
前回、あなたと私は平行本の作り方を学び、Harper Lee の小説 To Kill a Mockingbird からの抜粋のロシア語版を作成しました。今日、私たちは次のステップに進み、8 つの言語で完全な多言語の本を作成します。
このプロジェクトの目標は、外国語を勉強して教える人々が学習教材や平行本を作成して読解力を向上させるのに役立つツールを作成することであることを思い出してください。世界的な問題は、対訳で興味深い資料を見つけるのが難しいことですが、オリジナルとそのロシア語版を別々に見つける方がはるかに簡単です。
まずは7冊作りましょう
" ", . ( ); , ( ); . , . . pdf .
-.

1.
( , ).
- ( , , , ).
- .
- (H1 , H5 ), .
- , , ( ).
, . , . .
, :
| %%%%%title. | ||
| %%%%%author. | ||
| %%%%%h1. %%%%%h2. %%%%%h3. %%%%%h4. %%%%%h5. | ||
| %%%%%divider. | ||
| %%%%%. |
, , . .
, :
%%%%%title. .. %%%%%author. %%%%%h1. 1%%%%%h2. %%%%%h2. , , , , . , , , , , , . – , , – , . ...
MIHAIL BULGAKOV%%%%%author. A MESTER ÉS MARGARITA%%%%%title. ELSŐ KÖNYV%%%%%h1. ELSŐ FEJEZET%%%%%h2. Ne álljunk szóba ismeretlenekkel%%%%%h2. Egy meleg tavaszi estén, az alkonyat órájában, a Patriarsije Prudin két férfiú jelent meg. Az egyik negyvenéves forma, kövérkés, alacsony, kopasz fekete emberke, szürke nyári öltönyt viselt, elegáns kalapját kezében tartotta, gondosan borotvált arcát istentelen nagy méretű, fekete csontkeretes pápaszem ékesítette. Társa jóval fiatalabb s vállasabb volt nála, borzas haján tarkójáig hátratolt kockás sapka; öltözéke kockás sportingből, gyűrött fehér nadrágból, fekete szandálból állt. ...
. - , - . , .
2.
Colab
Colab , . . html .
pip install lingtrain-aligner
:
# from lingtrain_aligner import preprocessor, splitter, aligner, resolver, reader, vis_helper # text1_input = "master_hu.txt" text2_input = "master_ru.txt" with open(text1_input, "r", encoding="utf8") as input1: text1 = input1.readlines() with open(text2_input, "r", encoding="utf8") as input2: text2 = input2.readlines() # , db_path = "master_hu.db" # ( ) lang_from = "hu" lang_to = "ru" # models = ["sentence_transformer_multilingual", "sentence_transformer_multilingual_labse"] model_name = models[0] # text1_prepared = preprocessor.mark_paragraphs(lines1_prepared) text2_prepared = preprocessor.mark_paragraphs(lines2_prepared) # splitted_from = splitter.split_by_sentences_wrapper(lines1_prepared, lang_from, leave_marks=True) splitted_to = splitter.split_by_sentences_wrapper(lines2_prepared, lang_to, leave_marks=True)
9460 8996 . - , .
. SQLite , , .
aligner.fill_db(db_path, lang_from, lang_to, splitted_from, splitted_to)
, :
batch_ids = range(10) aligner.align_db(db_path, model_name, batch_size=100, window=60, batch_ids=batch_ids, save_pic=False, embed_batch_size=25, normalize_embeddings=True, show_progress_bar=True )
— ( ), 10 (batch_ids — ) 100 ( batch_size). window "" , . , " " .
, . ( ), shift ( ).
vis_helper:
vis_helper.visualize_alignment_by_db(db_path, output_path="alignment_vis.png", batch_size=100, size=(800,800), lang_name_from=lang_from, lang_name_to=lang_to, batch_ids=batch_ids, plt_show=True)
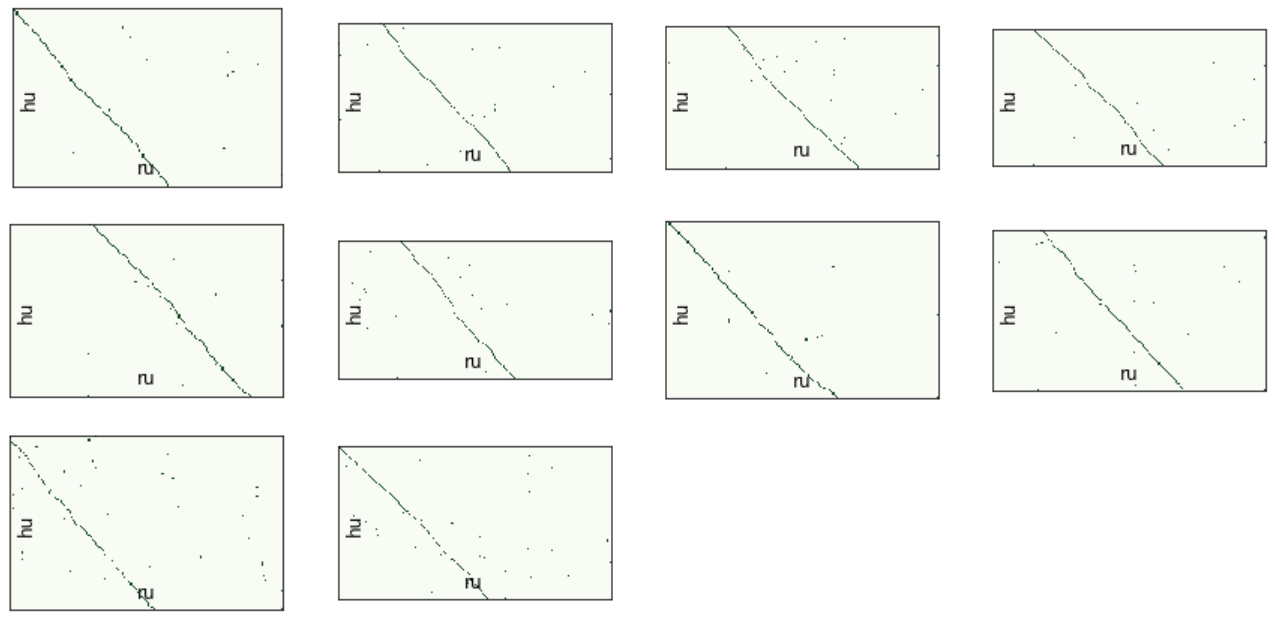
batch_ids , . , .
, . , " " , .
.
resolver. , , . , , . , . , — :
steps = 3 batch_id = -1 # for i in range(steps): # conflicts, rest = resolver.get_all_conflicts(db_path, min_chain_length=2+i, max_conflicts_len=6*(i+1), batch_id=batch_id) # resolver.get_statistics(conflicts) resolver.get_statistics(rest) # resolver.resolve_all_conflicts(db_path, conflicts, model_name, show_logs=False) if len(rest) == 0: break
. , :
# conflicts, rest = resolver.get_all_conflicts(db_path, min_chain_length=2, max_conflicts_len=20, batch_id=-1) # resolver.get_statistics(conflicts) resolver.get_statistics(rest) # resolver.resolve_all_conflicts(db_path, conflicts, model_name, show_logs=False) # vis_helper.visualize_alignment_by_db(db_path, output_path="alignment_vis.png", batch_size=100, size=(800,800), lang_name_from=lang_from, lang_name_to=lang_to, batch_ids=batch_ids, plt_show=False)
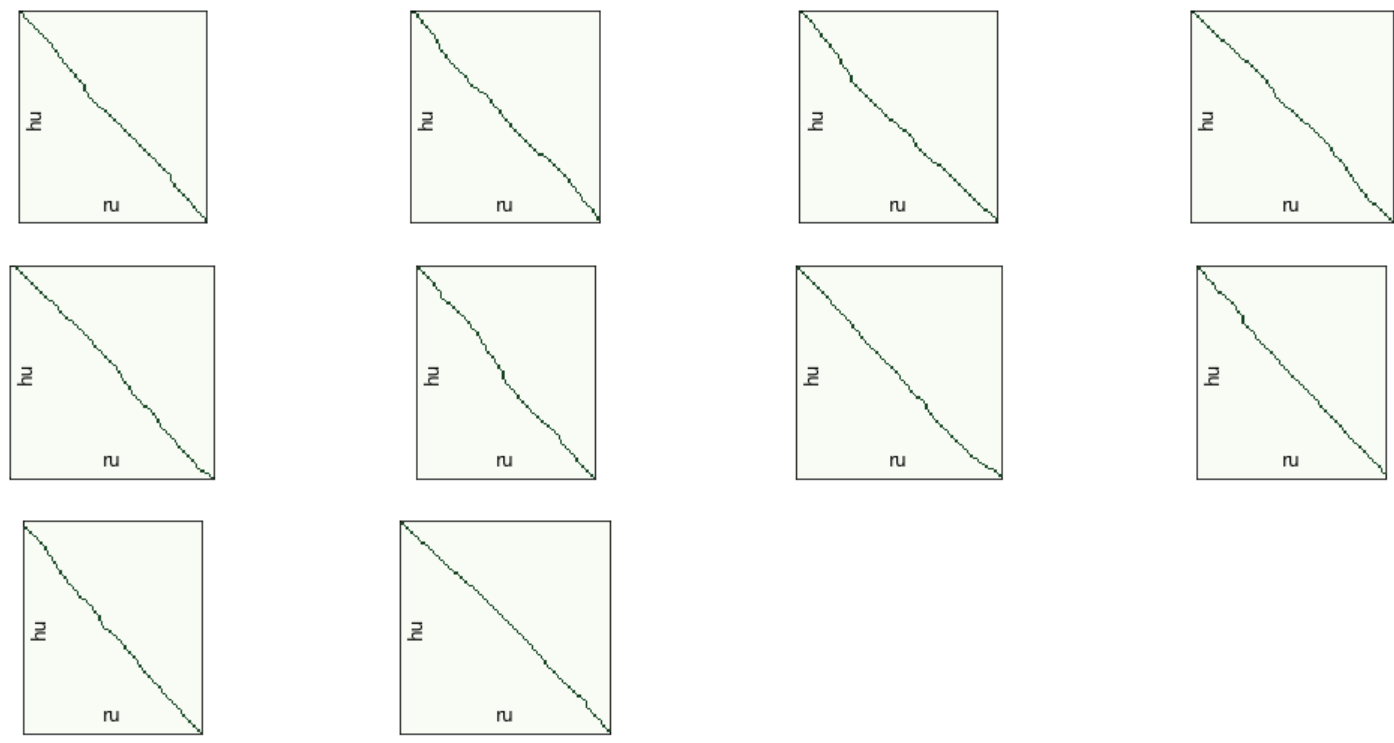
. , . 4000 . 10 100 , :
batch_ids = range(10, 50) aligner.align_db(db_path, \ model_name, \ batch_size=100, \ window=60, \ batch_ids=batch_ids, \ save_pic=False, embed_batch_size=25, \ normalize_embeddings=True, \ show_progress_bar=True )
( , ) , . , . 9460, , 100 95 .
batch_ids = range(50, 100)
( ) . master_hu, - " ".
3.
, reader, - :
from lingtrain_aligner import reader # paragraphs_from, paragraphs_to, meta = reader.get_paragraphs(db_path, direction="from") # html reader.create_book(paragraphs_from, paragraphs_to, meta, output_path = "lingtrain.html")

html . . , :
reader.create_book(paragraphs_from, paragraphs_to, meta, output_path = f"lingtrain.html", template="pastel_fill")
, :
# span' my_style = [ '{"background": "linear-gradient(90deg, #FDEB71 0px, #fff 150px)", "border-radius": "15px"}', '{"background": "linear-gradient(90deg, #ABDCFF 0px, #fff 150px)", "border-radius": "15px"}', '{"background": "linear-gradient(90deg, #FEB692 0px, #fff 150px)", "border-radius": "15px"}', '{"background": "linear-gradient(90deg, #CE9FFC 0px, #fff 150px)", "border-radius": "15px"}', '{"background": "linear-gradient(90deg, #81FBB8 0px, #fff 150px)", "border-radius": "15px"}' ] reader.create_book(paragraphs_from, paragraphs_to, meta, output_path = f"lingtrain.html", template="custom", styles=my_style)

, , master_hu.db . , (, , , ).
, .
1. – ! – , – , , ! 2. - - , – , , .
1. 'Pah, the devil!' exclaimed the editor. 2. 'You know, Ivan, I nearly had heat stroke just now! 3. There was even something like a hallucination...' 4. He attempted to smile, but alarm still jumped in his eyes and his hands trembled.
9707 8996 . , window=100 1000 .

, .

, .
, , . (8190 ) . 100 , — :
batch_ids = range(10,12) aligner.align_db(db_path, \ model_name, \ batch_size=200, \ window=100, \ batch_ids=batch_ids, \ save_pic=False, embed_batch_size=25, \ normalize_embeddings=True, \ show_progress_bar=True )

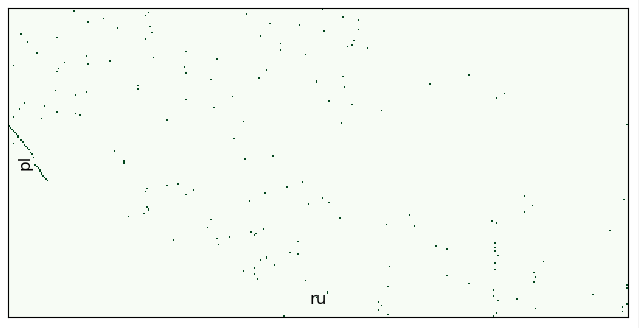
, shift. :
batch_ids = range(10,12) aligner.align_db(db_path, \ model_name, \ batch_size=200, \ window=100, \ batch_ids=batch_ids, \ save_pic=False, embed_batch_size=25, \ normalize_embeddings=True, \ show_progress_bar=True, shift=-100 # )
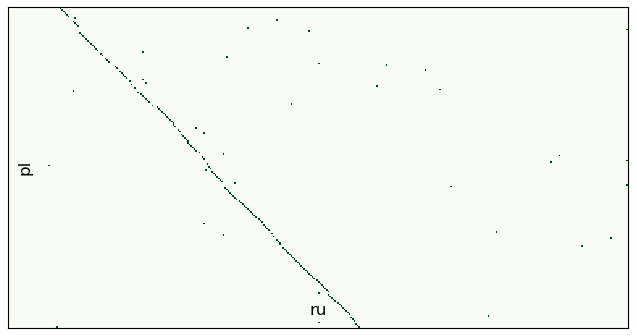

, , . .
:


, - :


, - . - ( ), , , . 20 , .
master_*.
, (). , .
:

, ( ) . , . , . , ( *.db ).
, . , .
:
par_struct_1 = [2, 5, 6, 8, 10, 12, ...] par_struct_2 = [2, 6, 8, 10, 11, 12, ...] res = [2, 6, 8, 10, 12, ...]
, :

, .
, , :

, . , , — .
. :
[ -- [ -- [1, "[1,2]", 1, "[1]"], -- .. [2, "[3]", 2, "[2]"], [3, "[4,5]", 3, "[3]"], [4, "[6]", 4, "[4,5,6]"], ... ], -- [ [1, "[100]", 1, "[105]"], ... ], ... ]
"" "". — , — , .
:
- ,
- ,
- ,
, . , . :
[[1], [2], [3]] -> [[1, 2, 3], [4], [5]] -> [[1], [2], [3]] [[4]] -> [[6]] -> [[4]] [[5]] -> [[7]] -> [[5, 6]] ...
— , — . .
, :

( ), , . , :

4.
get_paragraphs() create_book(). , .
get_paragraphs_polybook(), . , , . ( ):
from lingtrain_aligner import resolver conflicts_to_solve, rest = resolver.get_all_conflicts(db_path, min_chain_length=2, max_conflicts_len=20, batch_id=-1) # resolver.get_statistics(conflicts_to_solve) resolver.get_statistics(rest)
:
from lingtrain_aligner import reader db_path1 = "db/master_de.db" db_path2 = "db/master_uk.db" db_path3 = "db/master_be.db" db_path4 = "db/master_zh.db" db_path5 = "db/master_cz.db" db_path6 = "db/master_en.db" db_path7 = "db/master_hu.db" paragraphs, metas = reader.get_paragraphs_polybook( db_paths=[db_path1, db_path2, db_path3, db_path4, db_path5, db_path6, db_path7])
今最も興味深いのは、必要な言語を選択して本を作成できることです。たとえば、英語とドイツ語を取り上げることができます。多くの場合、これらの言語をペアで学習します。
reader.create_polybook( lang_ordered=["en", "de", "ru"], paragraphs = paragraphs, delimeters = delimeters, metas = metas, output_path = "lingtrain_master.tml", template="none")

lang_orderedパラメータ は、言語のセットと順序を指定します。
ベラルーシ中国語バージョンを作成できます。
reader.create_polybook( lang_ordered=["be", "zh"], paragraphs = paragraphs, delimeters = delimeters, metas = metas, output_path = "lingtrain_master.html", template="none")

もちろん、すべてを取ることができます。
reader.create_polybook( lang_ordered = ["ru", "en", "de", "be", "uk", "cz", "hu", "zh"], paragraphs = paragraphs, delimeters = delimeters, metas = metas, output_path = "lingtrain_master_total.html", template="none")

必要な言語であるそれらのアライメント (* .db ファイル) を残すことをお勧めします。これにより、段落に関するできるだけ多くの情報が保持されます。スタイルを使用すると、すべてが以前と同じで、テンプレートを設定でき(現在は「pastel_fill」、「pastel_start」があります)、独自のスタイルを 作成できます。例は上記と Colab のノートブックにあります。template = "none"を設定 すると、空白の本が表示されます。
プランとサポート
- fb2 . , . -, .
- , http://t.me/lingtrain_books.
- . - .
:
[3] Google Colab
[6]電報グループ