
!
, Head of AI Celsus. .
, , ML- . «» — , , .
ML- DS-, , CV .
したがって、乳がん(ちなみに、女性の間で最も一般的なタイプの腫瘍学)を検出するためのAIスタートアップを見つけ、マンモグラフィ検査で病理の兆候を正確に検出するシステムを作成するとします。エラーに対する医師、そして診断を下す時間を短縮する...明るい使命ですね。

あなたは才能のあるプログラマー、MLエンジニア、アナリストのチームを編成し、高価な機器を購入し、オフィスを借りて、マーケティング戦略を考えました。すべてが世界をより良く変え始める準備ができているようです!残念ながら、最も重要なこと、つまりデータについて忘れてしまったため、すべてがそれほど単純ではありません。それらがなければ、ニューラルネットワークやその他の機械学習モデルをトレーニングすることはできません。
ここに、主な障害の1つ、つまり利用可能なデータセットの量と質があります。残念ながら、診断医学の分野では、高品質で検証済みの完全なデータセットはまだ非常に少なく、研究者やAI企業が公開しているデータセットはさらに少なくなっています。
乳がんの検出の同じ例を使用して状況を考えてみましょう。多かれ少なかれ高品質の公開データセットを片手で数えることができます: DDSM(約2600ケース)、 InBreast(115)、 MIAS(161)。アクセスを取得するためのかなり複雑で紛らわしい手順を持つOPTIMAMと BCDRもあり ます。
そして、十分な量の公開データを収集できたとしても、次の障害があなたを待っています。これらのデータセットのほとんどすべては、非営利目的でのみ使用することが許可されています。さらに、それらのマークアップは完全に異なる可能性があります-そしてそれがあなたのタスクに適しているという事実ではありません。一般に、独自のデータセットとそのマークアップを収集しなくても、MVPのみを作成できますが、高品質の製品を作成して、戦闘条件での運用に備えることはできません。
それで、あなたは医療機関にリクエストを送り、あなたのすべてのつながりと連絡先を上げ、そしてあなたの手にある様々な写真の雑多なコレクションを受け取りました。事前に喜んではいけません、あなたは道の最初にいます!確かに、医用画像を保存するための統一された標準の存在にもかかわらず、 DICOM(医学におけるデジタルイメージングと通信)、実際の生活ではすべてがそれほどバラ色ではありません。たとえば、乳房画像の側面(左/右)と投影( CC / MLO)に関する情報は、まったく異なるフィールドの異なるデータソースに保存できます。ここでの唯一の解決策は、できるだけ多くのソースからデータを収集し、サービスのロジックで考えられるすべてのオプションを考慮に入れることです。
あなたがマークアップするのはあなたが刈り取るものです
ついに楽しい部分、つまりデータマークアッププロセスにたどり着きました。医療分野でこれほど特別で忘れられない理由は何ですか?まず、マーキング自体のプロセスは、ほとんどの業界よりもはるかに複雑で時間がかかります。 X線をYandex.Tolokaにアップロードすることはできず 、ペニーのタグ付きデータセットを取得できます。これには、医療専門家の骨の折れる作業が必要であり、複数の医師にマーキングするために各画像を提供することをお勧めします-これは費用と時間がかかります。
さらに悪いことに、専門家はしばしば意見が一致せず、出力で同じ画像にまったく異なるマーキングを付けます。医師はさまざまな資格、教育、「疑惑」のレベルを持っています。誰かが画像内のすべてのオブジェクトを輪郭に沿ってきちんとマークし、誰かが幅の広いフレームでマークします。最後に、そのうちの1つはエネルギーと熱意に満ちており、もう1つは20時間のシフト後に小さなノートパソコンの画面に写真をマークアップしています。これらすべての不一致は当然「狂気のドライブ」ニューラルネットワークであり、そのような条件下では高品質のモデルを取得できません。
エラーと不一致のほとんどが最も複雑なケースで正確に発生し、ニューロンのトレーニングに最も価値があるという事実によっても、状況は改善されません。たとえば、 研究乳房組織の密度が高いマンモグラムで診断を行う際に医師が犯す間違いのほとんどが示されているため、AIシステムでも最も困難であることは驚くべきことではありません。
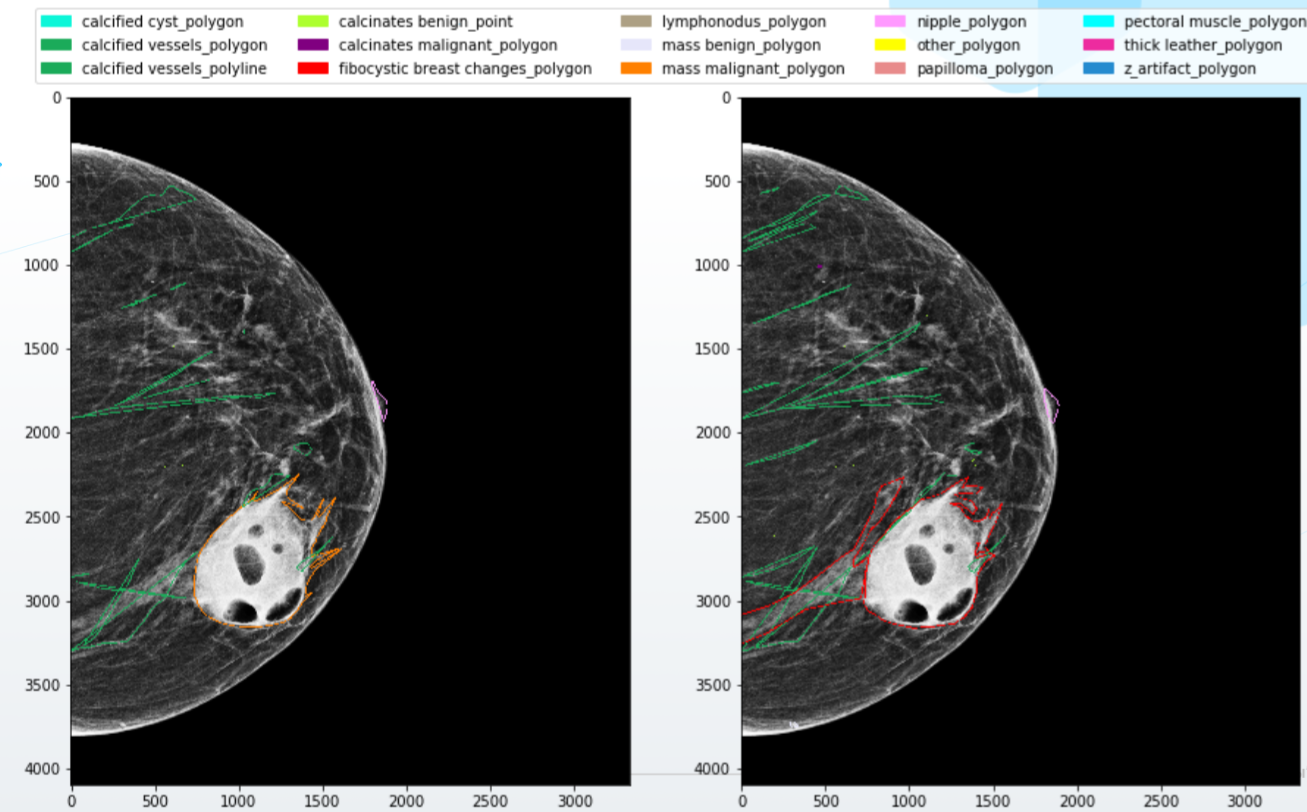
何をすべきか?もちろん、まず第一に、医師との高品質な相互作用システムを構築する必要があります。例と視覚化を使用してマークアップの詳細なルールを記述し、スペシャリストに高品質のソフトウェアと機器を提供し、マークアップでマイナーな競合を組み合わせるためのロジックを書き留め、より深刻な競合の場合は追加の意見を求めます。
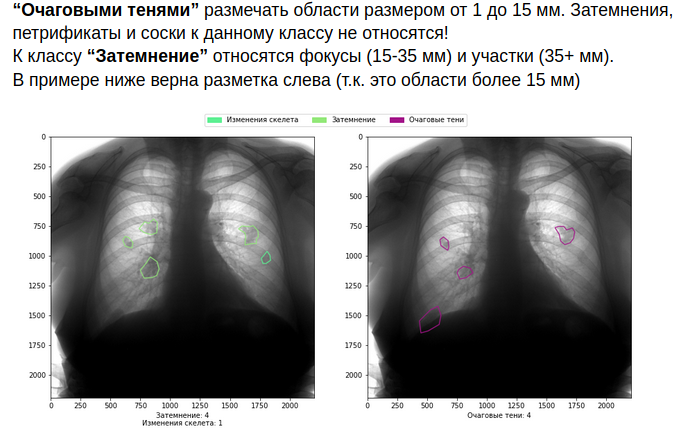
ご想像のとおり、これはすべてマークアップのコストを増加させます。しかし、自分でそれらを受け入れる準備ができていない場合は、医学の分野に入らない方が良いです。
もちろん、プロセスに賢明にアプローチすれば、コストを削減することができ、削減する必要があります。たとえば、アクティブラーニングを通じてです。この場合、MLシステム自体が、病理認識の品質を最大化するために、どの画像に追加のマークを付ける必要があるかを医師に促します。モデルの予測における信頼度を評価するには、さまざまな方法があります。学習損失、識別的能動学習、MCドロップアウト、予測確率のエントロピー、信頼度ブランチなどです。どちらを使用するのが良いか、モデルとデータセットでの実験のみが表示されます。
最後に、医師のマークアップを完全に放棄し、最終的な確認済みの結果(たとえば、患者の死亡や回復)のみに依存することができます。おそらくこれが最善のアプローチです(ここには多くのニュアンスがありますが)が、本格的なPACS(画像アーカイブおよび通信システム)と医療情報システム(MIS )そして十分なデータが蓄積されたとき。しかし、この場合でも、このデータの純度と品質を保証する人は誰もいません。
良いモデル-良い前処理

やったー!モデルはトレーニングされ、優れた結果を示し、パイロットの準備ができています。いくつかの医療機関と協力協定を結び、システムを設置して構成し、医師にデモンストレーションを行い、システムの機能を示しました。
そして、システム操作の初日が終わったので、心が沈むメトリックでダッシュボードを開きます...そして次の図が表示されます:システムによって検出されたオブジェクトがゼロのシステムへの一連のリクエストと、もちろん、医師からの否定的な反応。どうして?結局のところ、システムは内部テストで優れていることが証明されました!
さらに分析すると、この医療機関には、自分の設定に馴染みのないX線装置があり、その結果、画像がまったく異なって見えることがわかりました。ニューラルネットワークはそのような画像で訓練されていなかったので、それらで「失敗」し、何も検出しないことは驚くべきことではありません。機械学習の世界では、このようなケースは一般に配布外データと呼ばれます。モデルは通常、そのようなデータで大幅にパフォーマンスが低下します。これは、機械学習の主な問題の1つです。
実例:私たちのチームは公開モデルをテストしました ニューヨーク大学の研究者から、100万枚の画像で訓練を受けました。この記事の著者は、このモデルがマンモグラムで腫瘍学の高品質な検出を示したと主張しており、具体的には、0.88〜0.89の領域でのROC-AUC精度について述べています。私たちのデータでは、同じモデルが著しく悪い結果を示しています-データセットに応じて0.65から0.70まで。
表面上のこの問題の最も簡単な解決策は、すべてのデバイスから、すべての設定で、考えられるすべてのタイプの画像を収集し、それらをマークアップして、システムをトレーニングすることです。マイナス?繰り返しますが、長くて高価です。場合によっては、マークアップなしで実行できます。教師なし学習が役に立ちます。ラベルのない画像は特定の方法でニューロンに与えられ、モデルはその特徴に「慣れ」ます。これにより、将来、同様の画像内のオブジェクトを正常に検出できます。これは、たとえば、タグなし画像の疑似マークアップまたはさまざまな補助タスクを使用して実行できます。
しかし、これも万能薬ではありません。また、この方法では、世界に存在するあらゆる種類の画像を収集する必要があり、原則として不可能と思われます。そして、ここでの最善の解決策は、ユニバーサル前処理を使用することです。
前処理は、入力データをニューラルネットワークに供給する前に処理するためのアルゴリズムです。この手順には、コントラストと明るさの自動変更、さまざまな統計的正規化、および画像の不要な部分(アーティファクト)の削除が含まれます。
たとえば、多くの実験の後、私たちのチームは乳腺のX線画像のユニバーサル前処理を作成しました。これにより、ほとんどすべての入力画像が均一な形になり、ニューラルネットワークで正しく処理できるようになります。

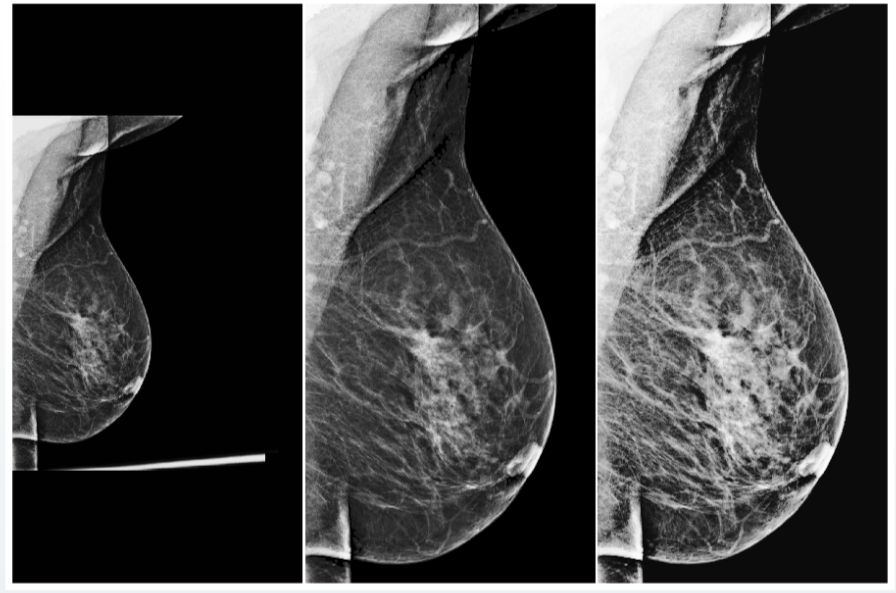
ただし、ユニバーサル前処理を使用する場合でも、入力データの品質チェックを忘れないでください。たとえば、蛍光写真のデータセットでは、バッグ、ボトル、その他のオブジェクトを含むテスト画像に出くわすことがよくありました。システムがそのような画像に病理が存在する確率を割り当てた場合、これは明らかにモデルに対する医学界の信頼を高めるものではありません。このような問題を回避するために、AIシステムは、正しい予測と入力データの有効性に対する信頼を示す必要もあります。

AIシステムが新しいデータを一般化し、一般化し、操作する機能の問題は、ハードウェアの違いだけではありません。非常に重要なパラメータは、データセットの人口統計学的特性です。たとえば、トレーニングサンプルが60歳以上のロシア人によって支配されている場合、モデルが若いアジア人で正しく機能することを誰も保証できません。トレーニングサンプルの統計的指標と、システムが使用される実際の母集団の類似性を監視することが不可欠です。
不一致が見つかった場合は、テストを実施することが不可欠であり、ほとんどの場合、モデルの追加のトレーニングまたは微調整を行う必要があります。システムの継続的な監視と定期的な改訂を実施することが不可欠です。現実の世界では、何百万ものことが起こる可能性があります。X線装置が交換され、別の方法で研究を行う新しい実験助手がやって来て、他国からの移民の群衆が突然街に殺到しました。これはすべて、AIシステムの品質の低下につながる可能性があります。
ただし、ご想像のとおり、学習がすべてではありません。システムは最低限評価する必要があり、標準的な測定基準は医療分野に適用できない場合があります。これにより、競合するAIサービスの評価も困難になります。しかし、これは、私たちの個人的な経験に基づいて、いつものように、資料の2番目の部分のトピックです。