
自然は悪天候ではなく、すべての天気は恵みです。この歌詞の歌詞は、天気を人々の関係として解釈することで比喩的に理解できます。文字通り理解できますが、それもまた事実です。なぜなら、雪の降る寒い冬はなく、私たちは夏をそれほど重視しませんし、その逆も同様です。しかし、無人車両には、叙情的な感情や詩的な見通しが欠けています。なぜなら、それらの無人車両は、すべての天候、特に冬が優雅なわけではないからです。 「ロボット車両」の開発者が直面する主な問題の 1 つは、悪天候時に車に行き先を知らせるセンサーの精度の低下です。ミシガン工科大学の科学者は、無人車両の「目を通して」道路の気象条件のデータベースを作成しました。このデータは、吹雪中のロボット車両の視界が悪化しないように、何を変更または改善する必要があるかを理解するために必要でした。晴れた夏の日よりも。天候が無人機のセンサーにどの程度影響するか、科学者はこの問題を解決するためにどのような方法を提案し、どの程度効果的でしょうか?これらの質問に対する答えは、科学者の報告書に記載されています。行きます。
研究の基礎
自動運転車の動作は、正しい結果を得るために例外なく考慮しなければならない多くの変数がある方程式に例えることができます。歩行者、他の車、路面の品質 (境界線の視認性)、ドローン自体のシステムの完全性など。科学者の多くの研究、政治家の挑発的な発言、ジャーナリストの鋭い記事は、無人車両(以下、単に車または車)と歩行者との関係に基づいています。これは非常に論理的です。特に、彼の行動の予測不可能性を考えると、人とその安全が最優先されるべきだからです。車が道路に飛び出した歩行者に衝突した場合、誰の責任になるかについての道徳的および倫理的な紛争は、今日まで続いています。
ただし、比喩的な方程式から変数「歩行者」を削除すると、潜在的に危険な要素がまだたくさんあります。天気もその一つです。明らかに、悪天候 (暴風雨や吹雪) では視界が非常に悪くなり、車を運転するのは非現実的であるため、停車しなければならないこともあります。もちろん、車の視界は人の視界と比較するのは難しいですが、センサーは私たちと同じように視界の低下に苦しんでいます。一方、自動車には、カメラ、ミリ波 (MMW) レーダー、全地球測位システム (GPS)、ジャイロ スタビライザー (IMU)、光検出および測距 (LIDAR)、さらには超音波システムなど、幅広いセンサーが搭載されています。このようにさまざまな感覚があるにもかかわらず、自動運転車は悪天候時には依然として目が見えません。
何が問題なのかを理解するために、科学者は側面を検討することを提案します。その組み合わせは、意味セグメンテーション、通過可能な (適切な) 経路の検出、センサーの組み合わせなど、この問題の解決策に何らかの形で影響します。
セマンティック セグメンテーションでは、画像内のオブジェクトを検出する代わりに、各ピクセルが個別に分類され、ピクセルが最もよく表すクラスに割り当てられます。つまり、セマンティック セグメンテーションはピクセル レベルの分類です。古典的なセマンティック セグメンテーション - 畳み込みニューラル ネットワーク (畳み込みニューラル ネットワーク A のCNN ) - は、コーディング ネットワークとデコーディング ネットワークで構成されています。
コーディング ネットワークは入力データをダウンサンプリングして関数を抽出し、デコーディング ネットワークはこれらの関数を使用して入力データを回復およびアップサンプリングし、最後に各ピクセルにクラスを割り当てます。
デコード ネットワークの 2 つの重要なコンポーネントは、いわゆる MaxUnpooling 層と転置畳み込み層です。処理されたデータの次元を減らすには、MaxUnpooling レイヤー (MaxPooling レイヤーの類似物 - maximum 関数を使用したプーリング操作) が必要です。
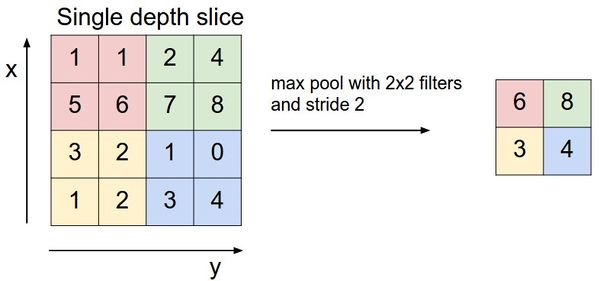
MaxPooling 操作の例。
MaxPooling レイヤーに最大値の場所を保存し、それらの場所を使用して最大値を一致する場所に戻すという共通の目標を持つ、値を分散する (つまりプルする) 方法がいくつかあります。対応する MaxUnpooling 層。このアプローチでは、エンコーダーの各 MaxPooling レベルがデコーダー側に対応する MaxUnpooling レベルを持つ、コーデック ネットワークが対称的である必要があります。
別のアプローチは、カーネルが指す領域の所定の場所 (たとえば、左上隅) に値を配置することです。後で少し説明するモデリングで使用されたのはこの方法でした。
転置畳み込み層は、通常の畳み込み層の反対です。これは、入力をスキャンして値を畳み込み、出力画像を埋める可動コアで構成されています。 MaxUnpooling と Transpose の両方のレイヤーの出力ボリュームは、カーネル サイズ、パディング、およびピッチを調整することで制御できます。
悪天候問題の解決に重要な役割を果たす第二の側面は、通行可能経路の検出である。
歩行者道とは、車が物理的に安全に移動できる空間のことです。車道検出。この側面は、さまざまな状況で非常に重要です: 駐車場、道路標識が不十分、視界が悪いなど。
科学者によると、通行可能な経路の検出は、車線や物体を検出するための準備段階として実行できます。このプロセスは、セマンティック セグメンテーションに由来し、その目的は、ピクセル マップされたデータセットでのトレーニング後にピクセルごとの分類を生成することです。
3 番目の重要な側面は、センサー フュージョンです。これは、文字通り複数のセンサーからのデータを組み合わせて、より完全な画像を取得し、個々のセンサーのデータで発生する可能性のあるエラーや不正確さを減らすことを意味します。センサーには、同種および異種のプーリングがあります。前者の例は、複数の衛星を使用して GPS 位置を調整することです。 2 番目の例は、自動運転車用のカメラ データ、LiDAR、レーダーの組み合わせです。
上記のセンサーはそれぞれ、実際に優れた結果を示していますが、それは通常の気象条件でのみです。過酷な労働条件では、彼らの欠点が明らかになります。
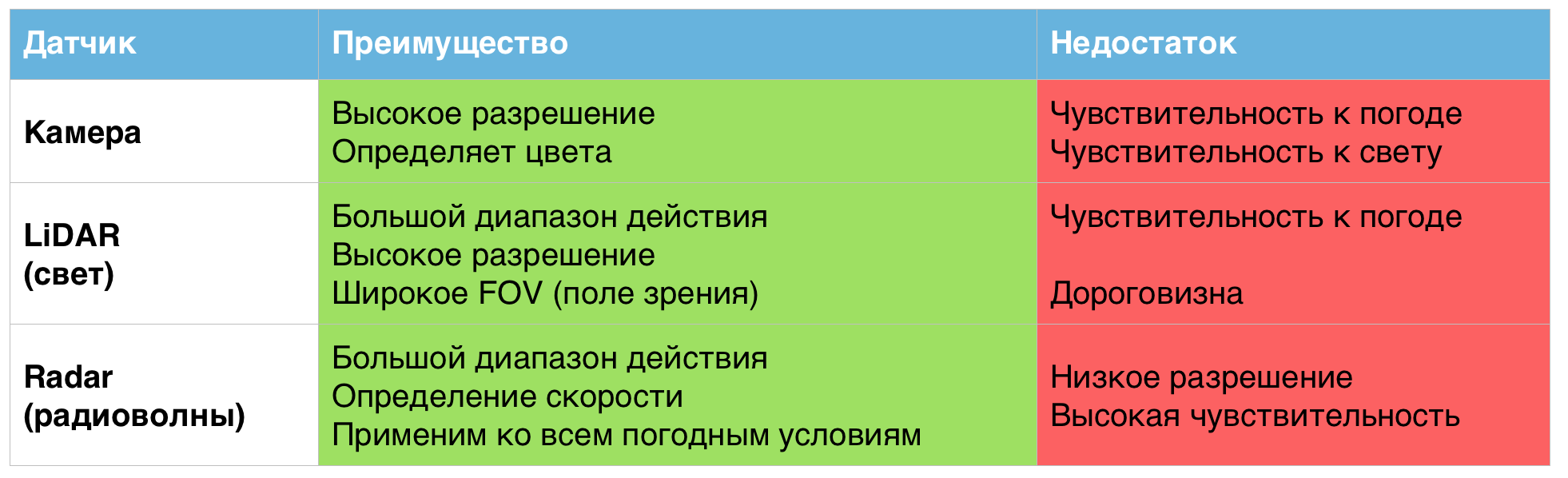
無人車両に使用されるセンサーのメリットとデメリットをまとめた表。
科学者によると、これらのセンサーを単一のシステムに組み合わせることで、悪天候に関連する問題を解決できるのはそのためです。
データ収集
この研究では、前述のように、畳み込みニューラル ネットワークとセンサー フュージョンを使用して、悪天候時の走行経路を見つけるという問題を解決しました。提案されたモデルは、マルチスレッド (センサーごとに 1 つのスレッド) の深層畳み込みニューラル ネットワークであり、各ストリームの関数マップ (前の層に 1 つのフィルターを適用した結果) をダウンサンプリングし、データを結合してから、再アップサンプリングします。ピクセルごとの分類を実行するマップ。
計算、モデリング、テストなど、さらに作業を行うには、大量のデータが必要でした。科学者自身が言うことは、多ければ多いほど良いことです。これは、さまざまなセンサー (カメラ、LiDAR、レーダー) の操作に関して言えば、非常に論理的です。多くの既存のデータセットの中から、研究に必要なニュアンスのほとんどをカバーする DENSE が選択されました。
密度が高いは、厳しい気象条件で道を見つける問題を解決することを目的としたプロジェクトでもあります。 DENSE に取り組んでいる科学者は、北ヨーロッパを約 10,000 km 移動し、複数のカメラ、複数の LiDAR、レーダー、GPS、IMU、道路摩擦センサー、熱画像カメラからのデータを記録しました。データセットは 12,000 のサンプルで構成されており、特定の条件 (昼と雪、夜と霧、昼と晴れなど) を表す小さなサブグループに分けることができます。
ただし、モデルが正しく動作するためには、DENSE からのデータを修正する必要がありました。データセットの元のカメラ画像は 1920 x 1024 ピクセルで、トレーニングとモデル テストを高速化するために 480 x 256 に縮小されています。
LiDAR データは、画像に変換し、スケーリング (最大 480 x 256) して正規化する必要がある NumPy 配列形式で保存されます。
レーダー データは、フレームごとに 1 つのファイルである JSON ファイルに保存されます。各ファイルには、検出されたオブジェクトの辞書と、x 座標、y 座標、距離、速度など、各オブジェクトのいくつかの値が含まれています。この座標系は、車両の平面に平行です。垂直平面に変換するには、y 座標のみを考慮する必要があります。
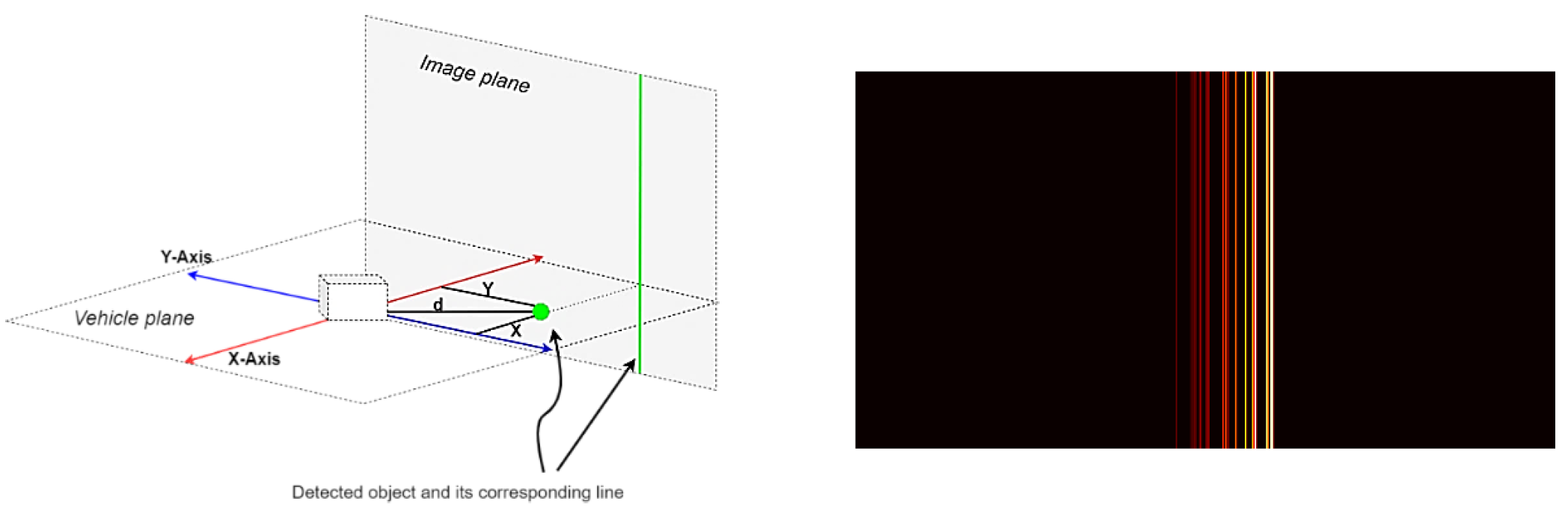
画像 # 1: 画像平面 (左) と処理されたレーダー フレーム (右) への y 座標の投影。
結果の画像はスケーリング (最大 480 x 256) され、正規化されました。
CNN モデルの開発
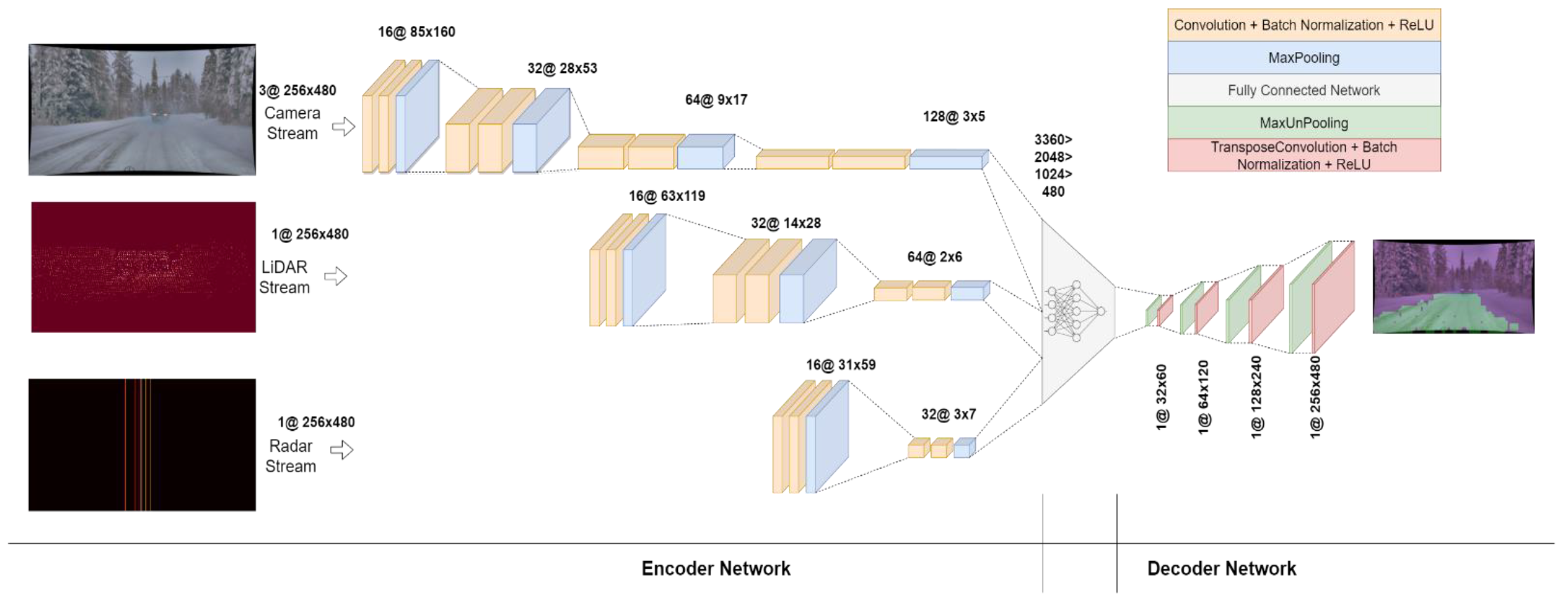
画像 # 2: CNN モデルのアーキテクチャ。
ディープ コーデック ネットワークは多くの計算リソースを必要とするため、ネットワークは可能な限りコンパクトになるように設計されています。このため、デコード ネットワークは、コーディング ネットワークほど多くのレイヤーを使用して設計されていません。コーディング ネットワークは、カメラ、LiDAR、レーダーの 3 つのストリームで構成されます。
カメラ画像にはより多くの情報が含まれているため、カメラ ストリームは他の 2 つよりも深くなります。これは 4 つのブロックで構成され、各ブロックは 2 つの畳み込み層 (バッチ正規化層と ReLU 層) で構成され、その後に MaxPooling 層が続きます。
LiDAR データはカメラからのデータほど大量ではないため、そのストリームは 3 つのブロックで構成されます。同様に、レーダー ストリームは LiDAR ストリームよりも小さいため、2 つのブロックのみで構成されます。
すべてのストリームからの出力は変更され、ReLU アクティベーションを使用して 3 つの隠れ層のネットワークに接続された 1 次元ベクトルに結合されます。次に、データは 2 次元配列に変換され、4 つの連続する MaxUnpooling および転置畳み込みステップで構成されるデコード ネットワークに渡され、データが入力サイズ (480x256) にアップサンプリングされます。
CNN モデルのトレーニング / テスト結果
トレーニングとテストは、GPU を使用して Google Colab で行われました。手作業でタグ付けされたデータのサブセットは、1000 個のカメラ、LiDAR、レーダー データ サンプルで構成されました。800 個はトレーニング用、200 個はテスト用です。
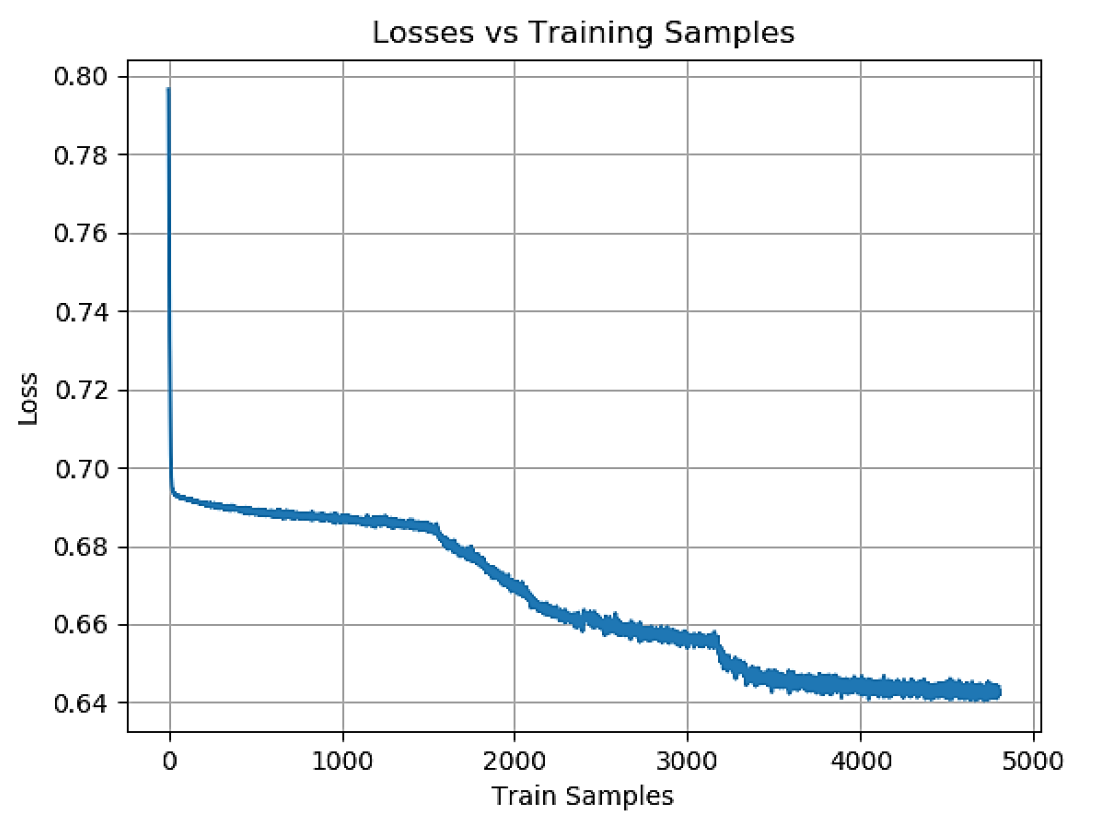
画像 # 3: トレーニング フェーズ中のトレーニング サンプルの損失。
モデルの出力は、ピクセル分類出力のノイズ量を減らすために、さまざまなカーネル サイズで画像の拡張と収縮によって後処理されました。
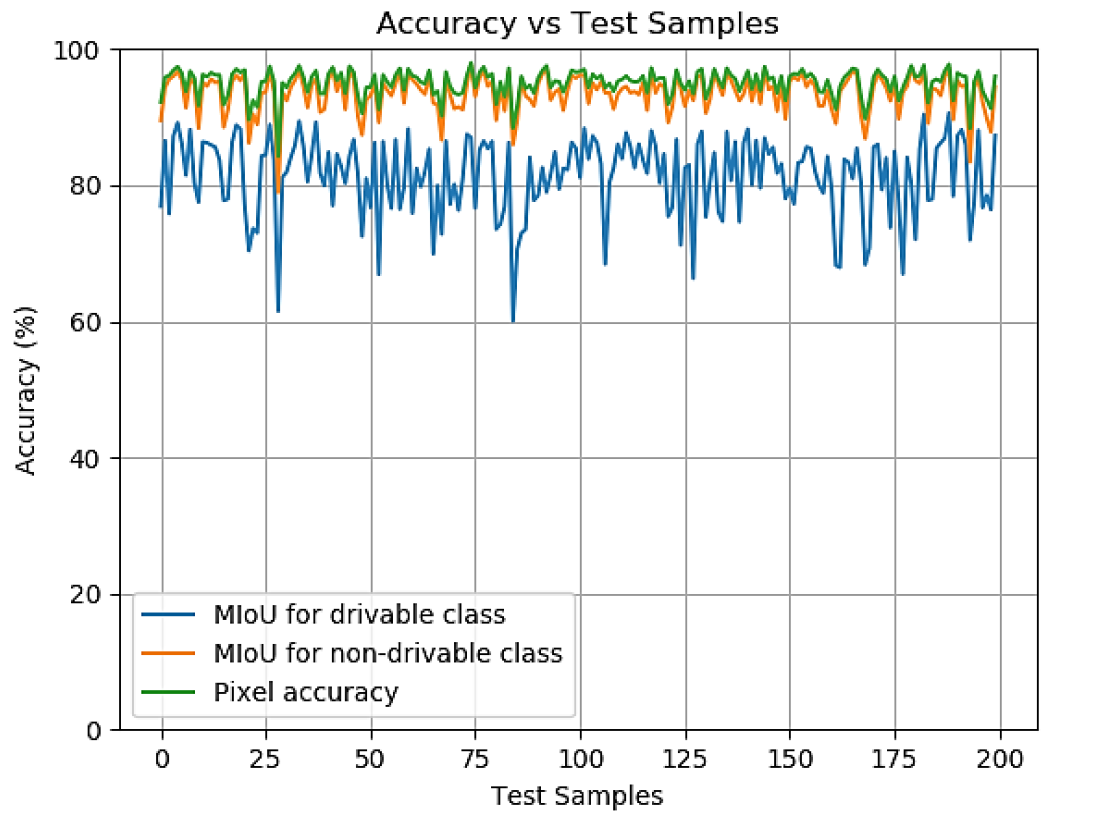
画像 # 4: テスト段階でのテスト サンプルの精度。
科学者は、システム精度の最も単純な指標はピクセルであると指摘しています。正しく定義されたピクセルと正しく定義されていないピクセルの画像サイズに対する比率。テスト セットの各サンプルについてピクセル精度が計算され、これらの値の平均がモデルの全体的な精度を表します。
ただし、この図は理想的ではありません。場合によっては、サンプルで特定のクラスが過小評価され、特定のクラスのモデルをテストするのに十分なピクセルがないため、ピクセル精度が (実際よりも) 大幅に高くなります。したがって、結合領域に対する交差領域の平均比率である MIoU を追加で使用することが決定されました。
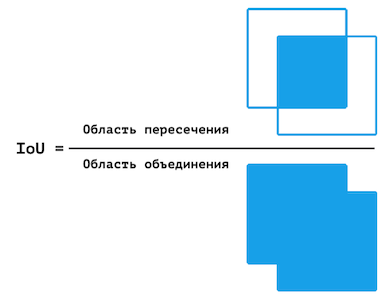
IoU の視覚的表現。
ピクセル精度と同様に、IoU 精度はフレームごとに計算され、最終的な精度はこれらの値の平均です。ただし、MIoU はクラスごとに個別に計算されます。

精度値表。

画像 # 5 上
の画像は、カメラ、LiDAR、レーダー、地上データ、およびモデル出力から選択された 4 つの雪の動きのフレームを示しています。これらの画像から、モデルが車両が安全に移動できる領域の一般的な円周を描くことができることが明らかです。モデルは、そうでなければ車道の端と解釈される可能性のあるすべての線と端を無視します。このモデルは、視界の悪い状態 (霧など) でも優れた性能を発揮します。
このモデルは歩行者、他の車、動物も避けていますが、これはこの特定の研究の主な目的ではありません。ただし、この特定の側面は改善する必要があります。ただし、システムのレイヤー数が少ないため、以前のシステムよりもはるかに高速に学習します。
研究のニュアンスをより詳しく知るために、科学者の報告と 追加データを調べることをお勧めします 。
エピローグ
自動運転車に対する姿勢はあいまいです。一方で、ロボ カーは人的要因 (飲酒運転、無謀、交通規則に対する無責任な態度、運転経験の浅いなど) などのリスクを否定します。つまり、ロボットは人間のようには振る舞いません。いいですね。はいといいえ。自動運転車は、多くの点で生身のドライバーよりも優れていますが、すべてではありません。悪天候はその最たる例です。もちろん、吹雪の中で人が運転するのは容易なことではありませんが、無人車両の場合、それはほとんど非現実的でした。
この研究では、科学者はこの問題に注意を向け、機械をもう少し人間らしくすることを提案しました。実際、人には、環境に関する最大限の情報を確実に受け取るためにチームで機能するセンサーもあります。無人車両のセンサーが、その個別の要素としてではなく、単一のシステムとしても機能する場合、より多くのデータを取得することができます。通過可能な経路を見つける精度を向上させます。
もちろん、悪天候は総称です。小雪は悪天候の場合もあれば、 ha ha haの嵐である場合もあります。開発されたシステムのさらなる調査とテストにより、すべての気象条件で道路を認識することを教えてくれるはずです。
ご清聴ありがとうございました。好奇心を持ち続けて、良い週をお過ごしください。 :)
ちょっとした宣伝
ご宿泊いただきありがとうございます。私たちの記事が気に入りましたか? もっと面白いコンテンツを見たいですか?注文や友人に推薦することにより、私たちをサポートして、 クラウドVPS $ 4.99からご開発者のための、 私たちはあなたのために発明したことをエントリーレベルのサーバのユニークなアナログ: VPSについて真実(KVM)E5-2697 v3の(6つのコア) 10GB DDR4 480GB SSD 1Gbpsが19ドルからか、サーバーを正しく分割する方法は?(RAID1 および RAID10 で利用可能なオプション、最大 24 コアおよび最大 40GB DDR4)。
Dell R730xd は、アムステルダムの Maincubes Tier IV データセンターで 2 倍安いですか? Intel TetraDeca-Core Xeon 2x 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TVがオランダで199 ドルからあるのは私たちだけ です!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - 99ドルから! ビルのインフラストラクチャを構築する方法についてお読みください 。1 ペニーで 9000 ユーロのコストで、Dell R730xd E5-2650 v4 サーバーを使用するクラス?