1. はじめに
工学的および地質学的調査を実施する場合、調査対象から実験室へのサンプルの正しい輸送を確認するために、同じ土壌でのフィールドと実験室の研究からのデータを比較することに関連するタスクが発生することがあります (サンプルは変形および/または破壊されていません輸送中)。
この問題の定式化により、次のパラメーターを使用して A/B テスト手法を適用できます。
測定基準は、サンプルの追加を特徴付ける土壌骨格の密度 (p d、g / cm 3 )の平均値になります。この値には正規分布の法則があります。
仮説をテストするための基準は、t検定(スチューデント検定)になります: 二つの独立したサンプルのため、比較(輸送前)フィールドと(輸送後の)実験室のデータは、異なる土壌サンプルで実施した場合。 2 つの従属サンプルの場合、同じサンプルで研究が行われた場合。
このトピックの枠組みの中で、2 つのランダムなサンプルを生成し、それらを比較し、統計的仮説を策定し、それらをテストして結論を導き出します。
2. サンプルの生成
2.1 サンプルサイズの推定
実験計画の一環として、密度サンプルを生成する前に、与えられた効果サイズ (ES - 効果サイズ)、 パワー 、および 許容タイプ I エラー (α) に必要なボリュームを見積もりましょう (これらの用語の定義は以下に示されています)。statsmodelsパッケージを使用して計算を行います 。
効果量 (標準化) は、検出したい差を特徴付ける値であり、サンプル間の平均値の差と加重標準偏差の比率に等しい。私たちの場合には:


同じサイズのサンプルにプールされた加重標準偏差 Sは、次の式を使用して計算できます。

(Cohen, 1988) ES = 0.2 - ; 0.5 - ; 0.8 - .
– II ( 80%).
I II :
H0 |
H1 |
|
|---|---|---|
H0 |
H0 |
II (β) |
H0 |
I (α) |
H0 (power = 1-β) |
:
α = 0.05 ( )
ES = 0.5 ( ).
Power = 0.8 ( ).
:
#
import numpy as np
from statsmodels.stats.power import TTestIndPower
from matplotlib.pyplot import figure
import matplotlib.pyplot as plt
import scipy
from statsmodels.stats.weightstats import *
#
effect = 0.5
alpha = 0.05
power = 0.8
analysis = TTestIndPower()
#
size = analysis.solve_power(effect, power=power, alpha=alpha)
print(f' , .: {int(size)}')
, .: 63
, 63 . 65 .
.
plt.figure(figsize=(10, 7), dpi=80)
results = dict((i/10, analysis.solve_power(i/10, power=power, alpha=alpha))
for i in range(2, 16, 1))
plt.plot(list(results.keys()), list(results.values()), 'bo-')
plt.grid()
plt.title(' \n ')
plt.ylabel(' n, .')
plt.xlabel(' ES, ..')
for x,y in zip(list(results.keys()),list(results.values())):
label = "{:.0f}".format(y)
plt.annotate(label,
(x,y),
textcoords="offset points",
xytext=(0,10),
ha='center')
plt.show()
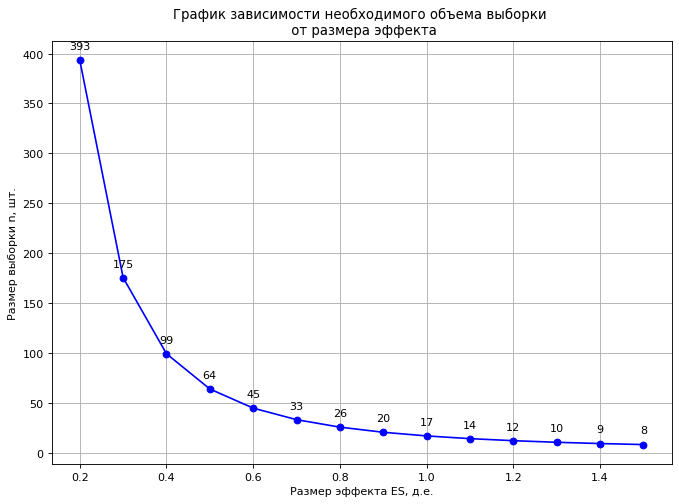
, ES. : 0,03 /3 0,1 /c3 (ES = 0,03 /3 / 0,1 /3 = 0,3 ..), 175 (power=0.80, α=0.05).
2.2
, numpy.
( ) . (X̄) (S):
– X̄1= 1,65 /3, S1 = 0.15 /3;
– X̄2 = 1,60 /3, S2 = 0.15 /3.
loc_1 = 1.65
sigma_1 = 0.15
loc_2 = 1.60
sigma_2 = 0.15
sample_size = 65
#
sample_1 = np.random.normal(loc=loc_1, scale=sigma_1, size=sample_size)
sample_2 = np.random.normal(loc=loc_2, scale=sigma_2, size=sample_size)
" " .
fig, axes = plt.subplots(ncols=2, figsize=(18, 5))
max_y = np.max(np.hstack([sample_1,sample_2]))
# 1
count_1, bins_1, ignored_1 = axes[0].hist(sample_1, 10, density=True,
label=" 1", edgecolor='black',
linewidth=1.2)
axes[0].plot(bins_1, 1/(sigma_1 * np.sqrt(2 * np.pi)) *
np.exp( - (bins_1 - loc_1)2 / (2 * sigma_12)),
linewidth=2, color='r', label=' ')
axes[0].legend()
axes[0].set_xlabel(u' , ')
axes[0].set_ylabel(u' , .')
axes[0].set_ylim([0, 5])
axes[0].set_xlim([1.1, 2.2])
# 2
count_2, bins_2, ignored_2 = axes[1].hist(sample_2, 10, density=True,
label=" 2", edgecolor='black',
linewidth=1.2, color="green")
axes[1].plot(bins_2, 1/(sigma_2 * np.sqrt(2 * np.pi)) *
np.exp( - (bins_2 - loc_2)2 / (2 * sigma_22)),
linewidth=2, color='r', label=' ')
axes[1].legend()
axes[1].set_xlabel(u' , ')
axes[1].set_ylabel(u' , .')
axes[1].set_ylim([0, 5])
axes[1].set_xlim([1.1, 2.2])
plt.show()
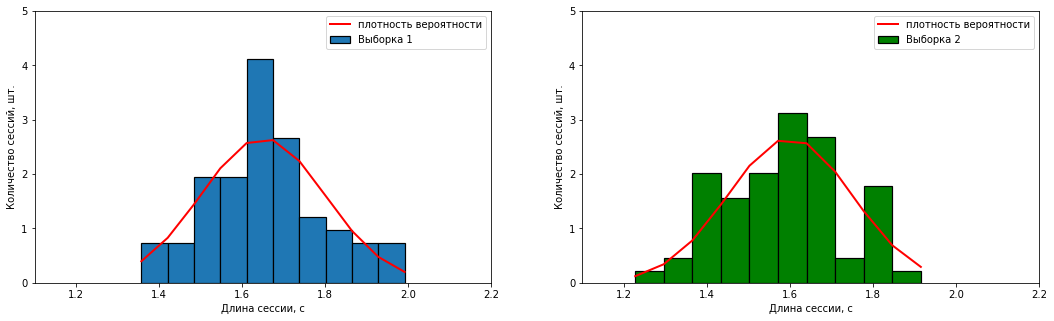
#
fig, ax = plt.subplots(figsize=(8, 8))
axis = ax.boxplot([sample_1, sample_2], labels=[' 1', ' 2'])
data = np.array([sample_1, sample_2])
means = np.mean(data, axis = 1)
stds = np.std(data, axis = 1)
for i, line in enumerate(axis['medians']):
x, y = line.get_xydata()[1]
text = ' μ={:.2f}\n σ={:.2f}'.format(means[i], stds[i])
ax.annotate(text, xy=(x, y))
plt.ylabel(' , /3')
plt.show()
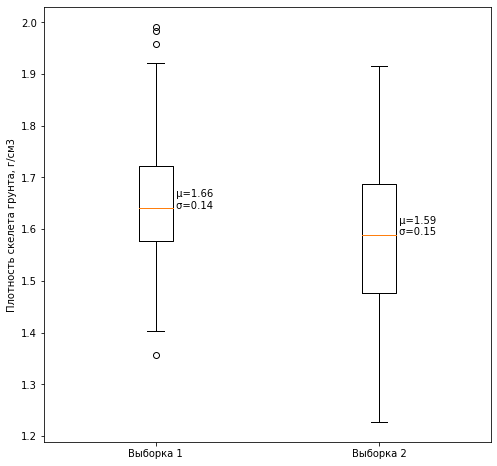
3.
. :
1. , t- ;
2. , t- .
.
1.
.
H0: μ1 = μ2.
H1: μ1≠μ2.
:

: T(X1n1,X2n2)≈~St(ν), ν

ttest_ind stats.
t_st, p_val = scipy.stats.ttest_ind(sample_1, sample_2, equal_var = False)
print(f't- {round(t_st, 2)}')
print(f' t- \
(p-value) {round(p_val, 3)}')
t- 2.92
t- (p-value) 0.004
№ 1
H0 , , 0,05 ( p-value 0.004) .
.
c_m = CompareMeans(DescrStatsW(sample_1), DescrStatsW(sample_2))
print("95%% : \
[%.4f, %.4f]" % c_m.tconfint_diff(usevar='unequal'))
95% : [0.0235, 0.1228]
95% , , 5%.
2.
, ( ) ( ) . , .
H0: μ1 = μ2.
H1: μ1≠μ2.
:


: T(X1n, X2n) ~ St(n-1)
ttest_rel stats.
t_st, p_val = stats.ttest_rel(sample_1, sample_2)
print(f't- {round(t_st, 2)}')
print(f' t- \
(p-value) {round(p_val, 3)}')
t- 2.79
t- (p-value) 0.007
№ 2
H0 , , 0,05 ( p-value 0.007).
明確にするために、これらのサンプルの平均間の間隔も推定しましょう。
print("95%% confidence interval: [%.4f, %.4f]"
% DescrStatsW(sample_1 - sample_2).tconfint_mean())
95% 信頼区間: [0.0208, 0.1255]
ゼロは考慮された 95% 信頼区間内にないため、考慮されたサンプルの平均値は異なると結論付けることができます。
5. 結果
この記事では、土木地質学の実践的な問題を解決するために Python 言語を使用する可能性を検討し、仮説をテストするために必要なサンプル サイズの問題についても調査しました。