はすぐにV8チームの賢い人とAssemblyScriptチームの同じように賢い人に相談しました(DanielとMaxに感謝します!)。 ASCをコンパイルするときに、「境界チェック」(境界値)が開始されないことが判明しました。
V8は、いつでもソースJSコードを調べて、そのセマンティクスを理解できます。この情報は、繰り返しまたは追加の最適化に使用されます。たとえば、バイナリデータのセットを含むArrayBufferがあります。この場合、V8は、メモリーセルを無秩序に実行するだけでなく、ループのfor ...を介してイテレーターを使用することが最も合理的であると想定しています。
for (<i>variable</i> of <i>iterableObject</i>) {
<i>statement</i>
}
この演算子のセマンティクスにより、配列の境界を超えないことが保証されます。したがって、TurboFanコンパイラは境界チェックを処理しません。ただし、ASCをWasmにコンパイルする前は、AssemblyScriptセマンティクスはそのような最適化には使用されません。すべての最適化はWebAssembly仮想マシンのレベルで実行されます。
幸いなことに、ASCの袖にはまだ切り札があります。チェックされていない()注釈です。これは、範囲外になる可能性についてチェックする必要がある値を示します。
--prev_prev_out_r = prev_src_r * coeff [6];
-行[line_index] = prev_out_r;
前の2行は、次のように書き直す必要があります。
+ prev_prev_out_r = prev_src_r * unchecked(coeff [6]);
+チェックを外しました(line [line_index] = prev_out_r);
はい、もっとあります。 AssemblyScriptでは、型付き配列(Uint8Array、Float32Arrayなど)がArrayBufferのイメージと類似性に実装されます。ただし、インデックスiの配列要素にアクセスするための高レベルの最適化がないため、メモリに2回アクセスする必要があります。1回目は最初の配列要素へのポインタをロードし、2回目はで要素をロードします。オフセットi * sizeOfType。つまり、配列を(ポインターを介して)バッファーとして参照する必要があります。 JSの場合、V8は単一のメモリアクセスを使用してアレイアクセスの高レベルの最適化を実行できるため、ほとんどの場合、これは発生しません。
パフォーマンスを向上させるために、AssemblyScriptは静的配列(StaticArray)を実装します。長さが固定されていることを除けば、配列に似ています。したがって、配列の最初の要素へのポインタを格納する必要はありません。可能であれば、これらの配列を使用してプログラムを高速化します。
それで、私はAssemblyScript-TurboFanバンチ(より速く動作しました)を取り、それをナイーブと呼びました。次に、このセクションで説明した2つの最適化を追加すると、optimizedというバリアントが得られました。

ずっといい!私たちは大きな進歩を遂げました。ただし、AssemblyScriptはJavaScriptよりも低速です。これが私たちにできることのすべてですか?[ネタバレ:いいえ]
ああ、これらの沈黙
AssemblyScriptチームのメンバーは、-optimizeフラグは-O3と同等であるとも言っていました。作業速度を適切に最適化しますが、同時にバイナリファイルの増大を防ぐため、最大にはなりません。 -O3フラグは速度のみを最適化し、最後まで最適化します。 Web開発ではバイナリのサイズを小さくするのが通例なので、デフォルトで-O3を使用するのは正しいようですが、それだけの価値はありますか?少なくともこの特定の例では、答えはノーです。-O3sはわずか約30バイトを節約しますが、パフォーマンスの大幅な低下を見落とします。

単一のオプティマイザーフラグがゲームをひっくり返すだけです。最後に、AssemblyScriptがJavaScriptを追い越しました(この特定のテストケースでは!)。
表にO3フラグを表示しなくなりますが、ご安心ください。これから記事の終わりまで、O3フラグは表示されません。
バブルソート
ぼやけた例が単なる事故ではないことを確認するために、私は別の例をとることにしました。StackOverflowで並べ替えの実装を行い、同じプロセスを実行しました。
- タイプを追加してコードを移植しました。
- テストを開始しました。
- 最適化;
- テストを再度実行しました。
(バブルソート用の配列の作成と入力はテストしていません)。
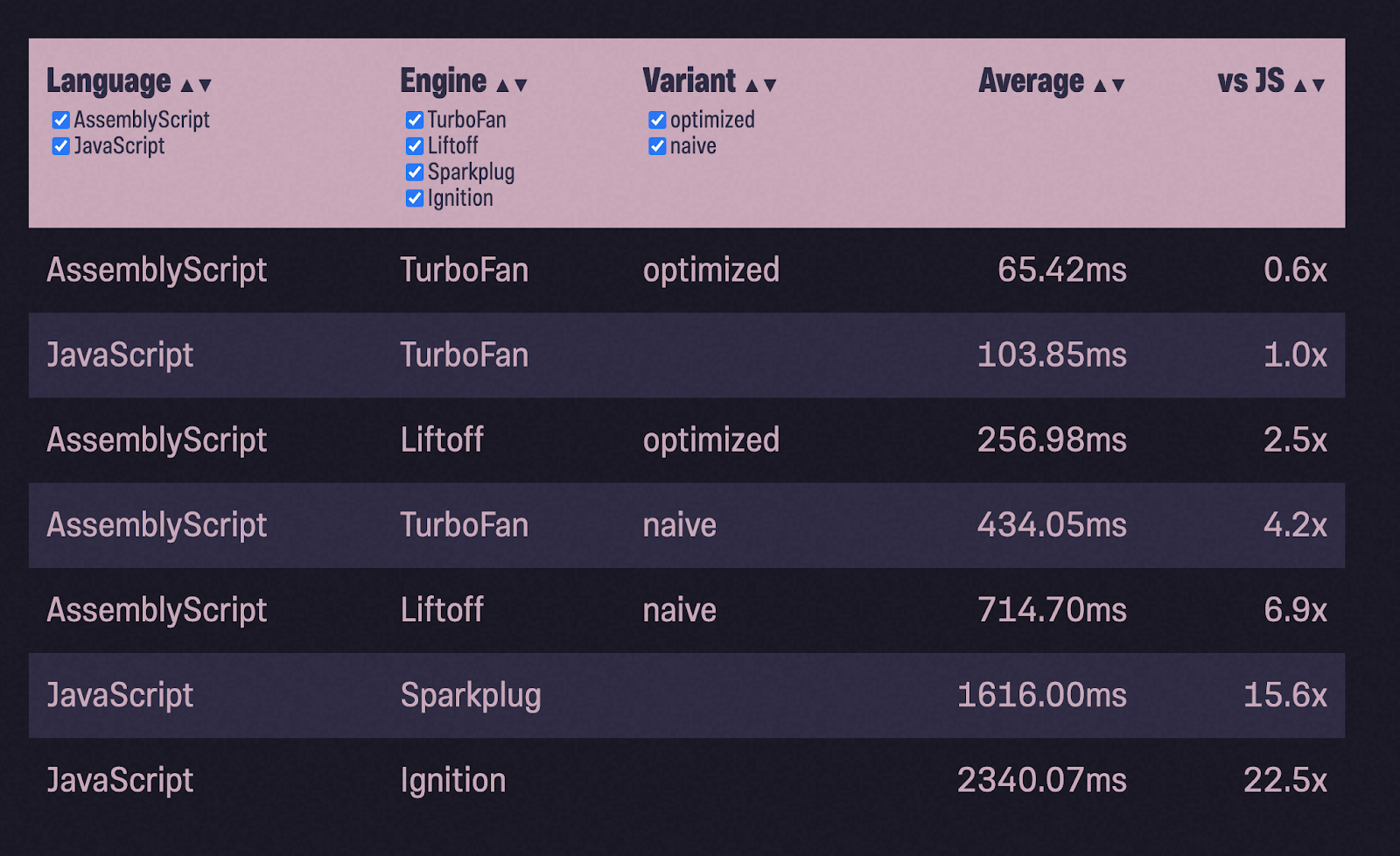
またやりました!今回はさらに大きな速度向上が見られます。最適化されたAssemblyScriptはJavaScriptのほぼ2倍の速度です。しかし、それだけではありません。さらなる浮き沈みが再び私を待っています。切り替えないでください!
メモリ管理
これらの例はどちらも、メモリの操作方法を実際には示していないことに気付いた方もいらっしゃるかもしれません。JavaScriptでは、V8がすべてのメモリ管理(およびガベージコレクション)を処理します。一方、WebAssemblyでは、線形メモリのチャンクができてしまい、その使用方法を決定する必要があります(または、Wasmが決定する必要があります)。ヒープを集中的に使用すると、テーブルはどのくらい変化しますか? バイナリヒープの
実装で新しい例をとることにしました ..。テスト中に、ヒープに100万個の乱数を入力し(Math.random()の提供)、pop()がそれらを返し、番号が昇順であるかどうかを確認します。一般的な作業スキームは同じです。JSコードをASCに移植し、単純な構成でコンパイルし、テストを実行し、最適化して、テストを再実行します。
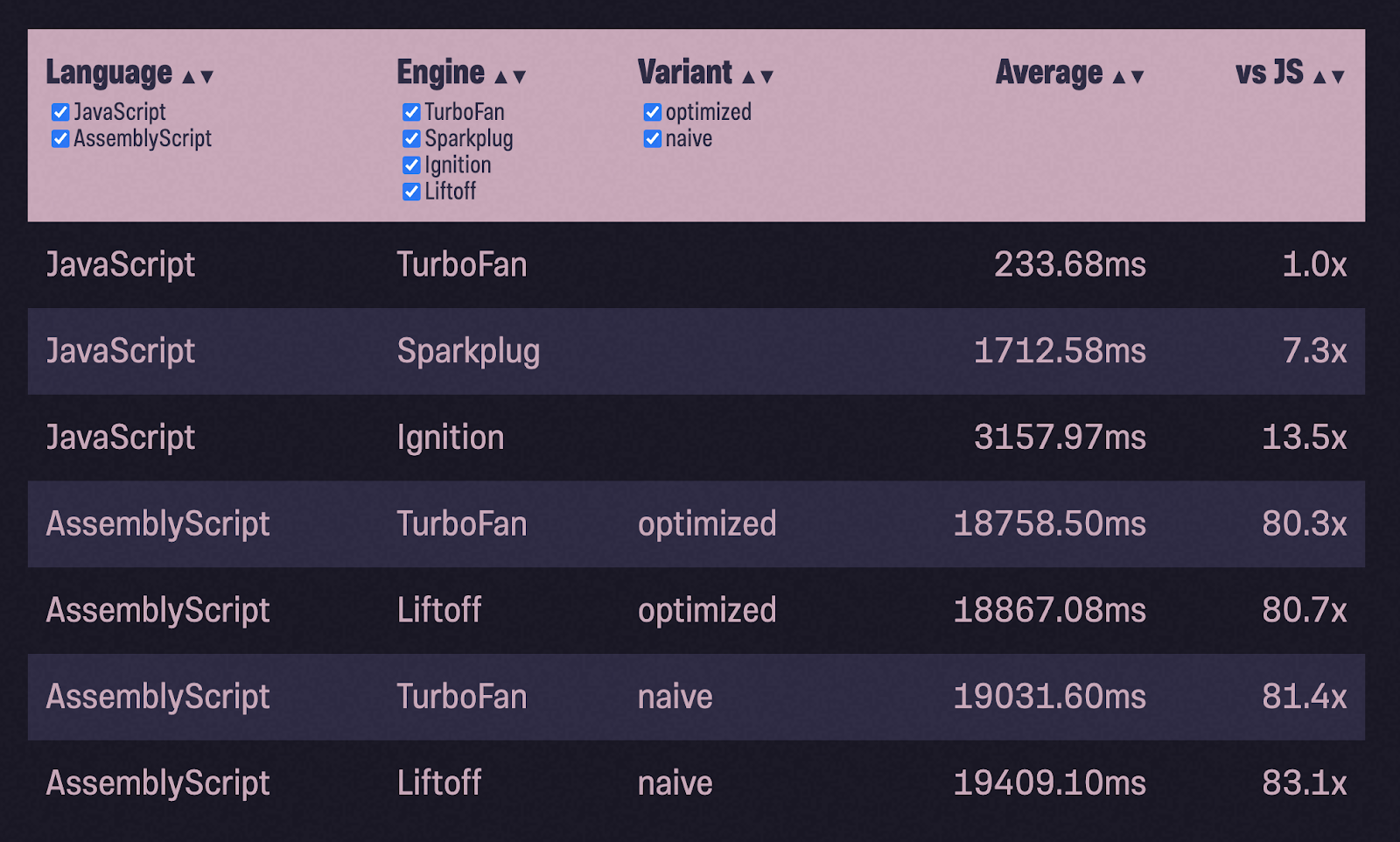
TurboFanを使用したJavaScriptよりも80倍遅い?!そして、イグニッションより6倍遅い!何が悪かったのか?
ランタイム環境のセットアップ
AssemblyScriptで生成するすべてのデータは、メモリに保存する必要があります。ただし、すでに存在するものを上書きしないようにする必要があります。 AssemblyScriptはJavaScriptの動作を模倣する傾向があるため、ガベージコレクターもあり、コンパイルすると、このコレクターがWebAssemblyモジュールに追加されます。 ASCは、いつ割り当て、いつメモリを解放するかについて心配する必要はありません。
このモード(インクリメンタルと呼ばれる)では、デフォルトで機能します。同時に、gzipアーカイブの約2KBのみがWasmモジュールに追加されます。 AssemblyScriptは、最小モードとスタブモードの代替モードも提供します。モードは、-runtimeフラグを使用して選択できます。 Minimalは同じメモリアロケータを使用しますが、自動的には起動しないが手動で呼び出す必要がある軽量のガベージコレクタです。これは、ガベージコレクターがプログラムを一時停止するタイミングを制御する高性能アプリケーション(ゲームなど)を開発する場合に役立ちます。スタブモードでは、Wasmモジュールに追加されるコードはごくわずかです(gzip形式で約400B)。バックアップアロケータが使用されているため、迅速に機能します(アロケータの詳細はここに記載されてい ます)。
冗長アロケータは非常に高速ですが、メモリを解放することはできません。ばかげているように聞こえるかもしれませんが、タスクの完了後にメモリを解放する代わりにWebAssemblyインスタンス全体を削除して新しいインスタンスを作成する、モジュールの「1回限りの」インスタンスに役立ちます。
モジュールがさまざまなモードでどのように機能するかを見てみましょう。

最小限とスタブの両方で、JavaScriptのパフォーマンスのレベルに大幅に近づきました。なんでだろう?上記のように、最小および増分は同じアロケータを使用します。どちらにもガベージコレクターがありますが、明示的に呼び出されない限り、minimalはガベージコレクターを実行しません(私はそうしません)。つまり、インクリメンタルはガベージコレクションを自動的に開始し、多くの場合、不必要に収集を開始します。さて、1つのアレイのみを追跡する必要があるのに、なぜこれが必要なのですか?
メモリ割り当ての問題
Wasmモジュールをデバッグモード(--debug)で数回実行した後、libsystem_platform.dylibライブラリが原因で作業速度が低下することがわかりました。これには、スレッド化とメモリ管理のためのOSレベルのプリミティブが含まれています。このライブラリへの呼び出しは__new()と__renew()から行われ、これらは配列#pushから呼び出され ます。わかりました:ここにメモリ管理の問題があります。しかし、JavaScriptはどういうわけか、増え続ける配列を迅速に処理することができます。では、なぜAssemblyScriptはこれを実行できないのでしょうか。幸い、AssemblyScript標準ライブラリソースは 公開されているので、Arrayクラスのこの不吉なpush()関数を見てみましょう。
[Bottom up (heavy) profile]:
ticks parent name
18670 96.1% /usr/lib/system/libsystem_platform.dylib
13530 72.5% Function: *~lib/rt/itcms/__renew
13530 100.0% Function: *~lib/array/ensureSize
13530 100.0% Function: *~lib/array/Array#push
13530 100.0% Function: *binaryheap_optimized/BinaryHeap#push
13530 100.0% Function: *binaryheap_optimized/push
5119 27.4% Function: *~lib/rt/itcms/__new
5119 100.0% Function: *~lib/rt/itcms/__renew
5119 100.0% Function: *~lib/array/ensureSize
5119 100.0% Function: *~lib/array/Array#push
5119 100.0% Function: *binaryheap_optimized/BinaryHeap#push
export class Array<T> {
// ...
push(value: T): i32 {
var length = this.length_;
var newLength = length + 1;
ensureSize(changetype<usize>(this), newLength, alignof<T>());
// ...
return newLength;
}
// ...
}
これまでのところ、すべてが正しいです。配列の新しい長さは現在の長さに等しく、1増加します。次に、ensureSize()関数を呼び出して、バッファに十分な容量(Capacity)があることを確認します。新しい要素。
function ensureSize(array: usize, minSize: usize, alignLog2: u32): void {
// ...
if (minSize > <usize>oldCapacity >>> alignLog2) {
// ...
let newCapacity = minSize << alignLog2;
let newData = __renew(oldData, newCapacity);
// ...
}
}
次に、ensureSize()関数は次のことをチェックします。容量は新しいminSizeよりも小さいですか?その場合は、_renew()関数を使用して新しいminSizeバッファーを割り当てます。これには、古いバッファから新しいバッファにすべてのデータをコピーする必要があります。このため、配列を100万個の値(要素を次々に)で埋めるテストでは、大量のメモリが再割り当てされ、大量のガベージが作成されます。
他のライブラリ( Rustまたはスライスのstd :: vecなど) Go)では、新しいバッファの容量は古いバッファの2倍であるため、メモリを操作するプロセスのコストと速度が低下します。私はASCでこの問題に取り組んでいます。これまでのところ、唯一の解決策は、独自のメモリ最適化を使用して独自のCustomArrayを作成することです。

現在、インクリメンタルは最小およびスタブと同じくらい高速です。しかし、JavaScriptはこのテストケースのリーダーであり続けます。言語レベルでさらに最適化を行うこともできますが、これはAssemblyScript自体を最適化する方法に関する記事ではありません。私はすでに十分に深く沈んでいます。
AssemblyScriptコンパイラが私のために行うことができる多くの簡単な最適化があります。この目的のために、ASCチームは、AIRと呼ばれる高レベルのIR(中間表現)オプティマイザーに取り組んでいます。これにより、ジョブが高速化され、毎回手動でアレイアクセスを最適化する必要がなくなりますか?最も可能性が高い。JavaScriptよりも高速ですか?言いにくい。しかし、いずれにせよ、ASCを競い、JSの機能を評価し、「非常にスマートな」コンパイルツールを備えたより「成熟した」言語が何を達成できるかを確認することは私にとって興味深いことでした。
Rust&C ++
私はRustでコードをできるだけ慣用的に書き直し、WebAssemblyにコンパイルしました。 AssemblyScript(ナイーブ)よりは高速ですが、CustomArrayを使用して最適化されたAssemblyScriptよりは低速であることが判明しました。次に、AssemblyScriptとほぼ同じ方法で、Rustからコンパイルされたモジュールを最適化しました。この最適化により、RustベースのWasmモジュールは最適化されたAssemblyScriptよりも高速ですが、JavaScriptよりも低速です。
私はC ++に対して同じアプローチを取り、Emscriptenを使用してWebAssemblyにコンパイルしました 。驚いたことに、最適化を行わない最初のオプションでさえ、JavaScriptよりも悪くはないことがわかりました。

ここに画像のURLはありません。自分でスクリーンショットを撮りました。
慣用句としてマークされ た バージョンは、とにかくJSソースコードの影響を受けました。Rust、C ++のイディオムに関する知識を使おうとしましたが、移植を行っていたので、インストールはしっかりと頭の中にありました。これらの言語の経験が豊富な人なら、タスクを最初から実装でき、コードは異なって見えると確信しています。
RustおよびC ++モジュールはさらに高速に実行できると確信しています。しかし、私はこれらの言語について十分な深い知識を持っていなかったので、それらからより多くを絞り出すことができませんでした。
再びバイナリのサイズについて
gzip圧縮後のバイナリのサイズを見てみましょう。RustやC ++と比較すると、AssemblyScriptバイナリは確かにはるかに軽量です。
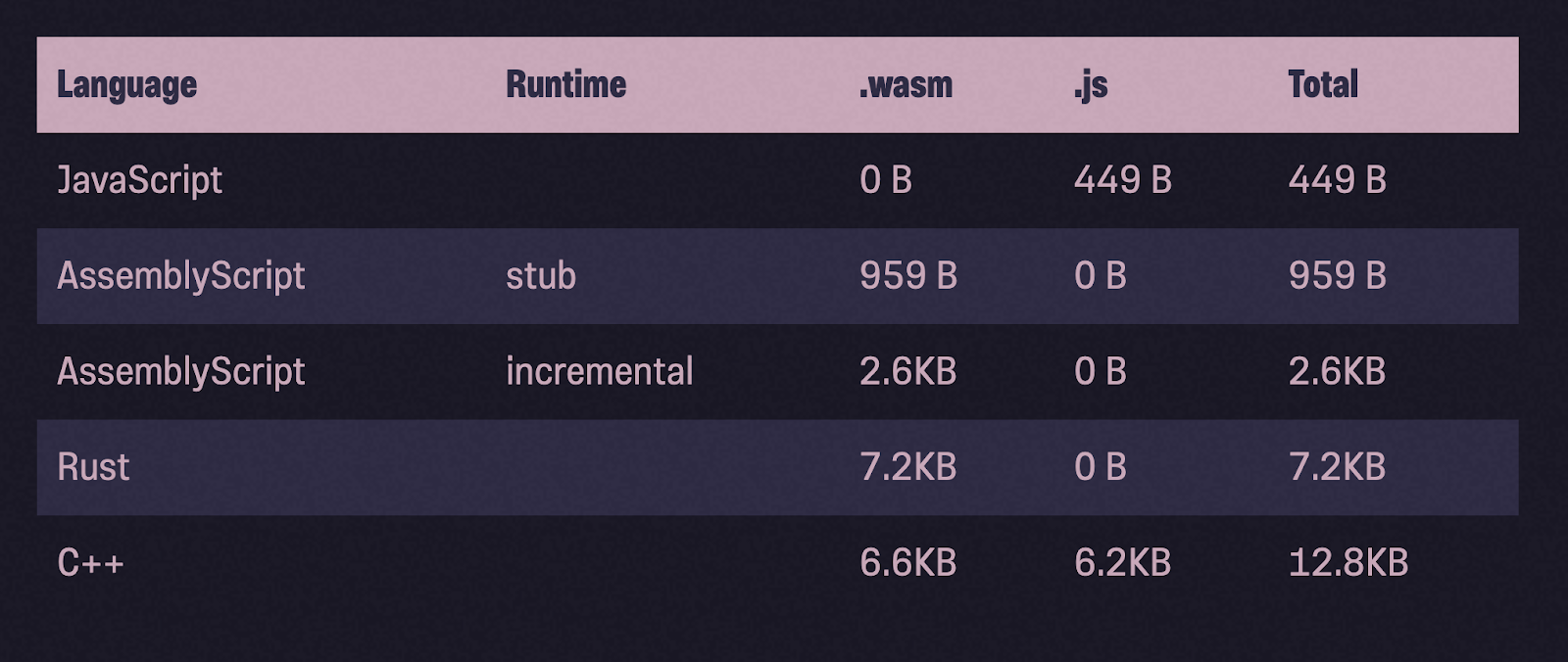
それでも...推奨事項
これについては記事の冒頭で書きましたが、ここで繰り返します。結果はせいぜいおおよそのガイドラインです。したがって、それらに基づいて生産性の一般化された定量的推定を与えることは無謀でしょう。たとえば、すべての場合でRustがJavaScriptより1.2倍遅いとは言えません。これらの数値は、私が作成したコード、適用した最適化、および使用したマシンに大きく依存します。
それでも、トピックをよりよく理解し、より良い決定を下すのに役立つ一般的なガイドラインがいくつかあると思います。
- Liftoff AssemblyScript Wasm-, , , Ignition SparkPlug JavaScript. JS-, WebAssembly — .
- V8 JavaScript-. WebAssembly , JavaScript, , .
- , , .
- AssemblyScriptモジュールは、通常、他の言語からコンパイルされたWasmモジュールよりもはるかに軽量です。この記事では、AssemblyScriptバイナリはJavaScriptバイナリよりも小さくはありませんでしたが、ASC開発チームが述べているように、より大きなモジュールの場合は逆になります。
あなたが私を信じていない(そしてあなたが信じる必要がない)、そしてあなた自身でテストケースのコードを理解したいのなら、 ここにあります。
当社の サーバーはWebAssemblyの開発に使用できます。
上記のリンクを使用するか、バナーをクリックして登録すると、任意の構成のサーバーをレンタルした最初の月が10%割引になります。
