ここで前の投稿を参照してください。
サンプルと母集団
統計科学では、「サンプル」と「母集団」という用語には特別な意味があります。母集団、または一般的な母集団は、研究者が理解したい、または結論を導き出すためのオブジェクトのすべてのセットです。たとえば、19世紀の後半に、遺伝学の創設者であるGregor Johan Mendel)は、エンドウ豆の植物についての観察を記録しました。彼が実験室の条件で非常に特定の植物の品種を研究したという事実にもかかわらず、彼の仕事は、絶対にすべての可能な種類のエンドウ豆の遺伝の根底にある基本的なメカニズムを理解することでした。
統計科学では、調査対象のオブジェクトが生物であるかどうかに関係なく、サンプルが抽出されるオブジェクトのグループは母集団と呼ばれます。
メンデルのエンドウ豆の場合のように、母集団は大きくなる可能性があるため、または無限になる可能性があるため、代表的なサンプルを調査し、母集団全体について結論を出す必要があります。サンプルの測定可能な属性と母集団の使用できない属性を明確に区別するために、サンプル属性を参照して統計という用語を使用し、母集団属性を参照してパラメーターについて説明します。
統計は、サンプルに基づいて測定できる属性です。パラメータは、統計的に導き出そうとしている母集団の属性です。
実際には、数式で異なる記号を使用しているため、統計とパラメータは異なります。
測定する |
サンプル統計 |
母集団パラメータ |
ボリューム |
n |
N |
平均 |
バツ |
μ X |
標準偏差 |
S x |
σ X |
標準エラー |
S X |
|
あなたが戻って標準誤差方程式に行く場合は、それがサンプルの標準偏差から計算されていないことがわかりますSは、xは、しかし、母集団の標準偏差からσのx。これは逆説的な状況を生み出します-導出しようとしている母集団パラメータを使用してサンプル統計を計算することはできません。しかし、実際には、サンプルと母集団の標準偏差の順のサンプルサイズについて同じであると仮定されるN ≥30。
. , , , 1 :
def ex_2_8():
'''
'''
may_1 = '2015-05-01'
df = with_parsed_date( load_data('dwell-times.tsv') )
filtered = df.set_index( ['date'] )[may_1]
se = standard_error( filtered['dwell-time'] )
print(' :', se)
: 3.627340273094217
, — 3.6 . 3.7 . , , , , .
, , , , — , , , . , , .
« » « », , .
. «confidence» , . (trust), . . -
, , . , , , . .
95% — 95% , . , 5%- , .
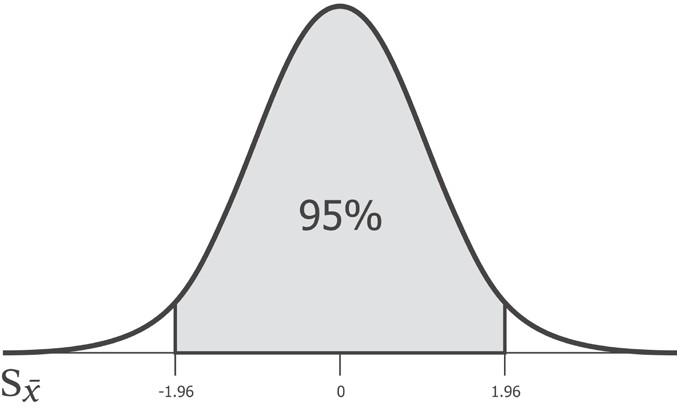
, 95% -1.96 1.96 . , , 1.96 95%- . z-.
z- , z-. , z- — .
1.96 , . , , scipy stats.norm.ppf
. confidence_interval
p 0 1. 95%- 0.95. 2 (2.5% 95%):
def confidence_interval(p, xs):
''' '''
mu = xs.mean()
se = standard_error(xs)
z_crit = stats.norm.ppf(1 - (1-p) / 2)
return [mu - z_crit * se, mu + z_crit * se]
def ex_2_9():
'''
'''
may_1 = '2015-05-01'
df = with_parsed_date( load_data('dwell-times.tsv') )
filtered = df.set_index( ['date'] )[may_1]
ci = confidence_interval(0.95, filtered['dwell-time'])
print(' : ', ci)
: [83.53415272762004, 97.753065317492741]
, 95% , 83.53 97.75 . , , , .
- AcmeContent - . , -. .
, , , , :
def ex_2_10():
''' ,
'''
ts = load_data('campaign-sample.tsv')['dwell-time']
print('n: ', ts.count())
print(': ', ts.mean())
print(': ', ts.median())
print(' : ', ts.std())
print(' : ', standard_error(ts))
ex_2_10()
n: 300
: 130.22
: 84.0
: 136.13370714388034
: 7.846572839994115
, , — 130 . 90 . , , 2 , , . , 95%- , confidence_interval, :
def ex_2_11():
''' ,
'''
ts = load_data('campaign-sample.tsv')['dwell-time']
print(' :', confidence_interval(0.95, ts))
: [114.84099983154137, 145.59900016845864]
95%- 114.8 145.6 . 90 . , - , . , .
, , , .
, , . , , , ( ) .
, « » (Literary Digest) 1936 . - : 2.4 . . — - . . 57% . , 62% .
. « » , . , , , , . — , . , .
, - . , . « » , , .
campaign_sample.tsv, , 6 2015 . , pandas:
''' '''
d = pd.to_datetime('2015 6 6')
d.weekday() in [5,6]
True
, . , , , — — , .
— :
def ex_2_12():
'''
, '''
df = load_data('dwell-times.tsv')
means = mean_dwell_times_by_date(df)['dwell-time']
means.hist(bins=20)
plt.xlabel(' , .')
plt.ylabel('')
plt.show()
:
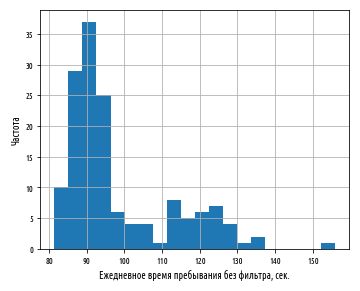
. , . , , .
. , , , , . , , .
. , . :
def ex_2_13():
''' ,
'''
df = with_parsed_date( load_data('dwell-times.tsv') )
df.index = df['date']
df = df[df['date'].index.dayofweek > 4] # -
weekend_times = df['dwell-time']
print('n: ', weekend_times.count())
print(': ', weekend_times.mean())
print(': ', weekend_times.median())
print(' : ', weekend_times.std())
print(' : ', standard_error(weekend_times))
n: 5860
: 117.78686006825939
: 81.0
: 120.65234077179436
: 1.5759770362547678
( 6- ) 117.8 . 95%- . , 130 . , , .
( - ), . , . , .
, №3.