
この記事では、予測されたクラスの不均衡を修正する方法の1つについて説明します。確率モデルを構築する方法の多くは、不均衡を修正しなくても正常に機能することを明確にすることが重要です。ただし、確率モデルの構築に進む場合、またはクラス数が多い分類問題を検討する場合は、クラスの不均衡の問題に注意を払う価値があります。
, ́ , , , . , .
NearMiss — . ́ . , .
. pip cmd:
pip install pandas
pip install numpy
pip install sklearn
pip install imblearn
, - -.
import pandas as pd
import numpy as np
df = pd.read_csv('online_shoppers_intention.csv')
df.shape
(12330, 18)
«Revenue» 2 : True ( ) False ( ). , .
df['Revenue'].value_counts()
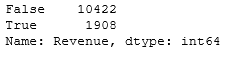
, , 85% 15%.
:
Y = df['Revenue']
X = df.drop('Revenue', axis = 1)
feature_names = X.columns
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.3, random_state = 97)
:
print(' X_train: ', X_train.shape)
print(' Y_train: ', Y_train.shape)
print(' X_test: ', X_test.shape)
print(' Y_test: ', Y_test.shape)

.
from sklearn.linear_model import LogisticRegression
lregress1 = LogisticRegression()
lregress1.fit(X_train, Y_train.ravel())
prediction = lregress1.predict(X_test)
print(classification_report(Y_test, prediction))
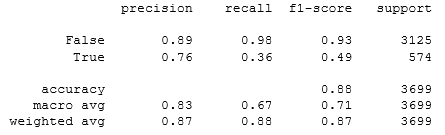
, 88%. «recall» , . , , .
NearMiss :
print(' - True: {}'.format(sum(y_train == True)))
print(' - False: {}'.format(sum(y_train == False)))
True: 1334
False: 7297
.
from imblearn.under_sampling import NearMiss
nm = NearMiss()
X_train_miss, Y_train_miss = nm.fit_resample(X_train, Y_train.ravel())
print(' - True: {}'.format(sum(Y_train_miss == True)))
print(' - False: {}'.format(sum(Y_train_miss == False)))
True: 1334
False: 1334
メソッドがクラスを平準化し、支配階級の次元を減らしていることがわかります。ロジスティック回帰を使用して、主な分類指標を含むレポートを表示してみましょう。
lregress2 = LogisticRegression()
lregress2.fit(X_train_miss, Y_train_miss.ravel())
prediction = lregress2.predict(X_test)
print(classification_report(Y_test, prediction))

少数派のレビューの価値は84%に上昇しました。しかし、より大きなクラスのサンプルが大幅に減少したため、モデルの精度は61%に低下しました。したがって、このメソッドはクラスの不均衡に対処するのに本当に役立ちました。