こんにちは、読者の皆様!この資料は本質的に理論的なものであり、BI分析に最初に遭遇した初心者のアナリストのみを対象としています。
この概念によって伝統的に理解されていることは何ですか?簡単に言うと、これは、データを収集、処理、分析し、最終結果をグラフ、チャート、表の形式で表示するための複雑なシステム(たとえば、予算編成など)です。
これには、一度に複数の専門家による十分に調整された作業が必要です。データエンジニアはストレージとETL / ELTプロセスを担当し、データアナリストはデータベースへの入力を支援し、BIアナリストはダッシュボードを開発し、ビジネスアナリストはレポートの顧客とのコミュニケーションを簡素化します。ただし、このオプションは、会社がチームの作業に対して支払う準備ができている場合にのみ可能です。ほとんどの場合、中小企業はコストを最小限に抑えるために1人の担当者に依存しています。この担当者は、BIの分野で幅広い見通しを持っていないことがよくありますが、レポートプラットフォームについてはうなずきます。
この場合、次のことが起こります。データの収集、処理、および分析は、単一のツール(BIプラットフォーム自体)の力によって行われます。この場合、データは事前にクリアされることはなく、コンポジットを通過しません。情報の収集は、中間ストレージの参加なしに一次情報源から行われます。このアプローチの結果は、テーマ別のフォーラムで簡単に確認できます。 BIツールに関するすべての質問を要約しようとすると、おそらく次のことが上位に分類されます。構造が不十分なデータをシステムにロードする方法、それらから必要なメトリックを計算する方法、レポートが実行されている場合の対処方法非常にゆっくり。驚いたことに、これらのフォーラムでは、ETLツール、データウェアハウスの経験、プログラミングのベストプラクティス、およびSQLクエリについての議論はほとんどありません。さらに、私は繰り返し事実に出くわしました経験豊富なBIアナリストは、すべての問題はBIプラットフォームによってのみ解決できるという事実を引用して、R / Python / Scalaの使用についてあまりお世辞を言っていませんでした。同時に、有能な日付エンジニアリングにより、BIレポートを作成するときに多くの問題を解決できることを誰もが理解しています。
-. , . -, , , -, .
«Data – BI» . . (-) (csv, txt, xlsx . .).
. . , . , , . BI .
. (, 1). , . ( , , . .). BI-, . .
«Data – DB – BI» , , . , , .
. , . . SQL ( ), BI-. .
. , . . . SQL.
«Data – ETL – DB – BI» . ETL- , R/Python/Scala . . . .
. , . . BI-.
. ETL- SQL. . , .
. «» SQLite. , (). E-Commerce Data Kaggle.
#
import pandas as pd
#
pd.set_option('display.max_columns', 10)
pd.set_option('display.expand_frame_repr', False)
path_dataset = 'dataset/ecommerce_data.csv'
#
def func_main(path_dataset: str):
#
df = pd.read_csv(path_dataset, sep=',')
#
list_col = list(map(str.lower, df.columns))
df.columns = list_col
# -
df['invoicedate'] = df['invoicedate'].apply(lambda x: x.split(' ')[0])
df['invoicedate'] = pd.to_datetime(df['invoicedate'], format='%m/%d/%Y')
#
df['amount'] = df['quantity'] * df['unitprice']
#
df_result = df.drop(['invoiceno', 'quantity', 'unitprice', 'customerid'], axis=1)
#
df_result = df_result[['invoicedate', 'country', 'stockcode', 'description', 'amount']]
return df_result
#
def func_sale():
tbl = func_main(path_dataset)
df_sale = tbl.groupby(['invoicedate', 'country', 'stockcode'])['amount'].sum().reset_index()
return df_sale
#
def func_country():
tbl = func_main(path_dataset)
df_country = pd.DataFrame(sorted(pd.unique(tbl['country'])), columns=['country'])
return df_country
#
def func_product():
tbl = func_main(path_dataset)
df_product = tbl[['stockcode','description']].\
drop_duplicates(subset=['stockcode'], keep='first').reset_index(drop=True)
return df_product
Extract Transform. , . . , , .
#
import pandas as pd
import sqlite3 as sq
from etl1 import func_country,func_product,func_sale
con = sq.connect('sale.db')
cur = con.cursor()
##
# cur.executescript('''DROP TABLE IF EXISTS country;
# CREATE TABLE IF NOT EXISTS country (
# country_id INTEGER PRIMARY KEY AUTOINCREMENT,
# country TEXT NOT NULL UNIQUE);''')
# func_country().to_sql('country',con,index=False,if_exists='append')
##
# cur.executescript('''DROP TABLE IF EXISTS product;
# CREATE TABLE IF NOT EXISTS product (
# product_id INTEGER PRIMARY KEY AUTOINCREMENT,
# stockcode TEXT NOT NULL UNIQUE,
# description TEXT);''')
# func_product().to_sql('product',con,index=False,if_exists='append')
## ()
# cur.executescript('''DROP TABLE IF EXISTS sale;
# CREATE TABLE IF NOT EXISTS sale (
# sale_id INTEGER PRIMARY KEY AUTOINCREMENT,
# invoicedate TEXT NOT NULL,
# country_id INTEGER NOT NULL,
# product_id INTEGER NOT NULL,
# amount REAL NOT NULL,
# FOREIGN KEY(country_id) REFERENCES country(country_id),
# FOREIGN KEY(product_id) REFERENCES product(product_id));''')
## ()
# cur.executescript('''DROP TABLE IF EXISTS sale_data_lake;
# CREATE TABLE IF NOT EXISTS sale_data_lake (
# sale_id INTEGER PRIMARY KEY AUTOINCREMENT,
# invoicedate TEXT NOT NULL,
# country TEXT NOT NULL,
# stockcode TEXT NOT NULL,
# amount REAL NOT NULL);''')
# func_sale().to_sql('sale_data_lake',con,index=False,if_exists='append')
## (sale_data_lake) (sale)
# cur.executescript('''INSERT INTO sale (invoicedate, country_id, product_id, amount)
# SELECT sdl.invoicedate, c.country_id, pr.product_id, sdl.amount
# FROM sale_data_lake as sdl LEFT JOIN country as c ON sdl.country = c.country
# LEFT JOIN product as pr ON sdl.stockcode = pr.stockcode
# ''')
##
# cur.executescript('''DELETE FROM sale_data_lake''')
def select(sql):
return pd.read_sql(sql,con)
sql = '''select *
from (select s.invoicedate,
c.country,
pr.description,
round(s.amount,1) as amount
from sale as s left join country as c on s.country_id = c.country_id
left join product as pr on s.product_id = pr.product_id)'''
print(select(sql))
cur.close()
con.close()
(Load) . . . , . .
SQL, . , BI-.
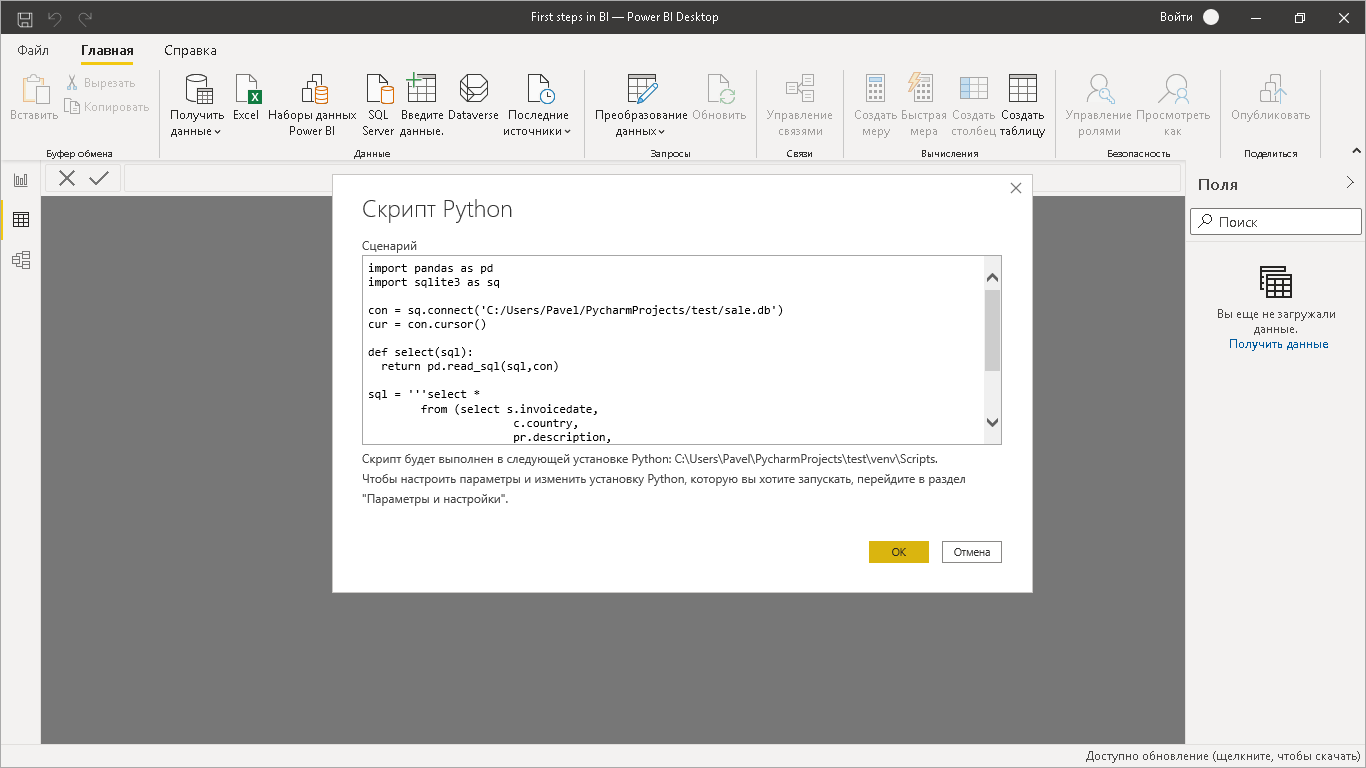
BI- SQLite Python.
import pandas as pd
import sqlite3 as sq
con = sq.connect('C:/Users/Pavel/PycharmProjects/test/sale.db')
cur = con.cursor()
def select(sql):
return pd.read_sql(sql,con)
sql = '''select *
from (select s.invoicedate,
c.country,
pr.description,
replace(round(s.amount,1),'.',',') as amount
from sale as s left join country as c on s.country_id = c.country_id
left join product as pr on s.product_id = pr.product_id)'''
tbl = select(sql)
print(tbl)
.
«Data – Workflow management platform + ETL – DB – BI» . .
. . .
. . BI. .
«Data – Workflow management platform + ELT – Data Lake – Workflow management platform + ETL – DB – BI» , : (Data Lake), (DB), .
. . , Data Lake.
. . Data Lake – , .
.
BI- .
BI , .
, SQL, - , , , .
それで全部です。すべての健康、幸運、そしてプロとしての成功!