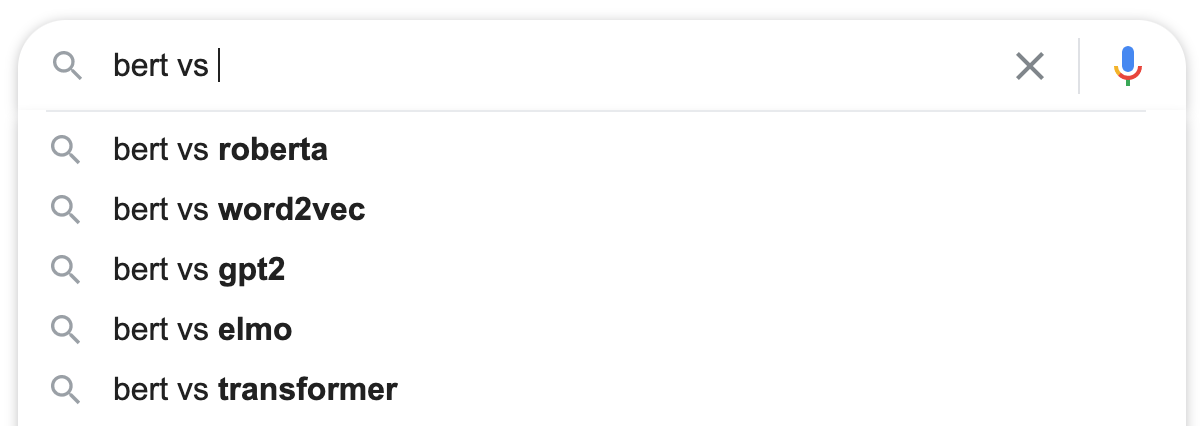
検索した単語の後に「vs」と入力すると、偶然
に起こりました。
結局のところ、これは大きな問題です。これは、何かの代替案を探すときに、多くの時間を節約できるテクニックです。
この手法を使用してテクノロジー、特定の開発、および概念について理解したい情報を見つける場合に、この手法がうまく機能する3つの理由がわかります。
- 新しいものを学ぶための最良の方法は、それがどのように、新しいか、すでに知られているものに似ているか、または新しいことが既知のものとどのように異なるかを見つけることです。たとえば、「vs」の後に表示される文のリストでは、「まあ、探しているものがこのように見えることはわかっています。もう慣れている」と言うことができます。
- — . , , .
- «vs» — , Google , - -. «or», - -. , «or», Google , - .
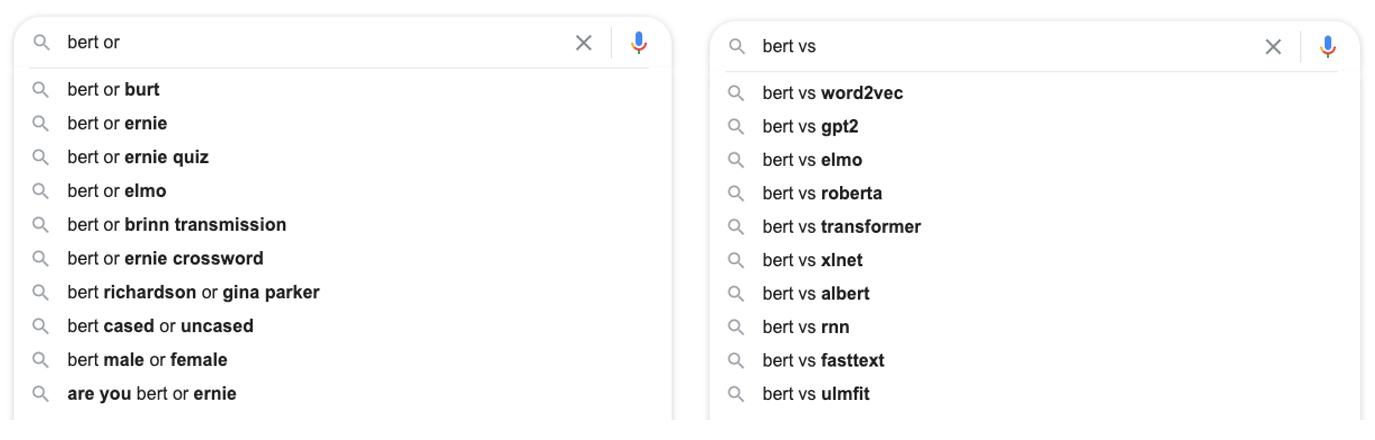
バートまたはリクエストを処理するとき、Googleはセサミストリートに関する提案を行います。「bert vs」というクエリは、Google BERTに関するヒントを与えて
くれました。「vs」と入力した後にGoogleが提案した単語を使用して検索し、その後に「vs」を追加するとどうなりますか?これを数回繰り返すとどうなりますか?その場合は、関連するクエリの優れたネットワークグラフを取得できます。
たとえば、次のようになります。
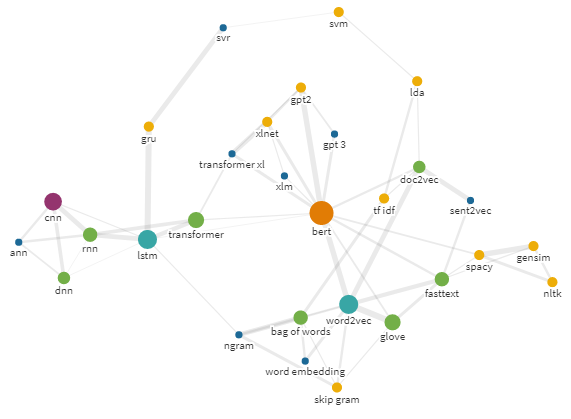
半径25のbertクエリの自我グラフ
これは、このようなエンティティの相互関係を反映する技術、開発、またはアイデアのメンタルマップを作成するための非常に便利な手法です。
このようなグラフを作成する方法を説明します。
Googleからの「vs」データの収集の自動化
これは、Googleからクエリを完了するためのGoogleからの提案をXML形式で取得するために使用できるリンクです。この機能は、一般的な使用を目的としたAPIのようには見えないため、このリンクでは重すぎないはずです。
http://suggestqueries.google.com/complete/search?&output=toolbar&gl=us&hl=en&q=<search_term>
URLパラメータ
output=toolbarは、XML形式の結果に関心がありgl=us、国コードを設定しhl=en、言語を指定できることを示します。構造q=<search_term>は、オートコンプリートの結果を取得するために必要なものです。
パラメータ
glにhlは、標準の2文字の国と言語の識別子を使用します。
たとえばクエリで検索を開始して、これらすべてを試してみましょう
tensorflow。
作業の最初のステップは、クエリを説明する次の構造を使用して、指定されたURLを参照することです
q=tensorflow%20vs%20。リンク全体は次のようになります。
http://suggestqueries.google.com/complete/search?&output=toolbar&gl=us&hl=en&q=tensorflow%20vs%20
それに応じて、XMLデータを受け取ります。
XMLをどうするか
次に、特定の一連の基準に対してオートコンプリートの結果を確認する必要があります。私たちに合ったもので、私たちは働き続けます。

得られた結果の検証
私は、結果を検証するときに、次の基準を使用しました。
- 推奨される検索クエリには、元のクエリテキスト(つまり-
tensorflow)を含めないでください。 - 推奨には、以前は適切であると判明したリクエスト(たとえば-
pytorch)を含めないでください。 - 推奨には複数の「対」の単語を含めないでください。
- 5つの一致する検索が見つかると、残りはすべて考慮されなくなります。
これは、Googleから受け取った検索クエリを完了するための推奨事項のリストを「クリーンアップ」する方法の1つにすぎません。さらに、1つの単語だけで構成される推奨事項のみをリストから選択することの利点を時々見ますが、この手法の使用は特定の状況ごとに異なります。
したがって、この一連の基準を使用すると、次の結果のうち5つが得られ、それぞれに特定の重みが割り当てられます。
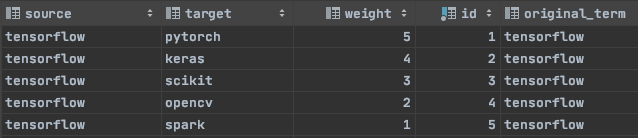
5件の結果
次の反復
次に、見つかった5つの推奨事項に対して、最初の検索クエリと同じ処理が行われます。これらは「vs」という単語を使用してAPIに渡され、再び上記の基準を満たす5つのオートコンプリート結果が選択されます。上記のリストのこのような処理の結果は次のとおりです。

すでに見つかった単語のオートコンプリート結果の検索
まだ調べられていない列の単語を調べることにより、このプロセスを続行でき
targetます。
この単語検索を十分に繰り返し実行すると、クエリと重みに関する情報を含むかなり大きなテーブルが得られます。このデータはグラフの視覚化に適しています。
自我グラフ
記事の冒頭で紹介したネットワークグラフは、いわゆるエゴグラフであり、この例ではクエリ用に作成されています
tensorflow。エゴグラフはグラフであり、そのすべてのノードはノードからある程度の距離にありますtensorflow。この距離は、指定された距離を超えてはなりません。
ノード間の距離はどのように決定されますか?
最初に完成したグラフを見てみましょう。

半径22のテンソルフロークエリのエゴグラフは
、クエリ
Aを接続するエッジの重みであり、Bすでにわかっています。これは、補完リストからの推奨のランクで、1から5まで変化します。グラフを無方向にするために、2方向(つまり、AkからB、およびそのようなリンクがある場合はBkからA)に向かう頂点間のリンクの重みを追加できます。...これにより、1〜10の範囲のエッジの重みが得られます。
したがって、エッジの長さ(距離)は、次の式を使用して計算されます。
11 — 。ここでは、最大エッジウェイトが10であるため、11を選択しました(両方の推奨事項が互いのオートコンプリートリストの最上部に表示される場合、エッジはそのウェイトになります)。その結果、リクエスト間の最小距離は1になります。
グラフ頂点のサイズ(サイズ)と色(カラー)は、対応するリクエストが推奨事項のリストに表示されるケースの数(カウント)によって決まります。その結果、ピークが大きいほど、それが表す概念が重要になることがわかります。
問題のエゴグラフの半径は22です。これは、22
tensorflowを超えない距離を通過することで、上から各リクエストに到達できることを意味します。グラフの半径を50に増やした場合にどうなるかを見てみましょう。

半径50とtensorflowクエリの自我のグラフは、
それは面白い判明しました!このグラフには、人工知能で働く誰もが知る必要のある基本的なテクノロジーのほとんどが含まれています。これらのテクノロジーの名前は論理的にグループ化されています。
そして、これらすべてが単一のキーワードに基づいて構築されています。
そのようなグラフを描く方法は?
私はオンラインの繁栄ツールを使ってそのようなグラフを描きました。
このサービスでは、シンプルなインターフェースを使用してネットワークグラフやその他の図を作成できます。エゴグラフの作成に興味がある人には、一見の価値があると思います。
与えられた半径で自我グラフを作成する方法は?
Pythonパッケージを使用して、指定した半径でエゴグラフを作成できます
networkx。とても便利な機能ですego_graph。グラフの半径は、この関数を呼び出すときに指定されます。
import networkx as nx
#
#nodes = [('tensorflow', {'count': 13}),
# ('pytorch', {'count': 6}),
# ('keras', {'count': 6}),
# ('scikit', {'count': 2}),
# ('opencv', {'count': 5}),
# ('spark', {'count': 13}), ...]
#edges = [('pytorch', 'tensorflow', {'weight': 10, 'distance': 1}),
# ('keras', 'tensorflow', {'weight': 9, 'distance': 2}),
# ('scikit', 'tensorflow', {'weight': 8, 'distance': 3}),
# ('opencv', 'tensorflow', {'weight': 7, 'distance': 4}),
# ('spark', 'tensorflow', {'weight': 1, 'distance': 10}), ...]
#
G=nx.Graph()
G.add_nodes_from(nodes)
G.add_edges_from(edges)
# - 'tensorflow'
EG = nx.ego_graph(G, 'tensorflow', distance = 'distance', radius = 22)
#
subgraphs = nx.algorithms.connectivity.edge_kcomponents.k_edge_subgraphs(EG, k = 3)
# , 'tensorflow'
for s in subgraphs:
if 'tensorflow' in s:
break
pruned_EG = EG.subgraph(s)
ego_nodes = pruned_EG.nodes()
ego_edges = pruned_EG.edges()
さらに、ここでは別の関数を使用しました-
k_edge_subgraphs。これは、ニーズを満たさない結果を削除するために使用されます。
たとえば
storm、リアルタイム分散コンピューティング用のオープンソースフレームワークです。しかし、これはマーベルユニバースのキャラクターでもあります。 Googleに「嵐vs」と入力すると、どの検索候補が「勝つ」と思いますか。
この関数
k_edge_subgraphsは、実行するkアクションまたは少ないアクションでは分割できない頂点のグループを検索します。それが判明したように、パラメータの値k=2とは、ここにも自分自身を示してk=3。結局、それらが属するサブグラフだけが残りtensorflowます。これにより、検索を開始した場所から離れすぎたり、離れすぎたりすることがなくなります。
人生における自我グラフの使用
例cから離れ
tensorflowて、別の自我グラフを見てみましょう。今回-私に興味がある何かに捧げられたグラフ。これは「スペインのゲーム」と呼ばれるチェスのオープニング(Ruy Lopezのチェスのオープニング)です。
▍チェスの開口部の研究

「スペインのゲーム」(ruy lopez)の研究
私たちの方法により、チェスの研究者に役立つ最も一般的なオープニングアイデアをすばやく見つけることができました。
次に、エゴグラフを使用する他の例を見てみましょう。
▍健康的な栄養
キャベツ!おいしい!
しかし、美しくて比類のないキャベツを何か他のもので置き換えたいという欲求がある場合はどうでしょうか。キャベツ(
kale)を中心に構築された自我グラフは、これを支援します。
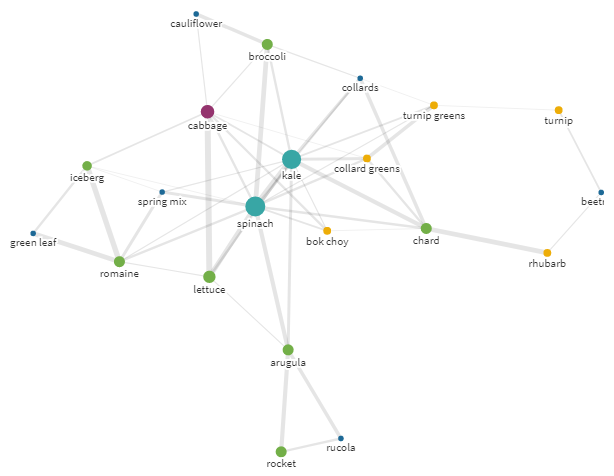
半径25のケールクエリの自我グラフ
▍犬を買う
犬がたくさんいるので、時間もほとんどありません...犬が必要です。しかし、どれ?たぶんプードル(
poodle)のようなものでしょうか?
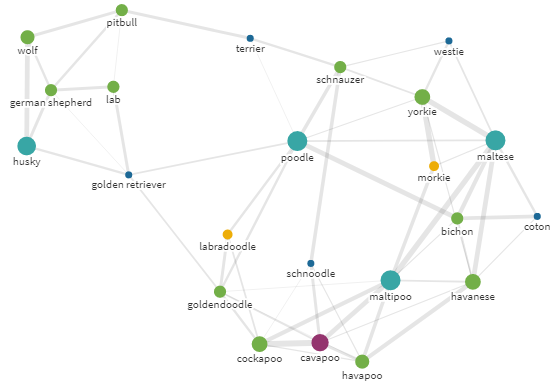
半径18のプードルクエリの自我グラフ
love愛を求めて
犬とキャベツは何も変わらない?他の半分を見つける必要がありますか?もしそうなら、これはこれを助けることができる小さいが非常に自給自足のエゴグラフです。

リクエストコーヒーの自我グラフは半径18のベーグルと出会います
d出会い系アプリが役に立たなかった場合はどうなりますか?
出会い系のアプリが役に立たない場合は、アプリをぶら下げるのではなく、シリーズを見て、キャベツの味(または最近発見されたルッコラの味)のアイスクリームを用意してください。「オフィス」シリーズ(確かにイギリスでのワンショット)が好きなら、他のシリーズも好きかもしれません。

半径25のオフィスを照会する自我グラフ
概要
これで、Google検索での「vs」という単語の使用と自我グラフについての私の話は終わりです。これらすべてが、愛、良質な犬、健康食品を探す上で、少なくとも少しでも役立つことを願っています。
インターネットを検索するときに珍しいトリックを使用しますか?
