午後1時30分頃、航空と鉄道の切符の検索の負荷が急激に増加しました。この時点で、ロシア鉄道がWebサイトとアプリケーションの中断を報告し、すべてのデータセンターにバックエンドの追加インスタンスを緊急に投入し始めました。
しかし実際には、問題はもっと早く始まりました。午前8時頃、監視により、データベースレプリカの1つに、疑わしいほど多くの長期的なプロセスがあるという事実に関するアラートが送信されました。しかし、それはそれほど重要ではないと考えて、私たちはそれを見逃しました。
入門
私たちのインフラストラクチャは、ほぼ20年の開発で大幅に成長しました。アプリケーションは3つのプラットフォーム上に存在します- モノリスの古いphpコード、マイクロサービスの最初のバージョンは自作のオーケストレーションを備えたプラットフォーム上にあり、2番目の戦略的に正しいのはOKDであり、go、php、nodejsサービスが存在します。このすべての周りに、HAのバインディングを備えた数十のmysqlベース(モノリスにサービスを提供するメインの「ガーランド」、およびマイクロサービス用の多くのマスターとホットスタンバイのペア)があります。それらに加えて、memkesh、kafkas、mongas、radishes、elasticsも単一のコピーからはほど遠いです。 Nginxと フロントプロキシとしての使節。すべて が3つのネットワークロケーションに存在し、それらのいずれかが失われてもユーザーに影響を与えないという仮定から進めます。
-: mysql
3つのロードされた製品があります。入力トラフィックが多い列車のスケジュール。長距離列車の鉄道スケジュールと鉄道チケットの購入と予約-交通量が多く、検索がより困難です。非常に難しい検索、多段階キャッシュ、「プラスマイナス3日」の転送とフォークによる多くのオプションを備えた航空。昔は、3つの製品すべてがモノリスにしか存在していなかったため、個々のパーツをゆっくりとマイクロサービスに移行し始めました。最初に解体されたのは電車でした。通常、5月のピークが電車に降りかかるにもかかわらず、新しいアーキテクチャは非常に便利で、負荷の増加に合わせて簡単に拡張できます。航空の場合、モノリスの大部分が盗まれ、P日目の瞬間に地理的サジェストのA / Bテストが1週間行われていました。実装の2つのバージョンを比較しました-新しいもの、elasticsearch、および古いmysqlについて。 4月15日のローンチの時点で、彼らはすでに多くの問題を抱えていましたが、すぐに思いつき、コードを修正し、二度と起動しないことを決定しました。
ショット。古いバージョンは、mysqlでの全文検索とランキングの独自の実装であることに注意してください。最善の解決策ではありませんが、実績があり、ほとんど機能しています。問題は、テーブルのいずれかが大幅に断片化されたときに始まり、その後、参加しているすべてのクエリの速度が低下し、システムに大きな負荷がかかり始めます。そして、明らかに、午前8時に、アラートによって報告されたこの断片化のしきい値を超えました。このようなまれですが、まだ予想される状況に対する標準的な反応は、負荷から鈍いレプリカを取り出し(proxysqlのプロキシレイヤーを使用すると、これは簡単に実行できます)、optimize + analyzeを実行してから戻すことです。通常の負荷での通常時のパワーリザーブを考慮すると、これは問題になりません。しかし、ここでは、静かな時間に、このアラートを処理しませんでした。
13:20
この頃、5月の休日や休業日についてのニュースが聞こえてきます。
13:30頃のピークトラフィック
後でわかったように、追加の週末(週末ではなく、「週末」)の発表からわずか数分後に、トラフィックが増加し始めました。負荷が急激に増加しました。ピーク時には標準から2.5〜3倍であり、これは数時間続いた。
私たちはほとんどすぐに「緊急警報」、つまり重要度レベルの警報「目を覚まして修正する」に襲われました。まず第一に、フロントプロキシからクライアントに送信する50 *エラーの増加に関するアラートでした。以下のレベルでは、データベース接続エラーのアラートがトリガーされ、ログに次のようなものが表示されました:「DB:3162ms後にホストグループ102に到達中に最大接続タイムアウトに達しました」。さらに、古いモノリシックプラットフォームのアプリケーションサーバーの3つのグループの容量不足について警告します。最も純粋な形で嵐を警告します。
理由のアイデアは、着信リクエストでスケジュールに入る前でさえ、ほぼ瞬時に来ました-「休暇」に関するニュースは、チャットの内部通信ですでにフラッシュされていました。
ほぼ完全なAchtungの状況で少し感覚をつかんだ後、彼らは反応し始めました。アプリケーションサーバーを拡張し、アプリケーションとベース間のインターフェイスでエラーを処理します。私たちは、朝に「燃えている」警告をすぐに思い出し、病んでいる発言のプロセスリストに地理サッジからの古い知人を見つけました。 aviaチームに連絡したところ、過去15年間も接近していない、4月末のトラフィックの増加が現実のものであることが確認されました。そして、これは攻撃ではなく、ある種のバランスの問題ではなく、自然なライブユーザーです。そして、彼らの活発な要求の下で、すでに過負荷になっているレプリカは完全に具合が悪くなりました。
DBAであるAlexeyは、レプリカを負荷から解放し、長寿命のプロセスを釘付けにし、標準のテーブル最適化手順に従いました。これはすべて高速で数分ですが、この間、このようなトラフィックの下で、残りのレプリカはさらに悪化しました。私たちはこれを理解しましたが、私たちはそれを最も悪の少ないものとして選びました。
ほぼ並行して、13:40頃に新しいアプリケーションサーバーが投入され始めました。この負荷は、それ自体ですぐになくなるのではなく、大きくなる可能性があり、モノリシック部分のプロセス自体はそうではないことに気づきました。とても早い。
ベース操作はしばらくの間役に立ちました。午後1時50分から午後2時30分頃まで、すべてが穏やかでした。
2番目のピーク-14:30頃
その瞬間、監視はロシア鉄道のウェブサイトがダウンしていることを私たちに知らせました。ええと、実際、彼は列車のバックエンドが悪化したと言っていました、そして私たちは後でニュースが出たときにロシア鉄道について学びました 。リアルタイムでは、このように見えました。

負荷はロシア鉄道のウェブサイトでの中断に関連しているよう
です。残念ながら、列車はほとんどがモノリスに住んでおり、新しいバックエンドを追加することによってのみアプリケーションレベルでスケーリングできます。そして、これは、私が上で書いたように、遅い手順であり、加速するのが難しいです。したがって、残ったのは、すでに開始されている自動化が機能するまで待つことだけでした。もちろん、マイクロサービスではすべてがはるかに単純ですが、移動自体は...それは別の話ですが。
待つのは退屈ではありませんでした。約5分で、システムのボトルネックは、まだ完全には明確ではない方法で、アプリケーション層からデータベース層、ベース自体、またはproxysqlに「プッシュ」されました。そして14:40までに、メインのmysqlクラスターへの書き込みを完全に停止しました。そこで何が起こったのか、私たちはまだ理解していませんが、マスターをホットスタンバイリザーブに変更することは助けになりました。そして10分後に私たちは記録を返しました。同じ頃、彼らは全荷重をサジェットからエラスティックに強制的に移すことに決め、ABキャンペーンの結果を犠牲にしました。それがどれだけ役に立ったか、彼らも気づいていませんでしたが、それは確かに悪化しませんでした。
15:00
記録が現実のものとなり、すべてが正常に行われるはずであり、レプリカとその前のproxysqlへの負荷は正常です。ただし、何らかの理由で、アプリケーションからデータベースへの読み取り要求中のエラーは終了しません。さまざまなレイヤーのグラフに固執し、少なくともいくつかのパターンを検索してから約15〜20分で、エラーは1つのproxysqlからのみ発生することがわかりました。再起動するとエラーはなくなりました。根本的な原因は、失敗の詳細な分析とともに、ずっと後に掘り下げられました。 1週間前の最後の緊急事態で、sagestに関するABキャンペーンの開始時に、proxysqlがガーランドのレプリカの1つへの接続を正しく閉じず、それが操作されたことが判明しました。そして、proxysqlのこのインスタンスでは、発信トラフィック用のポートが不足していることに愚かにも遭遇しました。もちろん、このメトリックはそうなるでしょうが、アラートを切ることは私たちには決して起こりませんでした。今、それはすでにそこにあります。
15:20
電車を除くすべての製品が復元されました。
15:50
終電のバックエンドが延長されました。通常は2時間ではなく1時間かかりますが、ここではストレスの多い状況で彼ら自身が少し混乱しました。
よくあることですが、ある場所で修理され、別の場所で壊れました。バックエンドはより多くの接続を受け入れ始め、フロントプロキシはアップストリームのオーバーフローのためにクライアント要求をより少なくドロップし始め、その結果、内部サービス間トラフィックが増加しました。そして、承認サービスがありました。これはマイクロサービスですが、OKDではなく、古いプラットフォーム上にあります。スケーリングはモノリスよりも単純ですが、OKDよりも劣ります。それを約15分間持ち上げ、パラメーターを数回ひねって容量を追加しましたが、最終的には機能しました。
16:10
やったー、すべてが機能している、あなたは昼食に行くことができます。
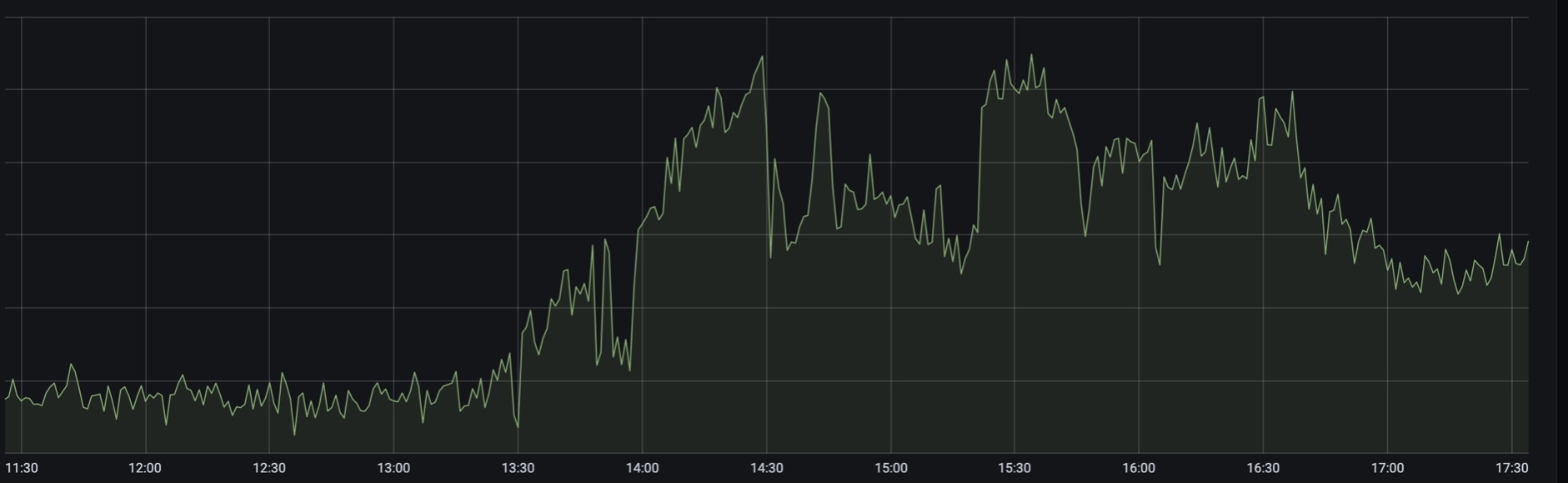
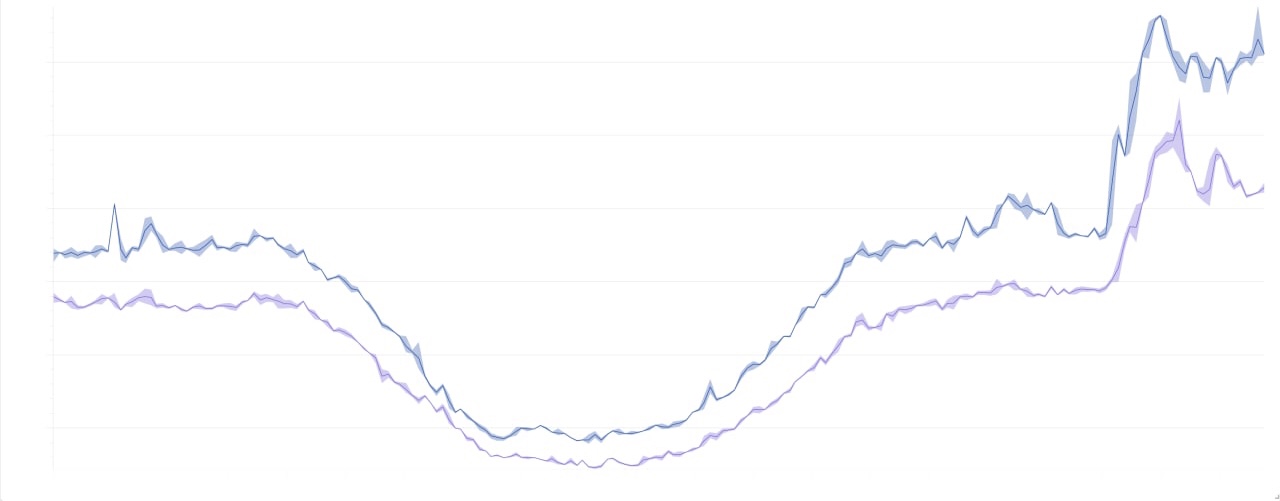
美しい写真
それらは完全に有益ではないので美しいですが、軸は安全保障理事会によってテストされていません。
500年代のグラフ:

2日間の負荷の全体像:
キャプテンからの結論
- 今夜はありがとうございました。
- アラートについて何かする必要があります。すでにたくさんありますが、それでも足りないこともあれば、数量を含めて完売することもあります。また、新しいアラートが発生するたびに、サポートのコストが増加します。一般的に、問題の理解はまだありますが、戦略的な解決策はありません。プロセスとツールの接合部のどこかに隠れているので、私たちは探しています。しかし、私たちはすでにいくつかのアラートに戦術的に取り組んでいます。
- . , - proxysql , . , .
- , OKD . .
- . , , , .