
私の名前はサーシャです。SberDevicesでは、音声認識と、データによって音声認識を改善する方法に取り組んでいます。この記事では、オーディオファイルと対応する文字起こしで構成される新しいGolos音声データセットについて説明します。録音の合計時間は約1240時間で、サンプリングレートは16kHzです。現時点では、これはロシア語で最大のオーディオ録音のコーパスであり、手作業でマークされています。CC Attribution ShareAlikeに近いライセンスの下でコーパスをリリースしました 。これにより、科学研究と商業目的の両方に使用できるようになります。データセットが何で構成されているか、どのように組み立てられたか、どのような結果が得られるかについて説明します。
Golosデータセット構造
データセットを作成するとき、実際のユーザーからのデータがまだ利用できないときに、コールドスタートの問題を解決したいという願望に導かれました。実際のユーザーのスピーチがそこにないので、これは最終的にそれを公に利用可能にすることを可能にしたものです。
データセット内のオーディオ録音は、2つのソースから収集されます。最初のソースはクラウドソーシングプラットフォームであるため、クラウドドメインと呼びます。 2番目のソースは、SberPortalターゲットデバイスを使用してスタジオで作成された録音です。それは特別なマイクシステムを持っており、これは私たちの音声認識が機能するはずのデバイスの1つです。
ユーザーからデバイスまでの距離は通常非常に大きいため、このソースをファーフィールドドメインと呼びます。スタジオでSberPortalを介して録音するために、ユーザーからデバイスまでの1、3、5メートルの3つの距離を使用しました。各ドメインにはトレーニングとテストの部分があり、結果の構造を次の表に示します。
| ドメイン | トレーニングパート | テストパーツ |
|---|---|---|
| 群集 | 979796ファイル| 1095時間 | 9994ファイル| 11.2時間 |
| ファーフィールド | 124003ファイル| 132.4時間 | 1916ファイル| 1.4時間 |
| 合計 | 1 103799ファイル| 1227.4時間 | 11910ファイル| 12.6時間 |
データセットには、年齢、性別、ユーザーIDなどの個人情報はありません。すべてが非個人的です。トレーニングパートとテストパートには、同じユーザーのスピーチが含まれている場合があります。
| 統計\ドメイン | 群集 | ファーフィールド |
|---|---|---|
| 数 | 979796ファイル | 124003ファイル |
| 平均 | 4.0秒 | 3.8秒 |
| 標準偏差 | 1.9秒 | 1.6秒 |
| 1パーセンタイル | 1.4秒 | 2.0秒 |
| 50パーセンタイル | 3.7秒 | 3.5秒 |
| 95パーセンタイル | 7.3秒 | 6.8秒 |
| 99パーセンタイル | 10.5秒 | 9.6秒 |
上記の表は、エントリに関する統計情報(平均、標準偏差、パーセンタイル)を示しています。わかりやすくするために、この図はレコード長の分布の2つのヒストグラムを示しています。
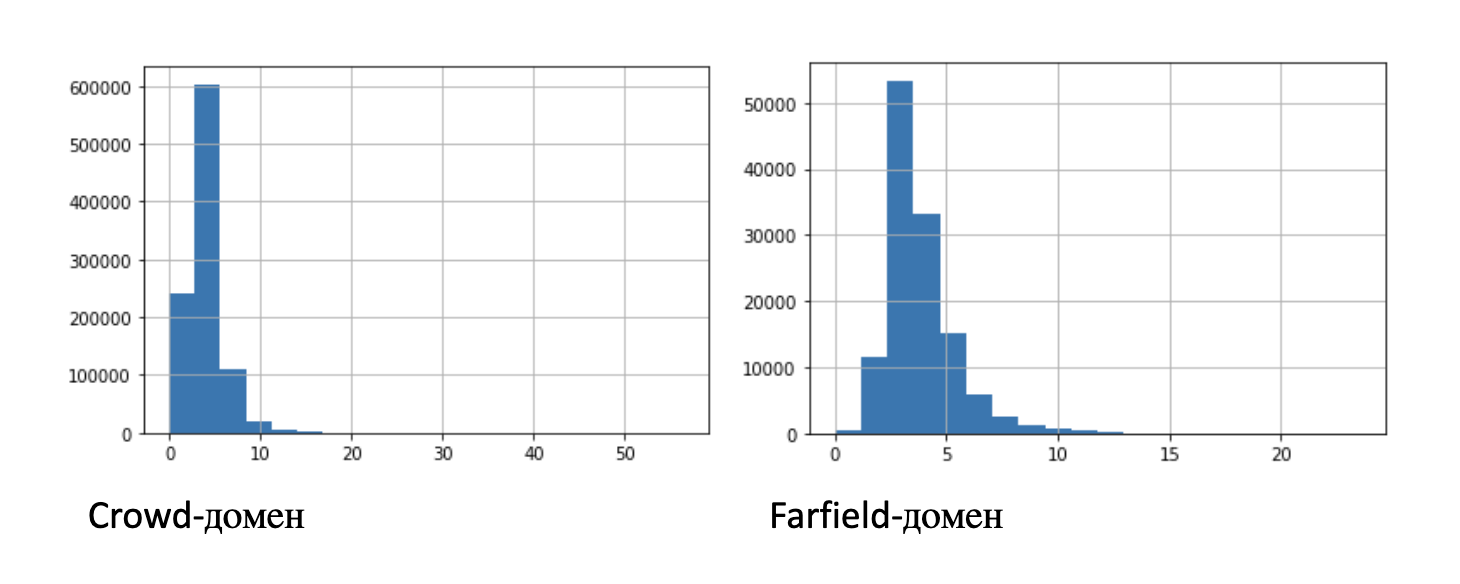
限られた数のレコードを使用した実験では、100時間、10時間、1時間、10分という短い長さのサブセットを特定しました。
データ収集
SberDevicesでは、仮想アシスタントのSaluteファミリーを開発しているため、アシスタントに対するユーザーの要求に似た音声を生成しました。音楽、映画、商品の注文など、さまざまなドメインのリクエストを記述するためのテンプレートシステムを作成しました。これらは、リクエストの構造を記述し、それをコンポーネントに分解する式です。テンプレートを使用すると、妥当なクエリを生成したり、音響モデルを再トレーニングしたり、これらのクエリに基づいて言語モデルを作成したりすることができます。
サンプルテンプレート:
| テンプレート | 例 |
|---|---|
| [command_demands_vp] + [film_syn_vp] + [film_title_ip] | 映画のグリーンブックを再生する |
| [command_demands_ip] + [film_syn_ip] + [film_title_ip] | あなたは映画のグリーンブックを持っています |
| [command_demands_ip] + [film_title_ip] | グリーンブックはありますか |
| [film_title_ip] + [command_demands_vp] | グリーンブックを置く |
| [film_syn_ip] + [film_title_ip] + [command_demands_vp] | グリーンブックを撮影する |
| [film_title_ip] | グリーンブック |
| [command_demands_vp] + [film_title_ip] | グリーンブックをオンにする |
| [film_syn_ip] + [film_title_ip] | フィルムグリーンブック |
| [command_demands_vp] + [film_title_ip] | グリーンブックをオンにする |
| ..。 | ..。 |
角括弧内-対応するエンティティの指定。さらに、2つのエンティティ「film_title_ip」と「film_title_vp」の表には、次のように入力するための可能なオプションがあります。
| film_title_ip | film_title_vp |
|---|---|
| 執着 | 執着 |
| 脱出 | 脱出 |
| 美女と野獣 | 美女と野獣 |
| 島 | 島 |
| ジェーン・エア | ジェーン・エア |
| Wuthering Heights | Wuthering Heights |
| ..。 | ..。 |
タグ付きオーディオデータセットを作成するプロセスは、いくつかの段階で構成されています。
- ステップ1.まず、特定のドメインのテンプレートを作成します。
- 2. - . , :
- 3. «» :
- 4. – , , . – . 80% Golos. , “”, , . , , .
- 4*. - , , , , , , . , . , , , , , . , .

- 5*. , . , . , , , . , , , . , , , . , . :

:
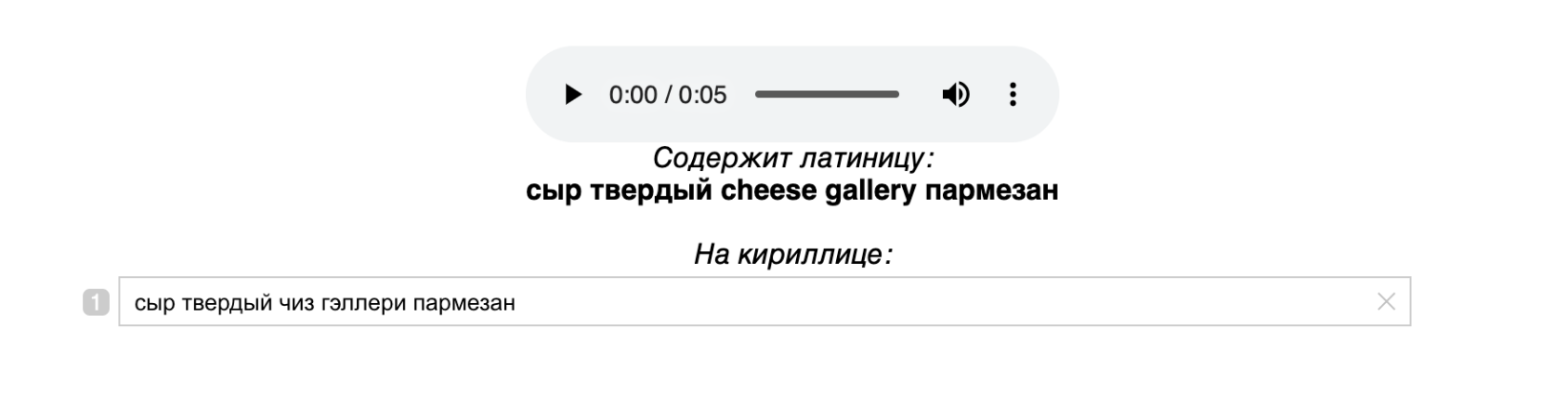
, . .
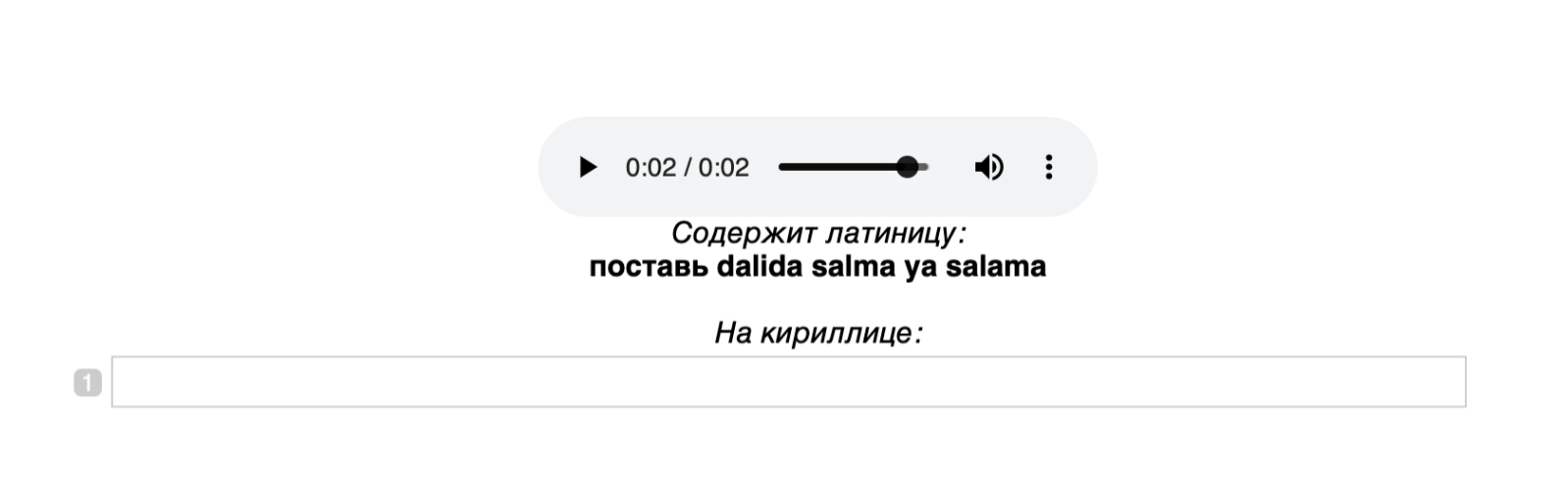
, , , .
- 5 . 3 , .
. -, , . -, . , .
, , “” – , “” - . , , , ( ) . bias , , . , . , .
説明されているデータセット作成プロセスにより、マークアップを可能な限り高品質にすることができます。これにより、自動または半自動で作成された他のマークアップと区別されます。このデータを使用して、デバイスに音声認識システムを作成します。マーキングの品質が高いため、結果として得られるシステムの精度は人間の精度に匹敵します。すべてのデータは、音声認識用のトレーニング済みの音響モデルと言語モデルとともに、プロジェクトのGitHubページと、 機械学習モデルをトレーニングするためのサービスであるSbercloudのML Spaceで利用できます。この サービスでは、データセットをインターフェースからシームレスにダウンロードできます。 。次の記事では、ML Spaceの使用方法と、それを使用して音声認識モデルを教える方法について詳しく説明します。
現在、英語のオープンデータはたくさんありますが、そのような高品質のロシア語データセットはありませんでした。現在、コーパスはロシア語でも利用可能であり、音声認識と合成に使用でき、それらでトレーニングされたモデルは非常に高品質を示しています。Golosデータセットにより、ロシアの科学コミュニティはロシア語の音声技術の改善をさらに迅速に進めることができると確信しています。