前書き
私の主な仕事はモバイル広告であり、時々モバイルアプリケーションに関するデータを処理する必要があります。モデルの構築を練習したい人や、オープンソースから収集できるデータのアイデアを得たい人のために、いくつかのデータを公開することにしました。オープンデータセットは常にコミュニティに役立つと思います。多くの場合、データの収集は困難で退屈な作業であり、誰もがそれを行う機会があるわけではありません。この記事では、データセットを紹介し、それを使用して1つのモデルを構築します。
データ
データセットはKaggleのWebサイトで公開されています。
DOI: 10.34740/KAGGLE/DSV/2107675.
293,392個のアプリケーション(最も人気のあるもの)の場合、元の説明を含む説明トークンとアプリケーションデータ自体が収集されます。データセットにアプリケーション名はありません。それらは一意の識別子によって識別されます。トークン化の前に、ほとんどの説明は英語に翻訳されていました。
データセットには4つのファイルがあります。
bundles_desc.csv-説明のみが含まれます。
bundles_desc_tokens.csv- トークンとジャンルが含まれています。
bundles_prop.csv、bundles_summary.csv- さまざまなアプリケーションの特性とリリース/更新日が含まれています。
EDA
まず、オペレーティングシステム間でデータがどのように分散されているかを見てみましょう。

Androidアプリがデータを支配します。これは、より多くのAndroidアプリが作成されているという事実が原因である可能性があります。
, , , .
histnorm ='probability' # type of normalization

, .

2021 .

- .
df['bundle_update_period'] = \
(pd.to_datetime(
df['bundle_updated_at'], utc=True).dt.tz_convert(None).dt.to_period('M').astype('int') -
df['bundle_released_at'].dt.to_period('M').astype('int'))

, . , .
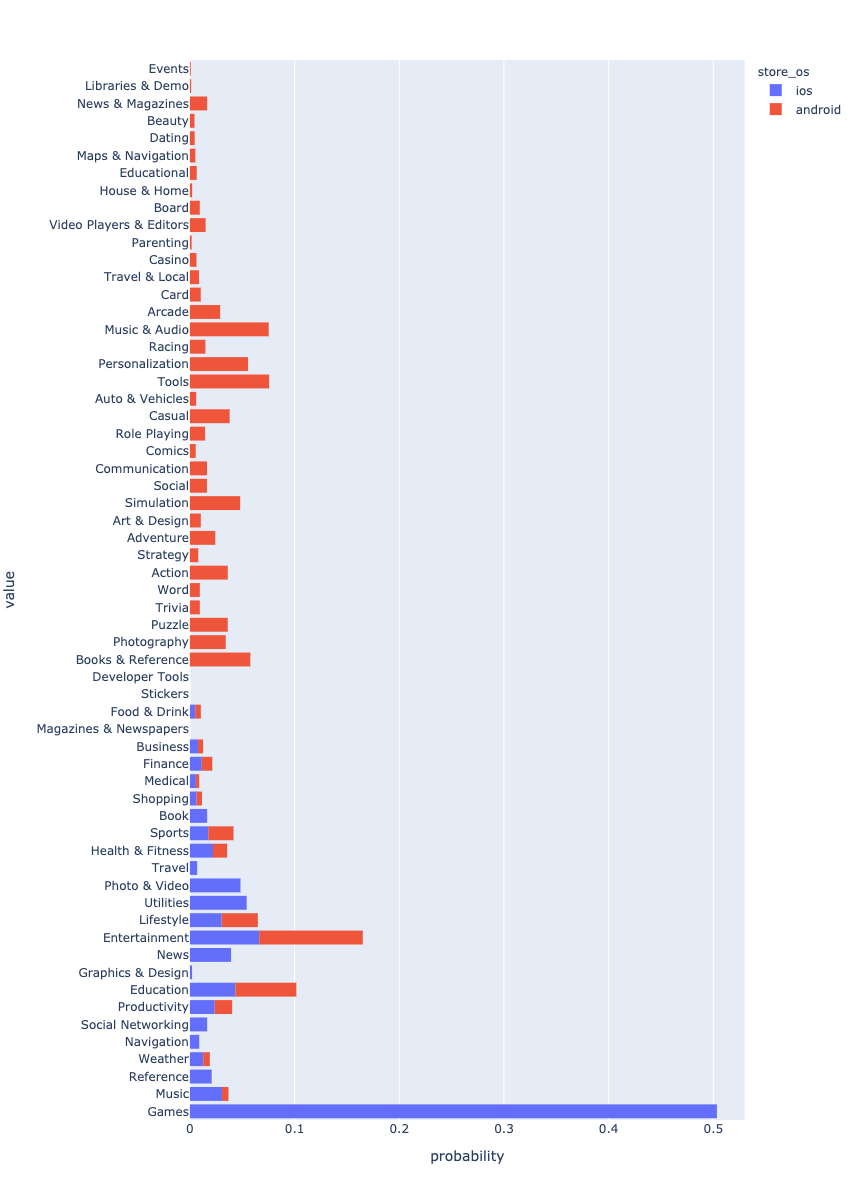
, . . . ? - Android , iOS Games. , , . . , .
, .
def get_lengths(df, columns=['tokens', 'description']):
lengths_df = pd.DataFrame()
for i, c in enumerate(columns):
lengths_df[f"{c}_len"] = df[c].apply(len)
if i > 0:
lengths_df[f"{c}_div"] = \
lengths_df.iloc[:, i-1] / lengths_df.iloc[:, i]
lengths_df[f"{c}_diff"] = \
lengths_df.iloc[:, i-1] - lengths_df.iloc[:, i]
return lengths_df
df = pd.concat([df, get_lengths(df)], axis=1, sort=False, copy=False)
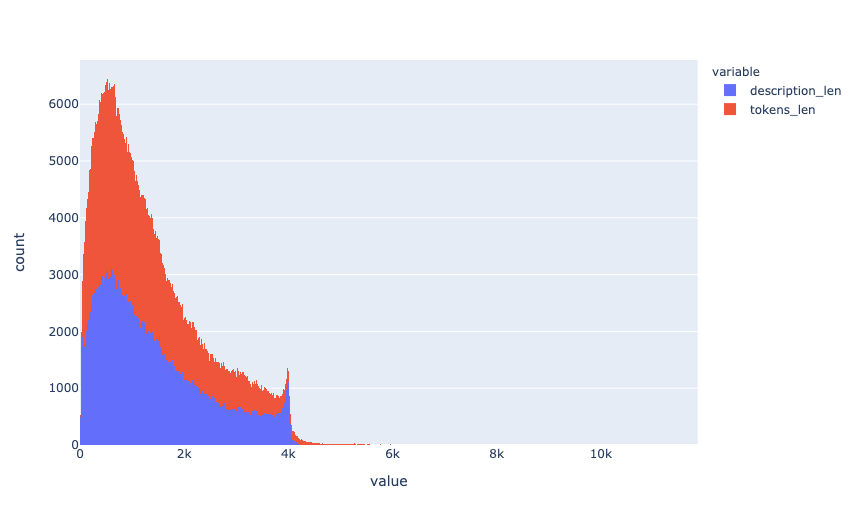
, . , - .

Android-.
android_df = df[df['store_os']=='android']
ios_df = df[df['store_os']=='ios']
:
columns = [
'genre', 'tokens', 'bundle_update_period', 'tokens_len',
'description_len', 'description_div', 'description_diff',
'description', 'rating', 'reviews', 'score',
'released_at_month'
]
- train validation. , .
train_df, test_df = train_test_split(
android_df[columns], train_size=0.7, random_state=0, stratify=android_df['genre'])
y_train, X_train = train_df['genre'], train_df.drop(['genre'], axis=1)
y_test, X_test = test_df['genre'], test_df.drop(['genre'], axis=1)
CatBoost. CatBoost - . , CatBoost . 0.19.1
: BERT vs CatBoost , CatBoost BERT.
!pip install -U catboost
CatBoost Pool. , , . , .
train_pool = Pool(
data=X_train,
label=y_train,
text_features=['tokens', 'description']
)
test_pool = Pool(
data=X_test,
label=y_test,
text_features=['tokens', 'description']
)
. ; .
def fit_model(train_pool, test_pool, **kwargs):
model = CatBoostClassifier(
random_seed=0,
task_type='GPU',
iterations=10000,
learning_rate=0.1,
eval_metric='Accuracy',
od_type='Iter',
od_wait=500,
**kwargs
)
return model.fit(
train_pool,
eval_set=test_pool,
verbose=1000,
plot=True,
use_best_model=True
)
. CatBoost, .
CatBoostClassifier :
tokenizers — ;
dictionaries — ;
feature_calcers — ;
text_processing — JSON- , , , .
, , , , .
tpo = {
'tokenizers': [
{
'tokenizer_id': 'Sense',
'separator_type': 'BySense',
}
],
'dictionaries': [
{
'dictionary_id': 'Word',
'token_level_type': 'Word',
'occurrence_lower_bound': '10'
},
{
'dictionary_id': 'Bigram',
'token_level_type': 'Word',
'gram_order': '2',
'occurrence_lower_bound': '10'
},
{
'dictionary_id': 'Trigram',
'token_level_type': 'Word',
'gram_order': '3',
'occurrence_lower_bound': '10'
},
],
'feature_processing': {
'0': [
{
'tokenizers_names': ['Sense'],
'dictionaries_names': ['Word'],
'feature_calcers': ['BoW']
},
{
'tokenizers_names': ['Sense'],
'dictionaries_names': ['Bigram', 'Trigram'],
'feature_calcers': ['BoW']
},
],
'1': [
{
'tokenizers_names': ['Sense'],
'dictionaries_names': ['Word'],
'feature_calcers': ['BoW', 'BM25']
},
{
'tokenizers_names': ['Sense'],
'dictionaries_names': ['Bigram', 'Trigram'],
'feature_calcers': ['BoW']
},
]
}
}
:
model_catboost = fit_model( train_pool, test_pool, text_processing = tpo )


bestTest = 0.6454657601
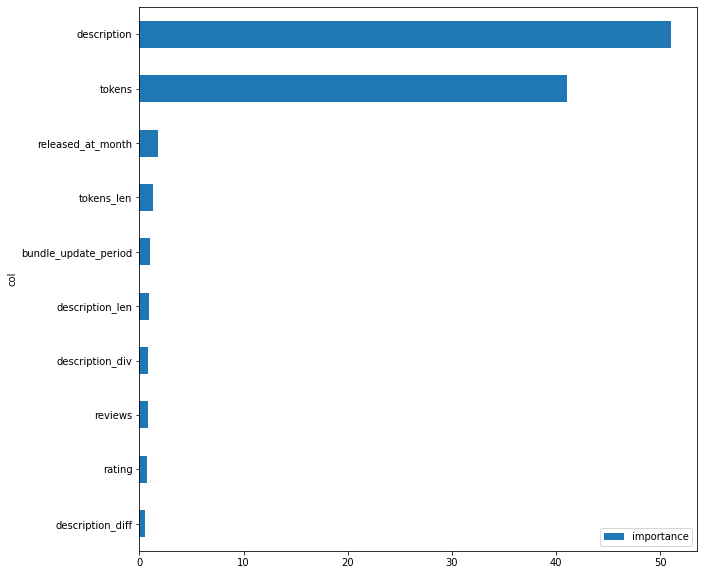
. , summary, , iOS, . , . .
, . , , . , . , .
, , OOF (Out-of-Fold). ; .
def get_oof(n_folds, x_train, y, x_test, text_features, seeds):
ntrain = x_train.shape[0]
ntest = x_test.shape[0]
oof_train = np.zeros((len(seeds), ntrain, 48))
oof_test = np.zeros((ntest, 48))
oof_test_skf = np.empty((len(seeds), n_folds, ntest, 48))
test_pool = Pool(data=x_test, text_features=text_features)
models = {}
for iseed, seed in enumerate(seeds):
kf = StratifiedKFold(
n_splits=n_folds,
shuffle=True,
random_state=seed)
for i, (tr_i, t_i) in enumerate(kf.split(x_train, y)):
print(f'\nSeed {seed}, Fold {i}')
x_tr = x_train.iloc[tr_i, :]
y_tr = y[tr_i]
x_te = x_train.iloc[t_i, :]
y_te = y[t_i]
train_pool = Pool(
data=x_tr, label=y_tr, text_features=text_features)
valid_pool = Pool(
data=x_te, label=y_te, text_features=text_features)
model = fit_model(
train_pool, valid_pool,
random_seed=seed,
text_processing = tpo
)
x_te_pool = Pool(
data=x_te, text_features=text_features)
oof_train[iseed, t_i, :] = \
model.predict_proba(x_te_pool)
oof_test_skf[iseed, i, :, :] = \
model.predict_proba(test_pool)
models[(seed, i)] = model
oof_test[:, :] = oof_test_skf.mean(axis=1).mean(axis=0)
oof_train = oof_train.mean(axis=0)
return oof_train, oof_test, models
, :
oof_train — OOF- Android
oof_test — OOF- iOS
models — all OOF-
from sklearn.metrics import accuracy_score
accuracy_score(
android_df['genre'].values,
np.take(models[(0,0)].classes_, oof_train.argmax(axis=1)))
.
OOF accuracy: 0.6560790777135628
android_genre_vec, oof_train Android oof_test iOS.
idx = df[df['store_os']=='ios'].index
df.loc[df['store_os']=='ios', 'android_genre_vec'] = \
pd.Series(list(oof_test), index=idx)
idx = df[df['store_os']=='android'].index
df.loc[df['store_os']=='android', 'android_genre_vec'] = \
pd.Series(list(oof_train), index=idx)
android_genre, .
df.loc[df['store_os']=='ios', 'android_genre'] = \
np.take(models[(0,0)].classes_, oof_test.argmax(axis=1))
df.loc[df['store_os']=='android', 'android_genre'] = \
np.take(models[(0,0)].classes_, oof_train.argmax(axis=1))
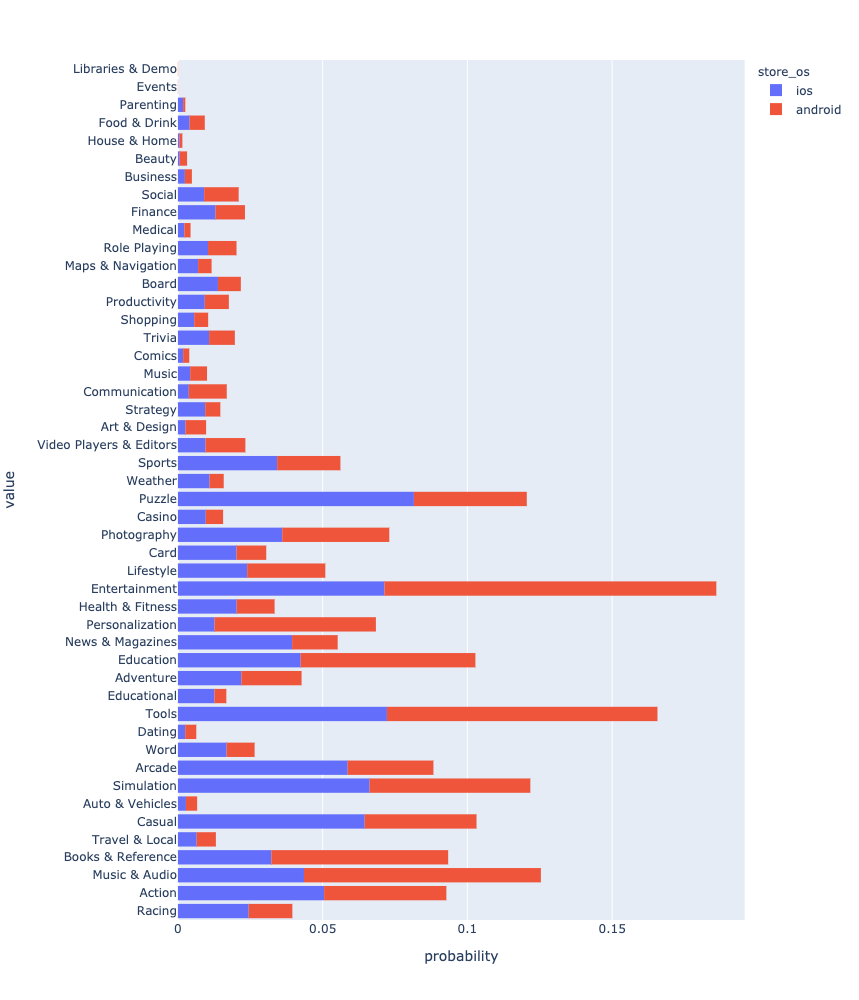
すべての操作が完了すると、最終的に、ジャンルごとのアプリケーションの分布を確認して比較できます。
結果
記事の中で:
新しい無料のデータセットが導入されました。
小さなEDAを作成しました。
いくつかの新機能が作成されました。
説明からアプリケーションのジャンルを予測するためのモデルが作成されました。
このデータセットがコミュニティに役立ち、モデルと今後の研究の両方で使用されることを願っています。可能な限り更新していきます。