
現代の計算言語学では、書かれていることや言われていることの意味を理解することは、自然言語モデル (NLU) を使用して達成されます。サリュート仮想アシスタントの視聴者が徐々に増加するにつれて、自然言語で動作するサービスを最適化するという問題が発生します。これを行うには、1 つの強力な NLU モデルを使用して、一度に複数のワープロ問題を解決することをお勧めします。この記事では、マルチタスク学習を使用してベクトル表現を改善し、SBERT を使用してより一般的な NLU モデルをトレーニングする方法を示します。
負荷の高いワード プロセッシング サービスは、さまざまな NLP タスクを解決します。
- 意図を認識する。
- 名前付きエンティティの強調表示。
- 感情分析。
- 毒性分析。
- 類似のクエリを検索します。
これらのタスクにはそれぞれ固有の特徴があり、一般的に言えば、個別のモデルの構築とトレーニングが必要です。ただし、そのようなタスクごとに個別の NLU モデルを維持して実行することは非現実的です。リクエストの処理時間と消費される (ビデオ) メモリが大幅に増加します。代わりに、1 つの強力な NLU モデルを使用して、テキストから一般的な特徴を抽出します。これらの機能に加えて、適用される NLP の問題を解決する比較的軽量なモデル (アダプター) を適用します。同時に、NLU とアダプターを異なるマシンで実行できるため、ソリューションの展開とスケーリングが容易になります。

しかし、ベース NLU モデルによって識別された機能を十分に普遍的なものにして、その上に高品質の NLP モデルを構築できるようにする方法は? 解いてみましょう。
伝統的に、Python 3 と TensorFlow 1.15 でのアプローチの実装を示します。完全なステップバイステップ ガイドとコード例は、ここで見つけることができます - Colab。
また、公開されて いる更新された ロシアのモデル SBERT-NLUクラスBERT-ラージ [4 億 2700 万オプション] バージョン マルチタスク: ハギングフェイス [tensorflow、pytorch] もレイアウトします。
マルチタスク学習。なぜこれが必要なのですか?
NLU モデルの操作中に、1 つのタスク (たとえば、NLI )用にトレーニングされたモデルによって割り当てられた機能は、他のダウンストリーム タスク (たとえば、分類や感情分析など) で非常にうまく再利用できることがわかりました 。これを行うために、新しい問題を解決するために鋭敏化された軽量モデル (アダプター) は、基本モデルによって選択されたベクトルでトレーニングされます。これは基本モデルを変更しません。
同時に、そのようなアダプター モデルの品質は、タスクごとに NLU モデルをトレーニングした場合よりも通常はさらに悪化します。その理由は、新しいデータはアダプター モデルにのみ使用され、ベース モデルを改善しないためです。マルチタスク学習は、これに対処するのに役立ちます。
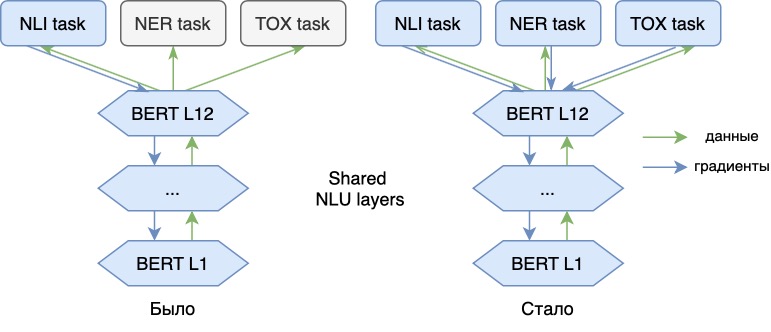
現在、主要な NLI 問題だけでなく、追加の問題 (NER、毒性分析) についても言語モデルをトレーニングしています。新しいタスクを追加すると、モデルのベクトルに新しい「意味」を追加でき、より普遍的なものになります。したがって、モデルは、たとえば、フレーズのスピーチの感情的な色合いや、テキスト内の各単語のスピーチの部分についての情報をベクトルに反映することができます。このようなモデルのベクトル表現を使用すると、これらの問題をより効率的に解決できます。
0.実験
例として、次の 3 つのタスクで NLU を教える場合を考えてみましょう。
- 文の表現 (NLI)。
- 固有表現抽出 (NER)。
- 感情分析。
文のベクトル化の主なタスクを教えるために、 前回のように、結果 (「含意」)、矛盾 (「矛盾」)、または不在を示すラベル付きの文のペアを含む、自然言語推論のデータセットを使用 します。センテンス間のセマンティック接続 (「ニュートラル」)。このデータについて、BERTモデルに基づいて、対応する文のペア間の類似性が、互いに矛盾するまたは中立的な間の類似性よりも大きくなるようなベクトル表現を学習します。 データセットを使用して
NERヘッドを トレーニングしますkaggle プラットフォームから。このモデルは、処理中のプロポーザル内の各トークンを、いくつかのIOB名前付きエンティティ タイプの 1 つに割り当てます 。そのタスクは多クラス分類です。
感情分析の問題については、ツイートの感情抽出コンペティションからデータを取りましょう 。このコンテストの本質は、Twitterの投稿に対するコメントの感情の色を予測することです。データセットには、レプリカのポジティブ、ニュートラル、ネガティブの 3 つのクラスがあります。この例では、ポジティブとネガティブの 2 つのクラスのみを強調します。タスクは二項分類になります。
基本的なベクトル化モデルとして、事前学習済みの英語の BERT ベースを使用します。
実験計画:
- データセットを準備しています。
- バッチジェネレーターの実装。
- 損失関数の決定。
- モデルの構築。
- 検証プロセスの準備。
- モデルトレーニング。
- 結果と結論の議論。
1. データ準備
まず、基本的な文ベクトル化モデルのトレーニングに必要なデータセット - [ SNLI、 MNLI ] とその検証に必要なデータセット- [ STS SICK ] をロードしましょう 。さらに、事前トレーニング済みの英語の BERT モデルが必要です。幸いなことに、これらはすべてパブリック ドメインにあります。
次に、kaggleプラットフォームに移動して、感情分析のためにそこからデータをダウンロード しましょう 。ここでは train.csv が必要です。このデータについて、別のクラスで否定的な例を選び出し、残りを共通のグループ (肯定的、中立的) に結合します。
NERのデータを取得 し、[text, ner_labels] 形式で準備する必要があります。
2.バッチジェネレーター
では、ニューラル ネットワークをトレーニングするための例のパッケージを生成する手順を記述しましょう。現在、入力として 1 つではなく、すでに 3 つの
データセットを受け取っているため、さらに多くのジェネレーターが必要です 。NLI タスクの場合、トリプレット ジェネレーターを使用して、トリプル
[アンカー、ポジティブ、ネガティブ]を生成し ます。
分類問題の場合、NER と Toxic はペア [サンプル、ラベル] を生成する同じデータ ジェネレーターを使用します。ここでは、提供されたデータセットからクラス ラベルを持ついくつかの例をランダムに選択し、パッケージを形成します。
最後に、3 つのジェネレーターを組み合わせて、3 つのタイプのデータ パケットすべてを 1 つに連結してモデルをトレーニングする共通の複合ジェネレーターを作成しましょう。
3. 損失関数
ここで、タスクごとに独自のエラー関数を定義し、それらを組み合わせて最終的な損失関数を作成します。
- また、言い換え文の「収束」の問題をランキング問題として定式化し、以前の作業ですでに知られているわずかに変更されたSoftmax Loss をエラー関数として使用します。
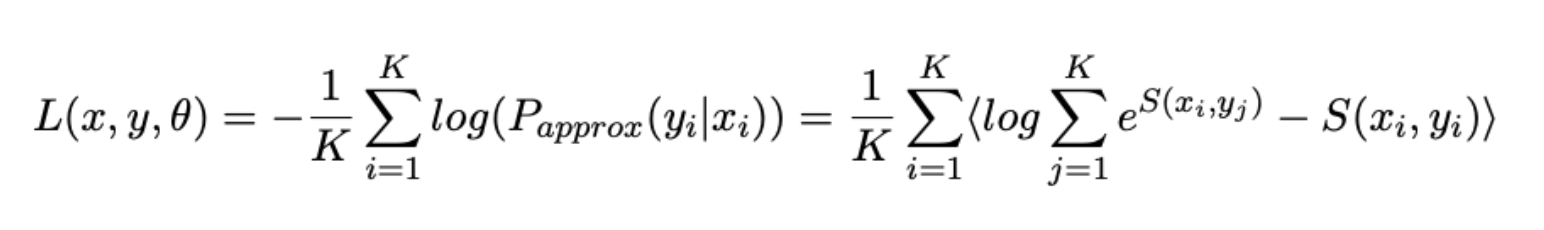
- Binary Cross Entropy Loss:

- NER- -, CrossEnrtopyLoss:

- Joint-loss, :
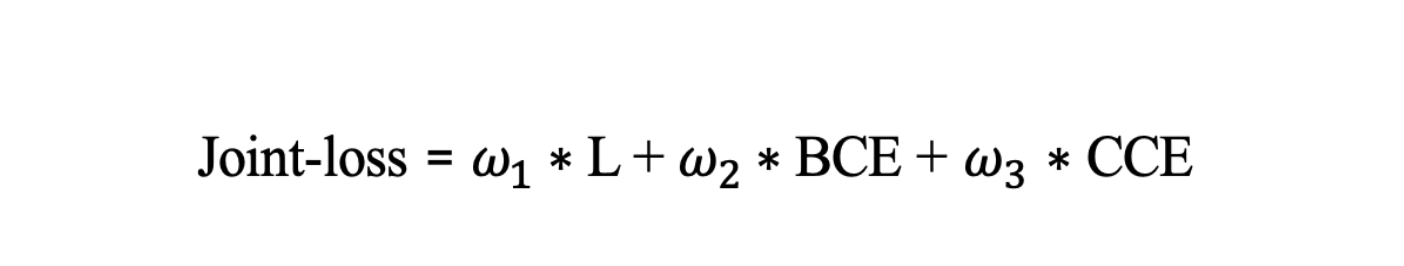
4.
私たちのモデルは、主要な NLU 部分 (ここでは BERT ベースを使用しています) と、各タスクに固有の 3 つの「ヘッド」アダプターで構成されています。
NLI および Toxic タスクの場合、最後の BERT レイヤーから平均トークン埋め込みを取得します (マスクされた平均プーリングを使用します)。NER タスクでは、8 番目のエンコーダ層の出力からのトークン埋め込みを使用します。センテンス レベルの表現を教える場合、トークン レベルの問題の埋め込みは、モデルの中間層から取得するのが最適です。
次のようになります。

マルチタスク モデル アーキテクチャ モデル
を組み立てるためのコード:
5. 結果の検証
文のベクトル化モデルを検証するために、STS 2012–2016 および SICK 2014データセットを使用し ます。
SNLI と同様に、このデータセットにはセンテンスのペアが含まれています。モデルを使用したモデルでそれらをベクトル化し、それらのベクトル間のコサイン近接度を計算することにより、文章間の類似性を推定してみましょう。指標として、データセットのラベルとの順位相関を計算します。
このロジックを含むコールバックコード:
https://gist.githubusercontent.com/gaphex/f2d2e1a9c849ba9d69a3014da705968f/raw/8ac26c3b236979625a906591dd594b9fd8640483/pearsonr_callback.py。
コメントの毒性を判断するタスクは、AUC メトリックに対してテストされます。データ パーティショニングは、クラス分布に関して階層化されます。
https://gist.github.com/Ab1992ao/873227b0834ebe43c95b4b5fe029eb95。
NER マークアップの品質は、精度と F1 測定値という 2 つの指標によって評価されます。
https://gist.github.com/Ab1992ao/e3ea080d36d2bf2d0c1ddc17aa4b9e99。
6. 学習プロセス
私たちはホームストレッチです。これで、データ、モデル、および検証パイプラインができました。ハイパーパラメータと学習リソースに移りましょう。
古典によると、この環境でのアクティビティに応じて、NVIDIA K80 (12GB) / T80 (16GB) ビデオ アクセラレータを備えた Colab を自由に使用できます。マルチタスク アートの作業全体がメモリに収まるようにするには、処理されるシーケンスの適切な最大長 (seq_len) と、もちろんバッチのサイズを選択することが重要です。
この実験では、トレーニングで使用されるほとんどのデータをエンコードするのに十分な、センテンス タスクのトークンを 24 に制限します。センチメントとナータスクには、同じシーケンス長を使用します。
バッチのサイズの増加は、モデルの収束に非常に良い影響を与えます - GPU のメモリに収まる最大のものを選択します。
オプティマイザーとして、古き良き Adam を小さな 学習率で使用します。収束前にモデルをトレーニングします。25 エポックで十分です。
トレーニングパラメータ:
- バッチ サイズ = BERT ベースの場合は 96/72 (それぞれ 16 GB のメモリまたは 12 GB)。
- max_seq_len = 24;
- オプティマイザー アダム。
- 学習率 ~ 2e-6;
- メトリクス - [SpearmanR、F1、AUC];
- エポック数 ~ 25。
SBERT モデルの古いバージョンと新しいバージョンの上でトレーニングされたアダプターのメトリックを比較しましょう。

ご覧のとおり、マルチタスクの追加トレーニングにより、NERとTOXの追加タスクの品質を大幅に向上させることができました。これがモデルの主な機能に損害を与えないことが重要です.STS および SICK データセットのメトリックは同じレベルのままでした。
7. さらなる改善の機会
増強
私たちの作業の一環として、より正確で安定したモデルを取得するのに役立つ追加の操作を使用します。
バッチ生成中に、いくつかの拡張を適用します。その中で、文字レベル、単語レベル、大文字と小文字の変更、句読点の削除を区別できます。
文字のレベルでは、これらは次のとおりです
。1)「prvet」の削除。
2)「挨拶」を繰り返す。
3) 隣接する 2 つのシンボル「Prievt」の入れ替え。
4) キーボード「ようこそ」の閉じるキーの交換。
5) 発音的に近い文字「こんにちは」による置き換え。
単語レベルでは、これらは次のとおりです
。1) 2 つ以上の単語を交換する。
2)寄生虫の言葉の挿入 - 「まあ、これは同じです」
大文字と小文字および句読点の変更に対するモデルの耐性を高めるために、いくつかの例では句読点が削除される場合があります。ランダムトークンの場合、レジスターを変更できます。
単語と記号の変更に関連する拡張は、バッチの 3% に適用され、句読点と大文字化を使用して - 30% に適用されます。
8. 結果と結論
この記事では、マルチタスク リーニングの概念を理解し、この知識を適用して言語モデルのベクトル表現を改善しました。
これらの手法を用いて、ロシア語 SBERT マルチタスクの NLU モデルを改善し、 公開しました。 NER 問題、感情分析、および毒性分析を解決するために、このバージョンのモデルをさらにトレーニングしました。
ロシア語モデルRussianGLUE のベンチマークで、SBERT モデルの両方のバージョンのメトリックを測定しました 。 RuGLUE タスクはマルチタスク再トレーニング プロセスに参加しませんでしたが、モデルの 2 番目のバージョンのメトリックはわずかに増加しました。モデルに 1 つの問題を教えると、視野が広がり、他の問題の品質が向上しました。

SBERTの自然言語モデルをさらに発展させていく予定です。方向性の中で区別することができます: 加速と 蒸留、 基本的なアーキテクチャの改善と新しいタスクの追加。それらについては、次の記事で説明します。NLP テクノロジに興味があり、幅広い聴衆向けの新製品にそれらを実装したい場合は、インタビューにお越しください 。
研究の成功をお祈りしています。
この記事の資料の準備にご協力いただきありがとうございます。 アンドリルホ そして イブラギム_バッド...