気晴らしを有用な情報から分離するためのヒント

統計学の入門コースを受講すると、データを使用してインスピレーションやテスト理論を見つけることができますが、両方には使えないことがわかります。何故ですか?
人々はすべてのパターンを見つけるのが得意です。実際にどのパターンが存在し、どのパターンが発明されているかを自分で決定します。私たちは、ポテトチップスでエルビスの顔を見つける生き物です。パターンを概念と同一視したい場合は、3種類のパターンがあることに注意してください。
- データセットとそれ以降の両方に存在するパターン。
- データセットにのみ存在するパターン。
- あなたの想像力にのみ存在するパターン(アポフェニア)。
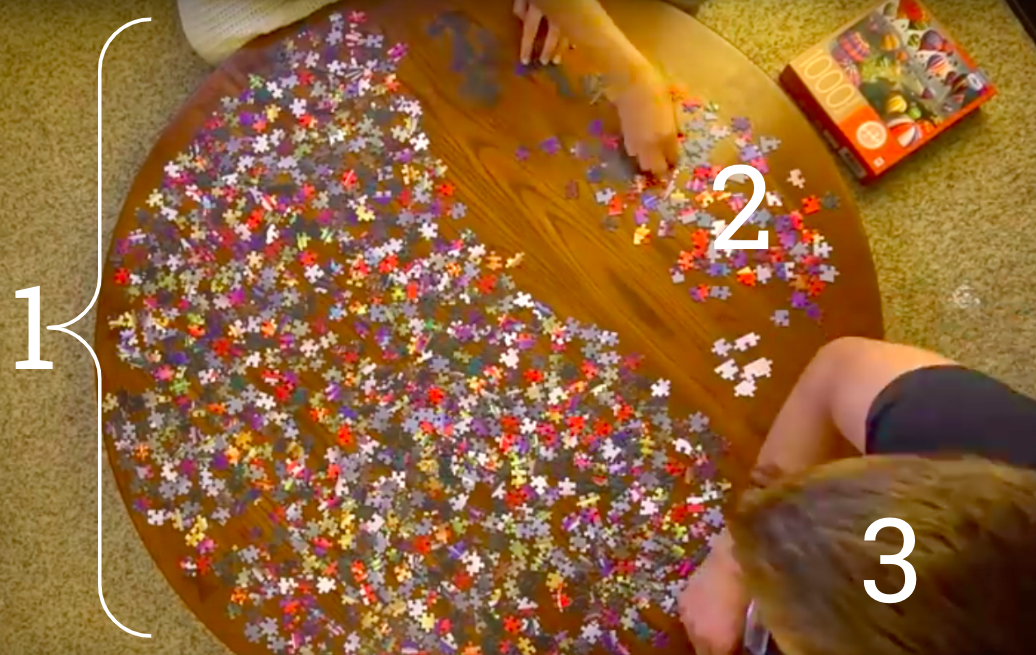
データパターンは、(1)関心のある母集団全体、(2)サンプルのみ、または(3)頭部のみに存在できます。
どのようなパターンとデータパターンが役立ちますか?それはあなたの目標に依存します。
インスピレーション
純粋なインスピレーションが必要な場合、データは不思議に機能します。アポフェニア(無関係なものの間の接続と意味を誤って認識する人間の傾向)でさえ、クリエイティブな作品を最大限に活用できます。創造性には正しい答えがないので、あなたがしなければならないのはあなたのデータを見てそれをいじるだけです。追加のボーナスとして、あまりにも多くの時間を浪費しないようにしてください(あなたのものまたは関係者のもの)。
事実
あなたの政府があなたから税金を徴収したいとき、それはその年のあなたの財務データを超える価値を無視することはできません。IRSは、あなたが支払うべき金額について事実上の決定を下す必要があり、その決定を下す主な方法は、昨年のデータを分析することです。つまり、データを確認して式を適用します。この場合、利用可能なデータに関連付けられた純粋に記述的な分析について話している。最初の2種類のパターンのいずれもこれに適しています。
既存のデータに関連付けられた記述的分析。
(私は財務諸表を隠したことはありませんが、大学院で学んだデータ計算方法を使用して統計的に税金を支払い、それらを置き換える場合、米国政府は興奮しないと思います。)
不確実性ソリューション
時には、事実が希望と一致しないことがあります。決定に必要なすべての情報がない場合は、不確実性をナビゲートして、合理的な行動方針を選択する必要があります。
これがまさに統計とは何か、不確実性に直面してあなたの心を変える方法の科学です。ゲームはイカロスのような未知のものに飛び込むことであり...そして鍛冶屋に打ち砕かれるのではありません。
これがデータサイエンスの主なタスクです。データを調査した結果、どのように*知らされないようにするか*
この崖から飛び降りる前に、現実の限られたビューで見つけたパターンが実際にビューの外で機能することを期待することをお勧めします。言い換えれば、テンプレートはあなたに役立つように一般化する必要があります。

3つのタイプのパターンのうち、不確実性の下で意思決定を行う場合、最初の(一般化された)パターンのみが安全です。残念ながら、データには他のタイプのパターンが見られます。これは、データサイエンスの中心にある大きな問題です。データ探索の結果として気づきを失わないようにする方法です。
汎化
データで役に立たないパターンを見つけることが純粋に人間の特権だと思うなら、もう一度考えてみてください!注意しないと、車は同じ愚かさを自動的に実行できます。
機械学習とAIの要点は、新しい状況を適切に一般化することです。
機械学習は、データのパターンをアルゴリズムで検索し、それらを使用して完全に新しいデータに正しく応答することを含む、多くの同様の決定を行うためのアプローチです。機械学習とAIの専門用語では、一般化とは、モデルがこれまでにないデータでうまく機能する能力を指します。古いデータでしか機能しないテンプレートベースのモデルのポイントは何ですか?これを行うには、検索テーブルを使用するだけです。機械学習とAIの全体的なポイントは、新しい状況で適切な一般化を行うことです。

これが、リストの最初のタイプのパターンが機械学習に適している唯一のパターンである理由です。この種のデータは信号であり、他のすべては単なるノイズです(古いデータにのみ存在し、一般化可能なモデルの作成を妨げる要因)。
シグナル:データセットとそれ以降の両方に存在するパターン。
ノイズ:データセットにのみ存在するパターン。
基本的に、新しいデータではなく古いノイズを処理するソリューションを取得することは、機械学習でのオーバーフィッティングと呼ばれるものです(この用語は、お気に入りの空想的な発音と同じトーンで発音します)。機械学習では、ほとんどすべてが過剰適合を回避するために行われます。
では、どのような*この*サンプルを参照するのでしょうか?
あなた(またはあなたのコンピュータ)があなたのデータから抽出したパターンがあなたの想像の外に存在すると仮定します-それはどのカテゴリーに属していますか?これは、関心のある集合体に存在する実際の現象(シグナル)ですか、それともデータセットの機能(ノイズ)ですか?データを操作するときに見つかったパターンのタイプをどのように判断しますか?
利用可能なすべてのデータを調査すると、これを行うことができなくなります。あなたは困惑し、あなたのテンプレートが他の場所に存在するかどうかわかりません。統計的仮説をテストすることに関するすべてのレトリックは、予期しないことに依存し、すでに知られているパターンがあなたを驚かせるふりをするのは悪い味です(実際、これはハッキングです)。

これは、ウサギの形をした雲を見て、すべての雲がウサギのように見えるかどうかを確認するようなものです...同じ雲を見てください。理論をテストするには新しい雲が必要になることを理解してほしい。
理論や質問の作成に使用されたデータは、同じ理論の検証には使用できません。
1つのクラウドにしかアクセスできないことがわかっている場合はどうしますか?パントリーで瞑想している、それがそうです。データを見る前に質問してください。
数学は常識に反しません。
ここで私たちは最も悲しい結論に達しました。データセットをインスピレーションに使用する場合、それを再び使用して、インスピレーションを得た理論を徹底的にテストすることはできません(数学の柔術のトリックがどんなものであっても、数学は常識に反することはありません)。
難しい選択
ポイントはあなたが選択をしなければならないということです!データセットが1つしかない場合は、「私はクローゼットの中で瞑想し、統計的検定のための仮説を立ててから、穏やかに厳密なアプローチをとります。それで、真剣に取り組むことができますか?」あるいは、インスピレーションを得るためにデータを収集しているだけで、自分をだましているかもしれないことに気づき、「感じます」、「インスピレーションを与える」、「わからない」などのフレーズを使用する必要があることを覚えていますか?」難しい選択です!
または、ケーキを2回食べる方法はありますか?問題は、データセットが1つしかなく、複数のデータセットが必要なことです。そして、あなたが十分なデータを持っているなら、私はそれをトリックにしています。爆破。きみの。脳。

トリッキーなトリック
データサイエンスで成功するには、データを分割して1つのデータセットを(少なくとも)2つに変換します。次に、1つをインスピレーションに、もう1つを厳密なテストに使用します。元々あなたに影響を与えたパターンが、自分の意見に影響を与えないデータに存在する場合、このパターンは、データを取得する猫のトレイで機能する一般的なルールである可能性があります。
同じ現象が両方のデータセットで発生する場合、これはそのデータセットのすべてのソースに適用される一般的なルールである可能性があります。
RSChD!
探求のない人生は人生ではないので、ここに生きるための4つの言葉があります:いまいましいデータを共有してください。
誰もがデータを共有すれば、世界はより良い場所になるでしょう。より良い答え(統計のおかげで)とより良い質問(分析のおかげで)があるでしょう。人々がデータ共有を必須の習慣と見なさない唯一の理由は、前世紀にはそれが非常に少ない余裕のある贅沢であったためです。データセットは非常に小さいため、それらを分離しようとすると、おそらく何も残っていません。
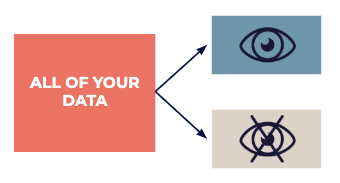
データを、インスピレーションに使用できる公開されている探索データセットと、エキスパートが探索フェーズで見つかった「推測」を特定するために使用するテストデータセットに分割します。
一部のプロジェクトは、特に医学研究でまだこの問題に直面しています(以前は神経科学でしたので、私は小さなデータセットの操作の複雑さに大きな敬意を払っています)が、エンジニアの雇用に必要なデータがたくさんあります。それらを移動するように手配するためだけに...あなたの言い訳は何ですか?データを共有して、無駄を省いてください。
データを共有する習慣がない場合、20世紀に行き詰まることがあります。
多くのデータがあり、それらのセットが分離されていない場合、古いパラダイムに存在します。このパラダイムに存在する人々は、古風な考え方に同意し、時間内にさらに進むことを拒否しました。
機械学習はデータ共有の子孫です
結局のところ、アイデアは単純です。1つのデータセットを使用して理論を形成し、そのデータセットを理解してから、魔法をかけます-まったく新しいデータセットでアイデアを証明します。
データ共有は、より健全なデータカルチャーのための最も簡単な高速ソリューションです。
このようにして、統計的手法を安全に使用し、過剰適合を防ぐことができます。実際、機械学習の歴史はデータ共有の歴史です。
データサイエンスで最高のアイデアを使用する方法
データサイエンスの最良のアイデアを活用するために必要なことは、テストデータを詮索好きな目の届かないところに保管し、その後、アナリストに夢中になることだけです。
データサイエンスで成功するには、データを分割して1つのデータセットを(少なくとも)2つに変換します。
彼らがあなたが学んだことを超えてあなたに有益な情報をもたらしたと思うとき、あなたの発見をテストするためにテストデータの秘密の隠し場所を使ってください。

SkillFactoryの有料オンラインコースを受講して、知名度の高い職業をゼロから、またはスキルと給与をレベルアップする方法の詳細をご覧ください。
- 機械学習コース(12週間)
- データサイエンスの専門職をゼロからトレーニングする(12か月)
- (9 )
- «Python -» (9 )