
最近、Clangコンパイラのメインラインに優れた機能が 追加されました。
[[clang::musttail]]
または 属性を使用して
__attribute__((musttail))
、C、C ++、およびObjective-Cで保証された末尾呼び出しを取得できるようになりました。
int g(int);
int f(int x) {
__attribute__((musttail)) return g(x);
}
( オンラインコンパイラ)
通常、これらの呼び出しは関数型プログラミングに関連付けられていますが、パフォーマンスの観点からのみ関心があります。場合によっては、彼らの助けを借りて、アセンブラーに頼ることなく、少なくとも利用可能なコンパイル技術を使用して、コンパイラーからより良いコードを取得できます。
シリアル化プロトコルの解析にこのアプローチを使用すると、驚くべき結果が得られました 。2Gb/ sを超える速度で解析することができました。、以前の最良のソリューションの2倍以上の速さ。このスピードアップは多くの状況で役立つため、「末尾呼び出し==ダブルスピードアップ」というステートメントだけに限定するのは誤りです。ただし、これらの課題は、このような速度の向上を可能にした重要な要素です。
末尾呼び出しの利点は何か、それらを使用してプロトコルを解析する方法、およびこの手法をインタープリターに拡張する方法について説明します。そのおかげで、Cで書かれたすべての主要言語(Python、Ruby、PHP、Luaなど)のインタープリターは、パフォーマンスを大幅に向上させることができると思います。主な欠点は移植性に関連しています。今日、それ
musttail
は非標準のコンパイラ拡張です。私はそれがうまくいくことを願っていますが、拡張機能がシステム上のCコンパイラがそれをサポートするのに十分広く広がるまでには少し時間がかかります。構築時に、移植性が
musttail
利用できないことが判明した場合は、移植性と引き換えに効率を犠牲にすることが できます。
末尾呼び出しの基本
末尾呼び出しは、関数が結果を返す前の最後のアクションである、末尾位置にある任意の関数への呼び出しです。末尾呼び出しを最適化する場合、コンパイラは末尾呼び出しの命令をコンパイルしますが
jmp
、ではありません
call
。これは、新しいスタックフレームの作成や差出人住所の受け渡しなど
g()
、通常は呼び出し先が呼び出し元に戻る ことを可能にするオーバーヘッドアクションを実行しません
f()
。代わりに、
f()
直接指し
g()
、それ自体の一部であるかのように、および
g()
呼び出し元に直接結果を返します
f()
。スタックフレームがあるため、この最適化は安全です
f()
ローカル変数にアクセスできなくなったため、末尾呼び出しの開始後には不要になりました
f()
。
些細なことのように見えても、この最適化には、アルゴリズムを作成するための新しい可能性を開く2つの重要な機能があります。まず、n回の連続した末尾呼び出しを実行することにより、メモリスタックがO(n)からO(1)に削減されます。スタックが制限されており、オーバーフローによってプログラムがクラッシュする可能性があるため、これは重要です。したがって、この最適化がないと、一部のアルゴリズムは危険です。第二に、それ
jmp
はのオーバーヘッドを排除します
call
その結果、関数呼び出しは他のブランチと同じくらい効率的になります。これらの機能は両方とも、末尾呼び出しを
for
、やのような従来の反復制御構造の効率的な代替手段として使用できるように し
while
ます。
このアイデアはまったく新しいものではなく、1977年にGuy Steeleが論文全体を書き、
GOTO
末尾呼び出しを最適化しても速度が低下しない一方で、プロシージャ呼び出しはアーキテクチャよりもクリーンであると主張しました 。それは1975年から1980年の間に書かれた「ラムダワークス」の1つであり、 LispとSchemeの背後にある多くのアイデアを定式化しました。
末尾呼び出しの最適化は、Clangにとっても新しいことではありません。彼は、GCCや他の多くのコンパイラーのように、以前にそれらを最適化することができました。実際、
musttail
この例の属性 はコンパイラーの出力をまったく変更しません。Clangはすでに
-O2
。の末尾呼び出しを最適化しています 。
ここで新しいのは 保証です。コンパイラーは末尾呼び出しの最適化に成功することがよくありますが、これは「可能な限り最良の」ことであり、信頼することはできません。特に、最適化は、最適化されていないビルド(オンラインコンパイラ)では確実に機能しません 。この例では、末尾呼び出しはにコンパイルされている
call
ため、サイズO(n)のスタックに戻ります。これが私たちが必要な理由です
musttail
:末尾呼び出しが常にすべてのアセンブリモードで最適化されることがコンパイラから保証されるまで、その ような反復呼び出しを使用してアルゴリズムを作成することは安全ではありません。そして、最適化が有効になっている場合にのみ機能するコードに固執することは、かなり厳しい制約です。
インタプリタループの問題
コンパイラーは素晴らしいテクノロジーですが、完璧ではありません。LuaJITの作者であるMikePallは、LuaJIT 2.xインタープリターをCではなくアセンブリ言語で作成することを決定しました。彼は、これをインタープリターを非常に高速にした主な要因と呼びました 。Paulは後で、Cコンパイラがメインのインタプリタループを見つけるのに苦労する理由をより詳細に説明しました 。2つの主なポイント:
- , .
- , .
これらの観察結果は、シリアル化プロトコルの解析を最適化した経験をよく反映しています。そして末尾呼び出しは、両方の問題を解決するのに役立ちます。
インタプリタループをシリアル化プロトコルパーサーと比較するのは奇妙だと思うかもしれません。ただし、それらの予期しない類似性は、プロトコルのワイヤ形式の性質によって決定され ます。これは、キーにフィールド番号とそのタイプが含まれるキーと値のペアのセットです。キーはインタプリタのオペコードのように機能します。このフィールドを解析するために実行する必要のある操作を示します。プロトコルのフィールド番号は任意の順序にすることができるため、いつでもコードの任意の部分にジャンプする準備ができている必要があります。 ネストされた式
を持つループ
while
を 使用してそのようなパーサーを作成することは論理的です
switch
..。これは、プロトコルの存続期間にわたってシリアル化プロトコルを解析するための最良のアプローチでした。たとえば、現在のC ++バージョンの解析コードは次 のとおりです。制御フローをグラフィカルに表すと、次のスキームが得られます。
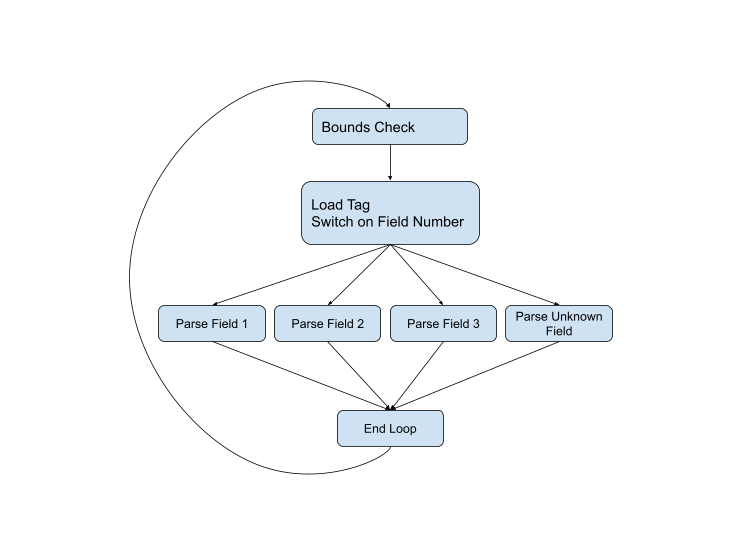
ただし、ほとんどすべての段階で問題が発生する可能性があるため、図は完全ではありません。フィールドタイプが間違っているか、データが破損しているか、現在のバッファの最後にジャンプしている可能性があります。完全な図は次のようになります。
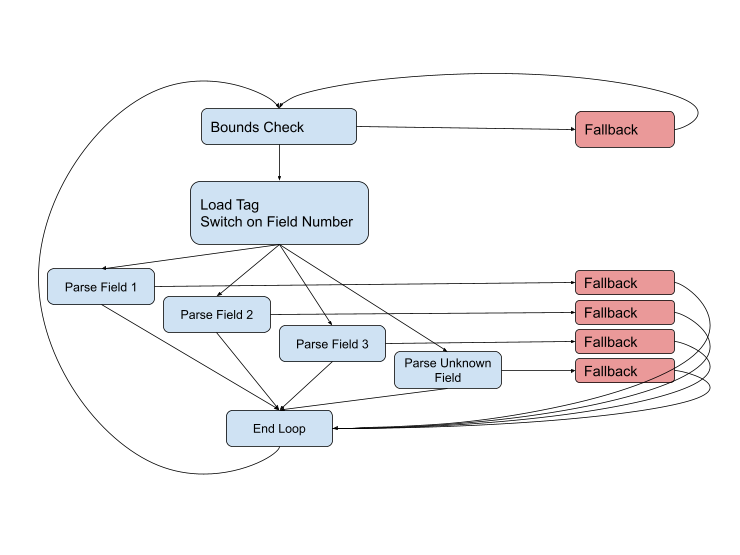
可能な限り高速パス(青)を維持する必要がありますが、困難な状況に直面した場合は、フォールバックコードを使用して処理する必要があります。このようなパスは通常、高速パスよりも長く複雑であり、より多くのデータを含み、さらに複雑なケースを処理するために他の関数への厄介な呼び出しを使用することがよくあります。
理論的には、このスキーマをプロファイルと組み合わせると、コンパイラーは最適なコードを生成するために必要なすべての情報を取得します。しかし実際には、このサイズの関数と接続の数では、コンパイラーと格闘しなければならないことがよくあります。レジスタに格納したい重要な変数をスローします。これは、フォールバック関数への呼び出しをラップアラウンドするスタックフレームの操作を適用します。これは、分岐予測のために別々に保持したい同一のコードパスを連結します。ミトンでピアノを弾こうとしているように見えます。
末尾呼び出しによるインタプリタループの改善
上記の推論は、主に通訳者の主なサイクルに関するパウロの観察の言い換えです 。しかし、アセンブラーに身を投じる代わりに、調整されたアーキテクチャーによって、Cからほぼ最適なコードを取得するために必要な制御が可能になることがわかりました。私は、ほとんどのアーキテクチャを考案した同僚のGerbenStavengaと一緒にこれに取り組みました。私たちのアプローチは、このパターンを「メタマシン」と呼ぶwasm3WebAssemblyインタープリターに似て い ます。 我々は 置く私達の2 -のコードをギガビットパーサ UPB
、Cの小さなprotobufライブラリ。これは完全に機能しており、シリアル化プロトコルに準拠するためのすべてのテストに合格していますが、まだどこにも展開されておらず、アーキテクチャはプロトコルのC ++バージョンに実装されていません。しかし、拡張機能がClangに導入されたとき
musttail
(そしてupbがそれを使用するように更新されたとき)、高速パーサーの完全な実装に対する主な障壁の1つがなくなり ました。
1つの大きな解析関数から離れて、各操作に独自の小さな関数を適用しました。各テール関数は、シーケンス内の次の操作を呼び出します。たとえば、これは固定サイズの単一フィールドを解析するための関数です(コードはupbに比べて単純化されているため、アーキテクチャの細部を多く削除しました)。
コード
#include <stdint.h>
#include <stddef.h>
#include <string.h>
typedef void *upb_msg;
struct upb_decstate;
typedef struct upb_decstate upb_decstate;
// The standard set of arguments passed to each parsing function.
// Thanks to x86-64 calling conventions, these will be passed in registers.
#define UPB_PARSE_PARAMS \
upb_decstate *d, const char *ptr, upb_msg *msg, intptr_t table, \
uint64_t hasbits, uint64_t data
#define UPB_PARSE_ARGS d, ptr, msg, table, hasbits, data
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
const char *fallback(UPB_PARSE_PARAMS);
const char *dispatch(UPB_PARSE_PARAMS);
// Code to parse a 4-byte fixed field that uses a 1-byte tag (field 1-15).
const char *upb_pf32_1bt(UPB_PARSE_PARAMS) {
// Decode "data", which contains information about this field.
uint8_t hasbit_index = data >> 24;
size_t ofs = data >> 48;
if (UNLIKELY(data & 0xff)) {
// Wire type mismatch (the dispatch function xor's the expected wire type
// with the actual wire type, so data & 0xff == 0 indicates a match).
MUSTTAIL return fallback(UPB_PARSE_ARGS);
}
ptr += 1; // Advance past tag.
// Store data to message.
hasbits |= 1ull << hasbit_index;
memcpy((char*)msg + ofs, ptr, 4);
ptr += 4; // Advance past data.
// Call dispatch function, which will read the next tag and branch to the
// correct field parser function.
MUSTTAIL return dispatch(UPB_PARSE_ARGS);
}
このような小さくて単純な関数の場合、Clangは、打ち負かすことはほとんど不可能なコードを生成します。
upb_pf32_1bt: # @upb_pf32_1bt
mov rax, r9
shr rax, 24
bts r8, rax
test r9b, r9b
jne .LBB0_1
mov r10, r9
shr r10, 48
mov eax, dword ptr [rsi + 1]
mov dword ptr [rdx + r10], eax
add rsi, 5
jmp dispatch # TAILCALL
.LBB0_1:
jmp fallback # TAILCALL
プロローグやエピローグ、レジスタのプリエンプション、スタックの使用はまったくないことに注意してください。唯一の出口は
jmp
2つの末尾呼び出しからのものですが、引数はすでに正しいレジスタにあるため、パラメータを渡すためのコードは必要ありません。おそらく、ここで見られる唯一の可能な改善
jne fallback
は
jne
、後続の呼び出しでは なく 、末尾呼び出しの条件付きジャンプです
jmp
。
シンボリック情報なしでこのコードの逆アセンブルを見た場合、これが関数全体であることに気付かないでしょう。同様に、より大きな関数の基本単位になる可能性もあります。そして、まさにそれが私たちの仕事です。大きくて複雑な関数であるインタープリターループを取得し、ブロックごとにプログラムして、末尾呼び出しを介してそれらの間で制御フローを渡します。各ブロック(少なくとも6つのレジスタ)の境界でのレジスタの分布を完全に制御できます。関数は十分に単純で、レジスタをプリエンプトしないため、最も重要な状態をすべての高速に保存するという目標を達成しました。パス。
命令の各シーケンスを個別に最適化できます。また、コンパイラはすべてのシーケンスを個別に処理します。これは、それらが別々の関数に配置されているためです(必要に応じて、でインライン化するのを防ぐことができます
noinline
)。これが、フォールバックパスからのコードが高速パスのコードの品質を低下させる上記の問題を解決する方法です。低速パスを完全に別個の機能に配置することにより、高速パスの速度安定性を保証できます。美しいアセンブラは変更されておらず、パーサーの他の部分の変更による影響を受けません。
このパターンをLuaJITのPaulの例に適用すると 、大まかに次のことができます。 彼の手書きのアセンブラーをコード品質の小さな低下と相関させます:
#define PARAMS unsigned RA, void *table, unsigned inst, \
int *op_p, double *consts, double *regs
#define ARGS RA, table, inst, op_p, consts, regs
typedef void (*op_func)(PARAMS);
void fallback(PARAMS);
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
void ADDVN(PARAMS) {
op_func *op_table = table;
unsigned RC = inst & 0xff;
unsigned RB = (inst >> 8) & 0xff;
unsigned type;
memcpy(&type, (char*)®s[RB] + 4, 4);
if (UNLIKELY(type > -13)) {
return fallback(ARGS);
}
regs[RA] += consts[RC];
inst = *op_p++;
unsigned op = inst & 0xff;
RA = (inst >> 8) & 0xff;
inst >>= 16;
MUSTTAIL return op_table[op](ARGS);
}
結果のアセンブラ:
ADDVN: # @ADDVN
movzx eax, dh
cmp dword ptr [r9 + 8*rax + 4], -12
jae .LBB0_1
movzx eax, dl
movsd xmm0, qword ptr [r8 + 8*rax] # xmm0 = mem[0],zero
mov eax, edi
addsd xmm0, qword ptr [r9 + 8*rax]
movsd qword ptr [r9 + 8*rax], xmm0
mov edx, dword ptr [rcx]
add rcx, 4
movzx eax, dl
movzx edi, dh
shr edx, 16
mov rax, qword ptr [rsi + 8*rax]
jmp rax # TAILCALL
.LBB0_1:
jmp fallback
上記以外にここで見た唯一の改善点は
jne fallback
、何らかの理由でコンパイラが生成したくないということ です。
jmp qword ptr [rsi + 8*rax]
代わりに、をロードし
rax
て実行し
jmp rax
ます。これらはマイナーなコーディングの問題であり、Clangがそれほど問題なくすぐに修正されることを願っています。
制限事項
このアプローチの主な欠点の1つは、これらの美しいアセンブリ言語シーケンスのすべてが、末尾呼び出しがない場合に壊滅的に悲観的になることです。調整されていない呼び出しは、スタックフレームを作成し、大量のデータをスタックにプッシュします。
#define PARAMS unsigned RA, void *table, unsigned inst, \
int *op_p, double *consts, double *regs
#define ARGS RA, table, inst, op_p, consts, regs
typedef void (*op_func)(PARAMS);
void fallback(PARAMS);
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
void ADDVN(PARAMS) {
op_func *op_table = table;
unsigned RC = inst & 0xff;
unsigned RB = (inst >> 8) & 0xff;
unsigned type;
memcpy(&type, (char*)®s[RB] + 4, 4);
if (UNLIKELY(type > -13)) {
// When we leave off "return", things get real bad.
fallback(ARGS);
}
regs[RA] += consts[RC];
inst = *op_p++;
unsigned op = inst & 0xff;
RA = (inst >> 8) & 0xff;
inst >>= 16;
MUSTTAIL return op_table[op](ARGS);
}
突然これを取得します
ADDVN: # @ADDVN
push rbp
push r15
push r14
push r13
push r12
push rbx
push rax
mov r15, r9
mov r14, r8
mov rbx, rcx
mov r12, rsi
mov ebp, edi
movzx eax, dh
cmp dword ptr [r9 + 8*rax + 4], -12
jae .LBB0_1
.LBB0_2:
movzx eax, dl
movsd xmm0, qword ptr [r14 + 8*rax] # xmm0 = mem[0],zero
mov eax, ebp
addsd xmm0, qword ptr [r15 + 8*rax]
movsd qword ptr [r15 + 8*rax], xmm0
mov edx, dword ptr [rbx]
add rbx, 4
movzx eax, dl
movzx edi, dh
shr edx, 16
mov rax, qword ptr [r12 + 8*rax]
mov rsi, r12
mov rcx, rbx
mov r8, r14
mov r9, r15
add rsp, 8
pop rbx
pop r12
pop r13
pop r14
pop r15
pop rbp
jmp rax # TAILCALL
.LBB0_1:
mov edi, ebp
mov rsi, r12
mov r13d, edx
mov rcx, rbx
mov r8, r14
mov r9, r15
call fallback
mov edx, r13d
jmp .LBB0_2
これを回避するために、インライン呼び出しまたは末尾呼び出しのみを介して他の関数を呼び出そうとしました。エラーではない異常な状況が発生する可能性のある場所が操作に多数ある場合、これは面倒な場合があります。たとえば、シリアル化プロトコルを解析する場合、整数変数は1バイトの長さであることがよくありますが、それより長いものはエラーではありません。このような状況の処理をインライン化すると、フォールバックコードが複雑すぎる場合、高速パスの品質が低下する可能性があります。ただし、フォールバック機能の末尾呼び出しでは、異常処理時に操作に戻りにくいため、フォールバック機能で操作を完了できる必要があります。これは、コードの重複と複雑化につながります。
理想的には、この問題は__attribute __((preserve_most))を追加することで解決できます。 末尾呼び出しではなく、通常の呼び出しが続くフォールバック関数で。この属性
preserve_most
により、呼び出し先はほとんどすべてのレジスターを保持する責任があります。これにより、必要に応じて、レジスタをプリエンプトするタスクをフォールバック関数に委任できます。この属性を試してみましたが、解決できない不思議な問題に遭遇しました。どこかで間違えたのかもしれませんが、将来はこれに戻ります。
主な制限は、
musttail
それがポータブルではないという ことです。この属性がルートになり、GCC、Visual C ++、その他のコンパイラーに実装され、いつの日か標準化されることを心から願っています。しかし、これはすぐには起こりませんが、私たちは今何をすべきでしょうか?
拡張時
musttail
が使用できない場合は、ループの理論上の反復ごとに
return
末尾呼び出しなしで少なくとも1つの正しいものを実行する必要があります 。upbライブラリにはまだそのようなフォールバックを実装していませんが、可用性に応じて
musttail
末尾呼び出しを行うか、単に戻るマクロになると思います 。