に関する単一のPython文字列認知歪みを伴うクールで完全にインタラクティブなチャートを作成する方法は、人々が犠牲になる多くの有害な認知バイアスの1つです。これは、時間を費やし続けるという私たちの傾向を指しますそして、失われた原因へのリソース。なぜなら、私たちはすでに追われて-溺死して-追跡に多くの時間を費やしたからです。低コストの誤謬は、私たちが必要以上に悪い仕事にとどまり、うまくいかないことがはっきりしている場合でもプロジェクトに怠惰に取り組むことに当てはまり、そうです、退屈で古いプロットライブラリ-matplotlib-より効率的でインタラクティブな、より魅力的な代替手段。
過去数か月の間に、私がmatplotlibを使用している唯一の理由は、複雑な構文の学習に何百時間も費やしたことが原因であることに気付きました。これらの複雑さにより、StackOverflowで日付をフォーマットする方法や2番目のY軸を追加する方法を理解するのに数時間の不満が生じます。... 幸いなことに、これはPythonでグラフをプロットする絶好の機会です。オプションを検討した後、使いやすさ、ドキュメント、機能性の点で明らかな勝者は陰謀です。この記事では、plotlyについて詳しく説明します。多くの場合、1行のコードで、より短時間でより良いグラフを作成する方法を学びます。
この記事の すべてのコードはGitHubで入手できます。すべてのグラフはインタラクティブで、NBViewerで表示できます。
Plotlyの概要
Python用のplotly パッケージ-plotly.jsに基づいて構築されたオープンソースソフトウェアのライブラリであり、これはd3.jsに基づいて構築されています。Pandas DataFrameで動作するように設計されたplotlyと呼ばれるカフリンクのラッパーを使用します。つまり、スタックcufflinks> plotly> plotly.js> d3.js-これは、信じられないほどのインタラクティブなグラフィカル機能d3でPythonプログラミングの効率を上げることを意味します。
(Plotly自体はグラフィック企業ですいくつかのオープンソース製品とツールを使用しています。Pythonライブラリは無料で使用でき、オフラインで無制限のグラフを作成できるほか、オンラインで最大25のグラフを作成して世界と共有できます。)
この記事のすべての作業は、jupyter Notebookでplotly + cufflinksオフライン。plotlyとcufflinksをインストールしたら
pip install cufflinks plotly 、Jupiterで実行するために以下をインポートします。
# Standard plotly imports
import plotly.plotly as py
import plotly.graph_objs as go
from plotly.offline import iplot, init_notebook_mode
# Using plotly + cufflinks in offline mode
import cufflinks
cufflinks.go_offline(connected=True)
init_notebook_mode(connected=True)単一変数分布:ヒストグラムと箱ひげ図
単一変数プロット-1次元は分析を開始する標準的な方法であり、ヒストグラムは分布プロットをプロットするための遷移プロット(いくつかの問題はあります)です。ここでは、私の平均記事の統計情報を使用して(あなたはどのように見ることができ、ここで、独自の統計情報を取得するか、地雷を使用して、のが記事に拍手(数のインタラクティブなヒストグラムを作成してみましょう)
dfこれは、標準的なパンダのデータフレームです):
df['claps'].iplot(kind='hist', xTitle='claps',
yTitle='count', title='Claps Distribution')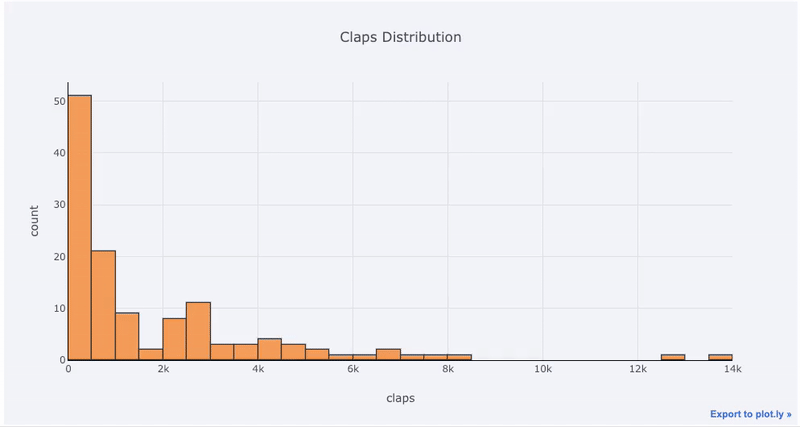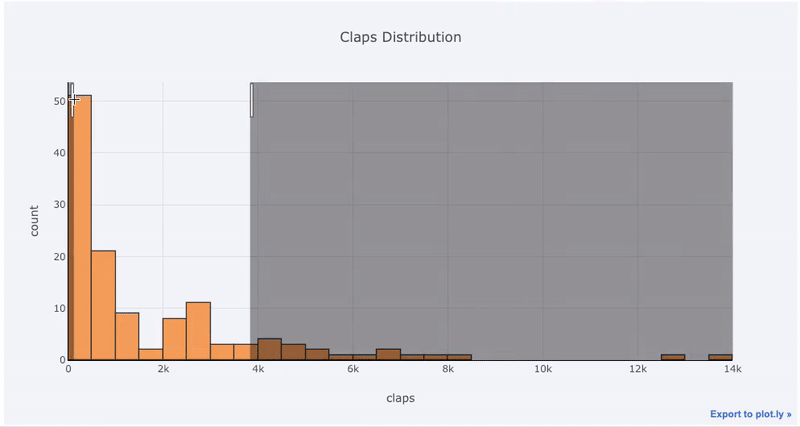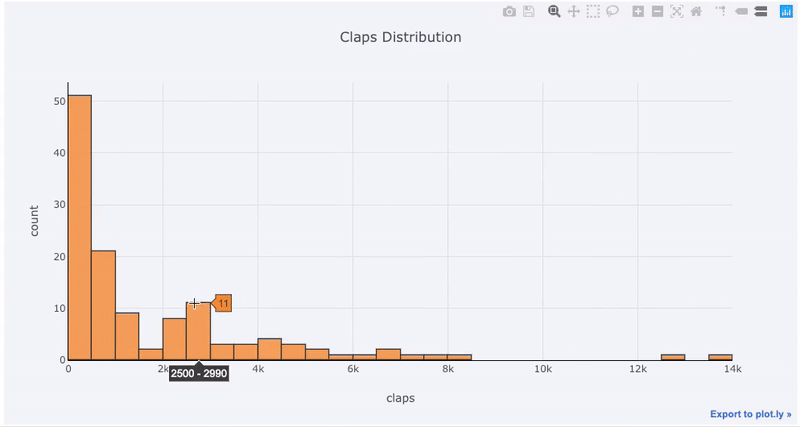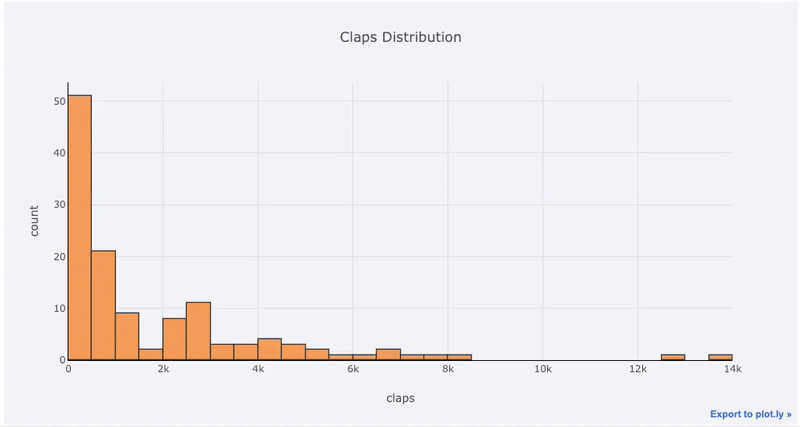
に慣れている人は
matplotlib、あと1文字(のiplot代わりにplot)を追加するだけで、はるかに美しくインタラクティブなグラフを作成できます。データをクリックして詳細情報を取得し、グラフの一部を拡大して、後で説明するように、さまざまなカテゴリを選択できます。
オーバーレイされたヒストグラムをプロットしたい場合も同様に簡単です。
df[['time_started', 'time_published']].iplot(
kind='hist',
histnorm='percent',
barmode='overlay',
xTitle='Time of Day',
yTitle='(%) of Articles',
title='Time Started and Time Published')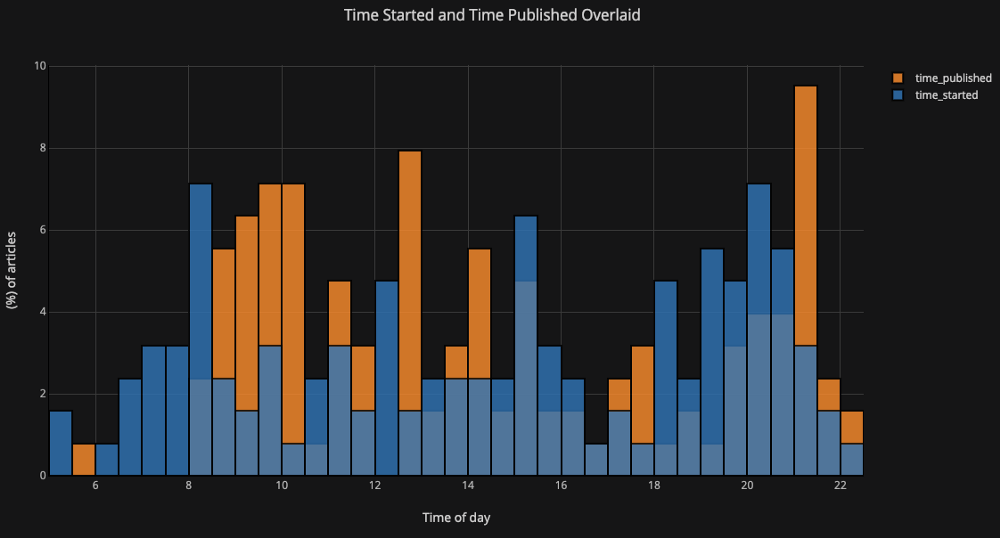
少し操作するだけで
Pandas、バープロットを作成できます。
# Resample to monthly frequency and plot
df2 = df[['view','reads','published_date']].\
set_index('published_date').\
resample('M').mean()
df2.iplot(kind='bar', xTitle='Date', yTitle='Average',
title='Monthly Average Views and Reads')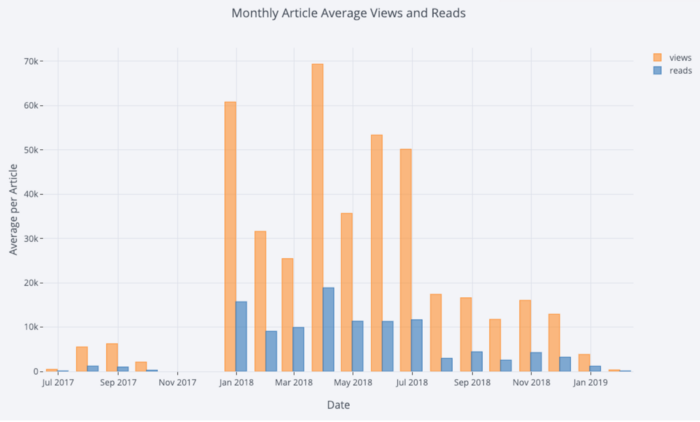
これまで見てきたように、Pandasの力とplotly + cufflinks を組み合わせることができます。パブリケーションごとにファンの分布をボックス
pivotプロットするには、を使用してからプロットします。
df.pivot(columns='publication', values='fans').iplot(
kind='box',
yTitle='fans',
title='Fans Distribution by Publication')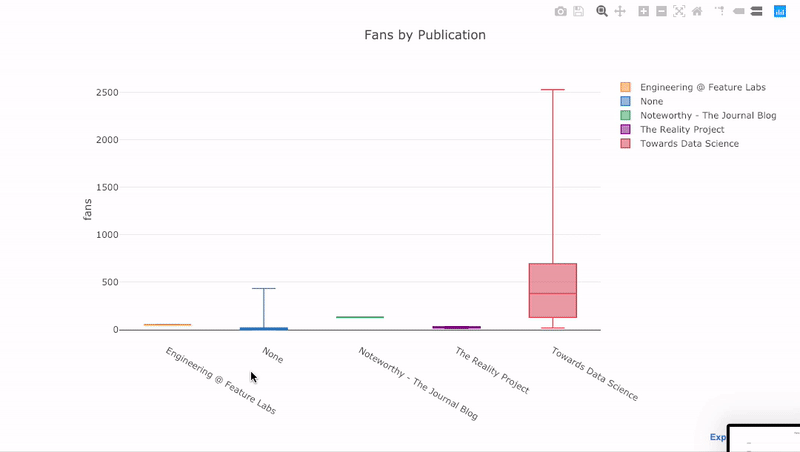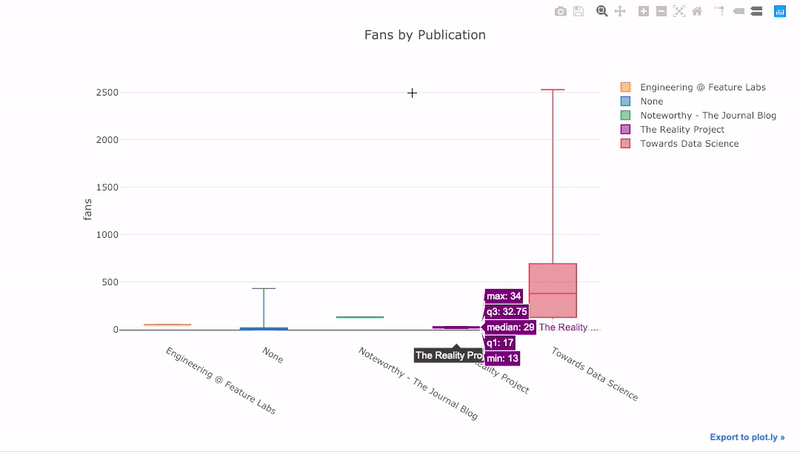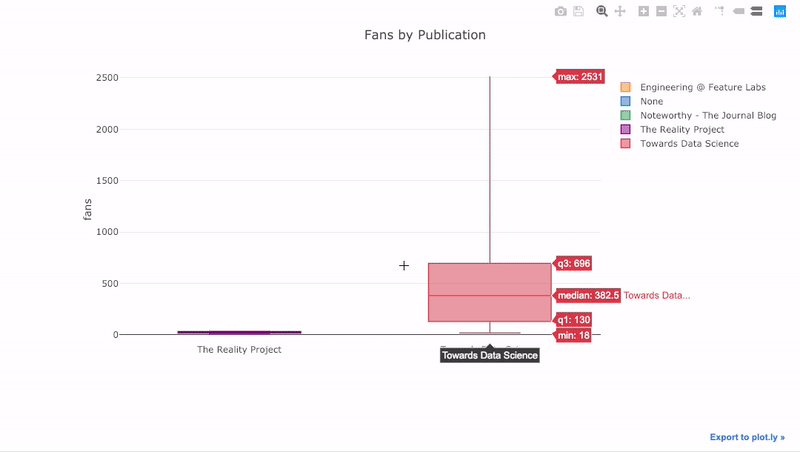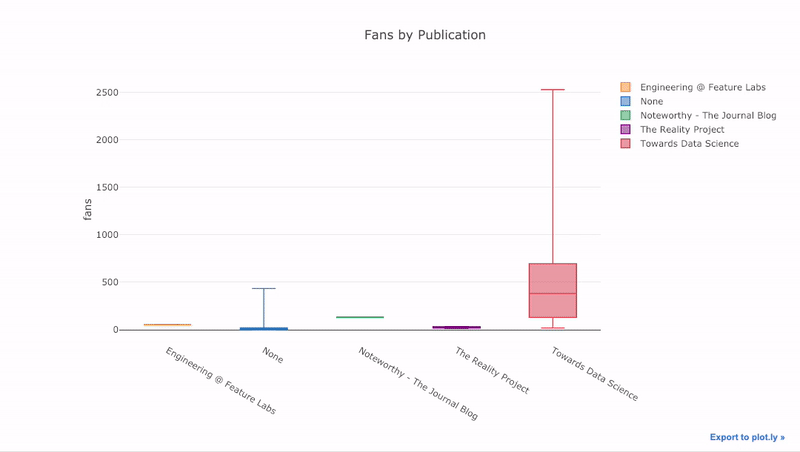
インタラクティブ機能の利点は、適切と思われるデータを探索してホストできることです。ボックスラフトには多くの情報があり、数字を見ることができなければ、そのほとんどを逃します!
散布図
散布図は、ほとんどの分析の中心です。これにより、時間の経過に伴う変数の変化、または2つ(またはそれ以上)の変数間の関係を確認できます。
時系列
実際のデータの多くには時間要素があります。幸いなことにplotly + cufflinksは時系列の視覚化を念頭に置いて設計されました。TDS記事のデータをフレーム化して、トレンドがどのように変化したかを見てみましょう。
Create a dataframe of Towards Data Science Articles
tds = df[df['publication'] == 'Towards Data Science'].\
set_index('published_date')
# Plot read time as a time series
tds[['claps', 'fans', 'title']].iplot(
y='claps', mode='lines+markers', secondary_y = 'fans',
secondary_y_title='Fans', xTitle='Date', yTitle='Claps',
text='title', title='Fans and Claps over Time')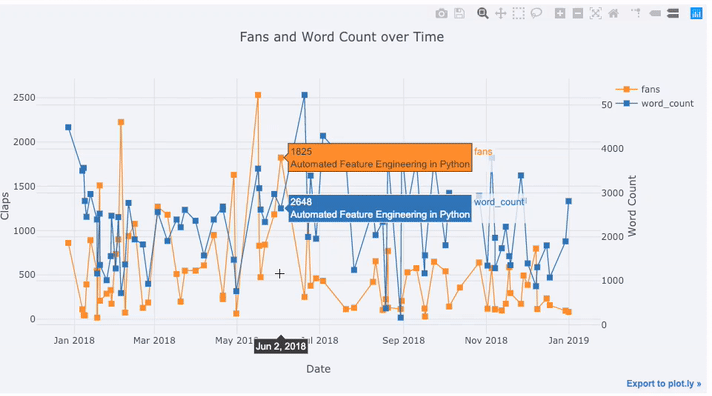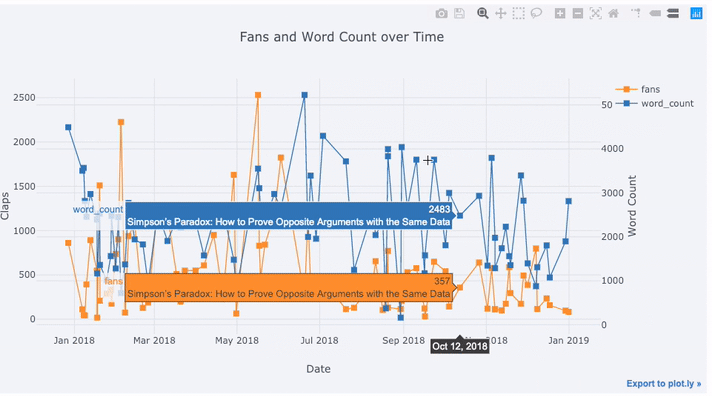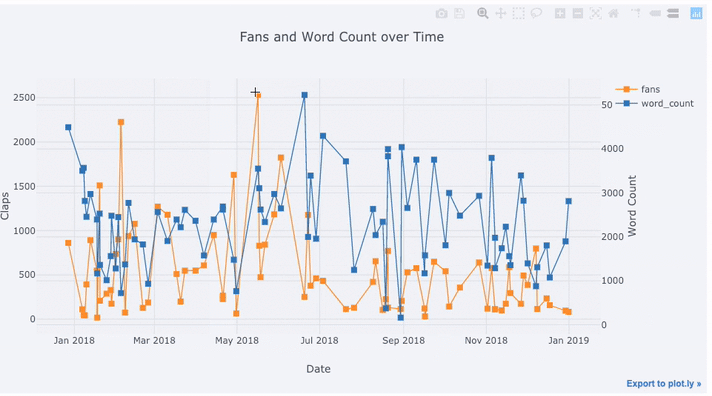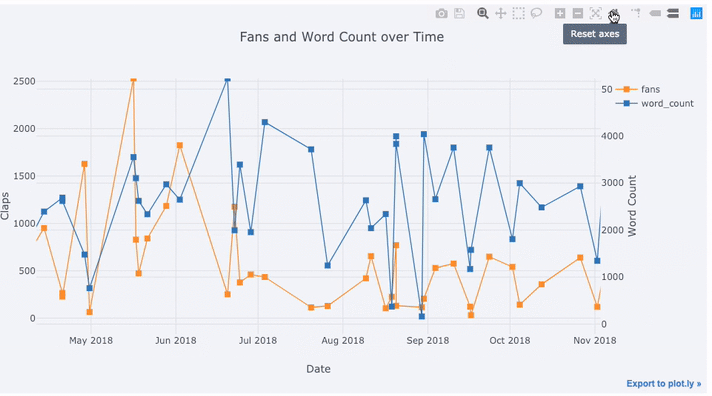
ここにはかなり多くの異なるものが表示されます。
- X軸で適切にフォーマットされた時系列を自動的に取得する
- 変数の範囲が異なるため、2番目のy軸を追加する
- ホバー時の記事タイトルの表示
詳細については、テキスト注釈を非常に簡単に追加することもできます。
tds_monthly_totals.iplot(
mode='lines+markers+text',
text=text,
y='word_count',
opacity=0.8,
xTitle='Date',
yTitle='Word Count',
title='Total Word Count by Month')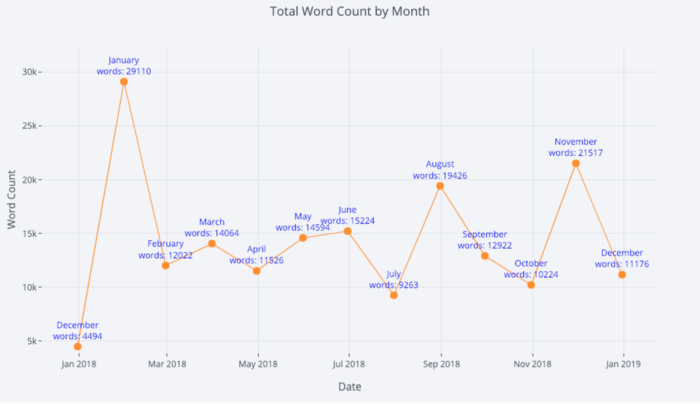
3番目のカテゴリカル変数で色付けされた2変数散布図では、次を使用します。
df.iplot(
x='read_time',
y='read_ratio',
# Specify the category
categories='publication',
xTitle='Read Time',
yTitle='Reading Percent',
title='Reading Percent vs Read Ratio by Publication')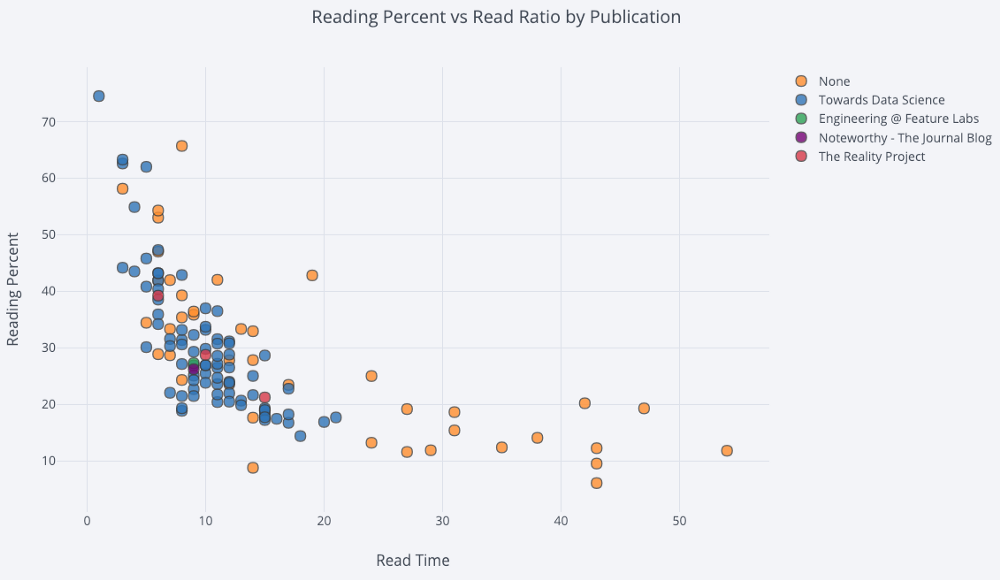
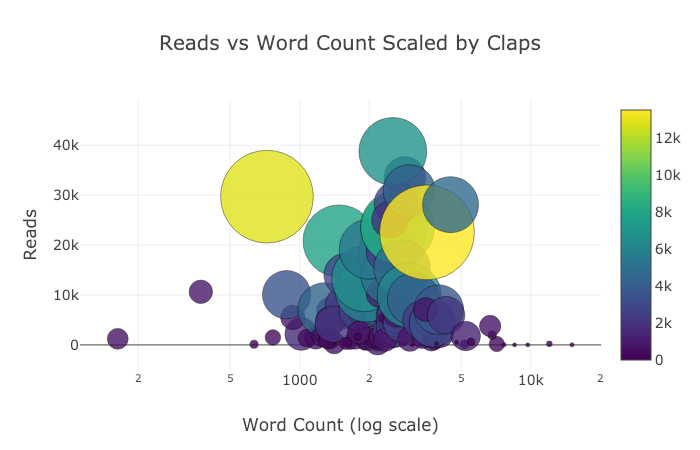
plotlyレイアウトとして指定されたログ軸を使用して(レイアウトの仕様についてはPlotlyのドキュメントを参照)、数値変数のバブルのサイズを定義することで、少し複雑にしてみましょう。
tds.iplot(
x='word_count',
y='reads',
size='read_ratio',
text=text,
mode='markers',
# Log xaxis
layout=dict(
xaxis=dict(type='log', title='Word Count'),
yaxis=dict(title='Reads'),
title='Reads vs Log Word Count Sized by Read Ratio'))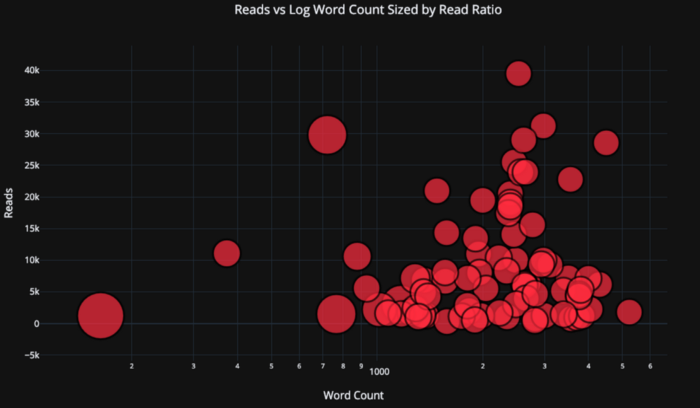
少しの作業(詳細についてはNoteBookを参照)で、1つのグラフに4つの変数(非推奨)を配置することもできます。
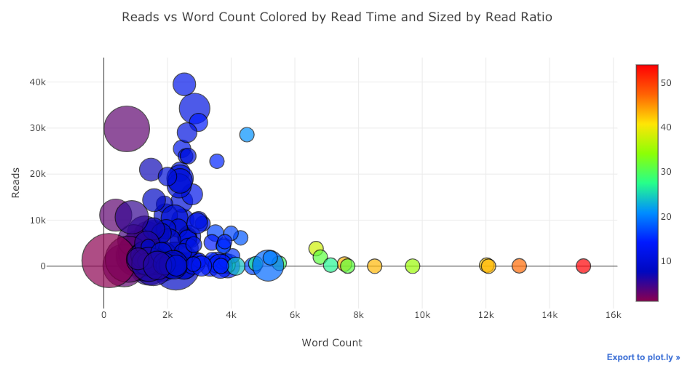
前と同じように、Pandasとplotly + cufflinksを組み合わせて、便利なグラフを作成できます。
df.pivot_table(
values='views', index='published_date',
columns='publication').cumsum().iplot(
mode='markers+lines',
size=8,
symbol=[1, 2, 3, 4, 5],
layout=dict(
xaxis=dict(title='Date'),
yaxis=dict(type='log', title='Total Views'),
title='Total Views over Time by Publication'))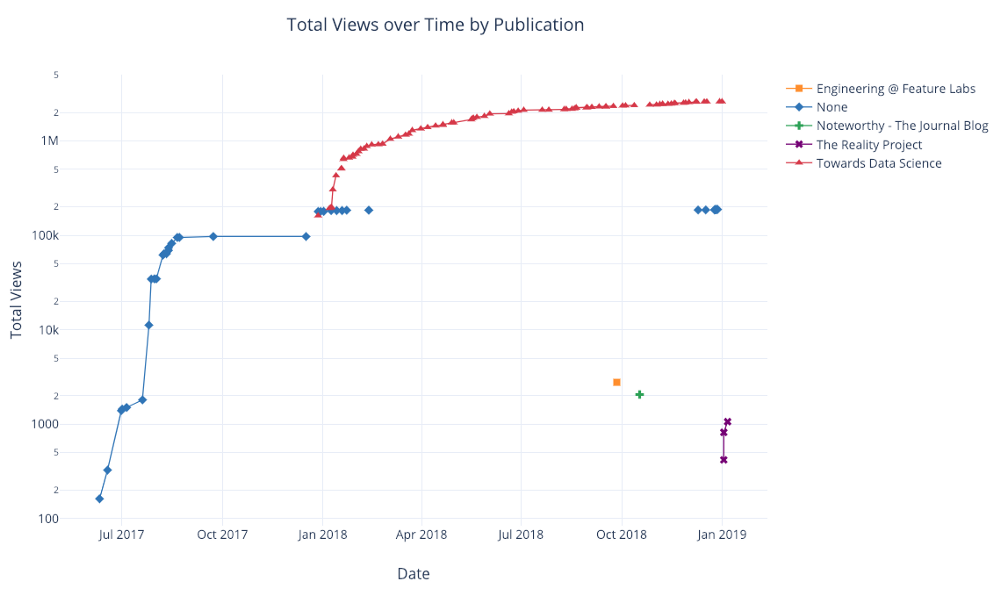
機能のその他の例については、ノートブックまたはドキュメントを参照してください。テキスト注釈、参照線、最適線をコードに1行追加するだけで、すべてのやり取りを図に追加できます。
高度なチャート
次に、おそらくあまり使用しないいくつかのグラフィックに移りますが、それは非常に印象的です。plotly figure_factoryを使用して、これらの信じられないほどのハフィックも1行で実行します。
散乱行列
多くの変数間の関係を調べたい場合、散布行列(splomとも呼ばれます)は素晴らしいオプションです。
import plotly.figure_factory as ff
figure = ff.create_scatterplotmatrix(
df[['claps', 'publication', 'views',
'read_ratio','word_count']],
diag='histogram',
index='publication')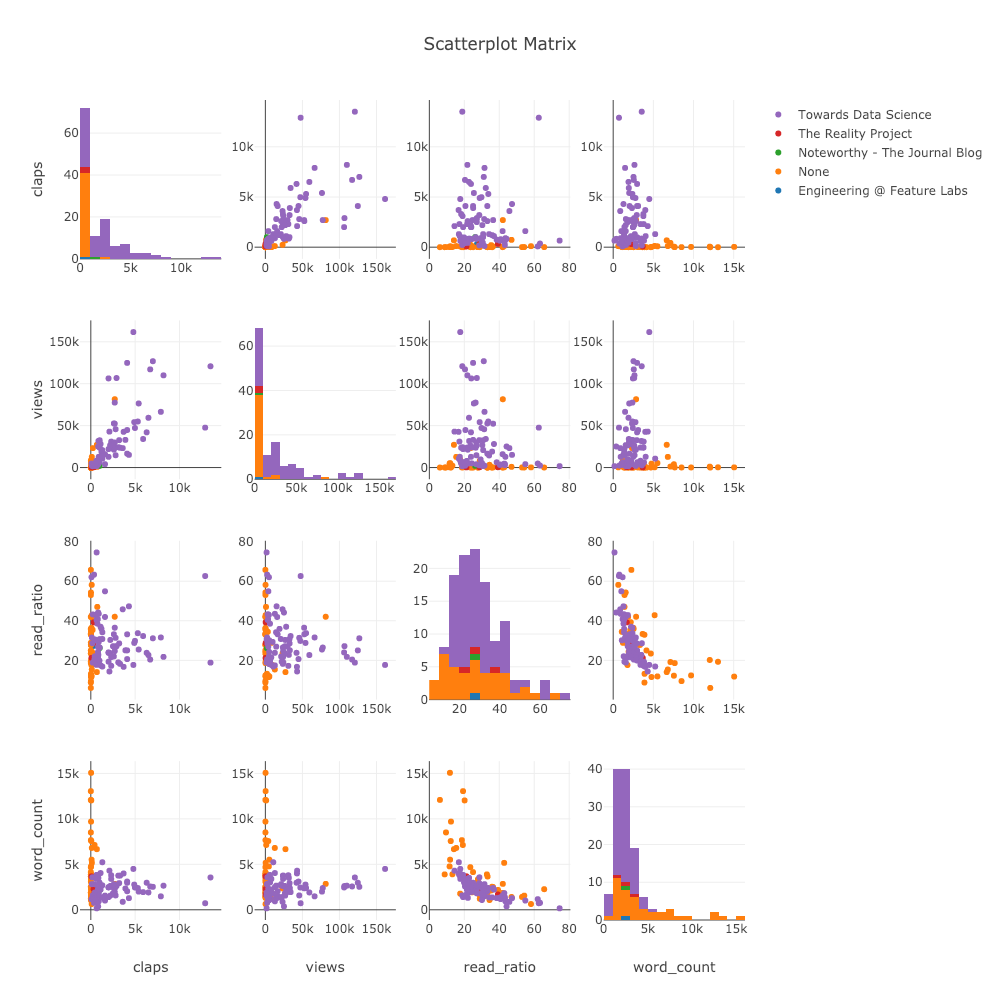
このグラフでも完全にインタラクティブなので、データを探索できます。
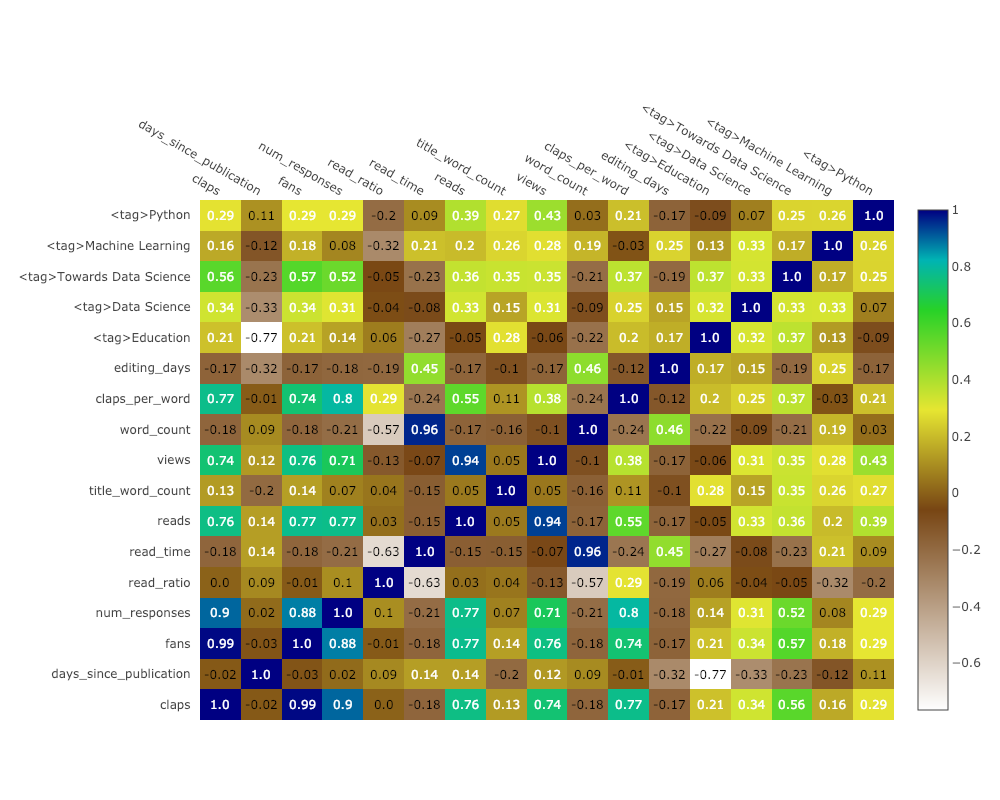
相関ヒートマップ
数値変数間の相関関係を視覚化するために、相関関係を計算してから、注釈付きヒートマップを作成します。
corrs = df.corr()
figure = ff.create_annotated_heatmap(
z=corrs.values,
x=list(corrs.columns),
y=list(corrs.index),
annotation_text=corrs.round(2).values,
showscale=True)
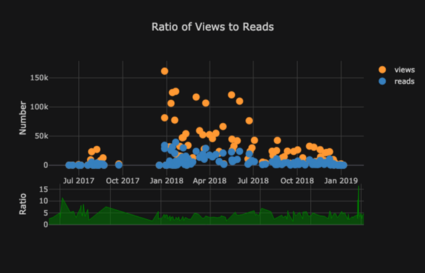
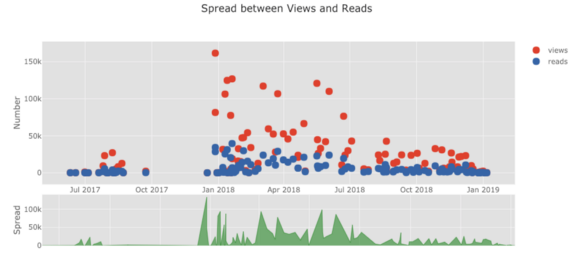
グラフのリストはどんどん続きます。カフリンクスには、まったく異なるルックアンドフィールを簡単に取得するために使用できるいくつかのテーマもあります。たとえば、以下では、「スペース」テーマに比率プロットがあり、「ggplot」にスプレッドプロットが
あります。3Dプロット(表面プロットとバブルプロット)も取得します
。これが好きな人は、円グラフを作成することもできます。
Plotly Chart Studioでの編集
NoteBook Jupiterでこれらのグラフを作成すると、「Export to plot.ly」グラフの右下隅に小さなリンクが表示されます。このリンクをクリックすると、Chart Studioに移動し、最終的なプレゼンテーション用にグラフを微調整できます。注釈を追加したり、色を指定したり、一般的にすべてをクリアして優れたグラフを作成したりできます。次に、スケジュールをインターネットで公開して、誰でも参照できるようにすることができます。
以下は、Chart Studioで調整した2つのグラフです。
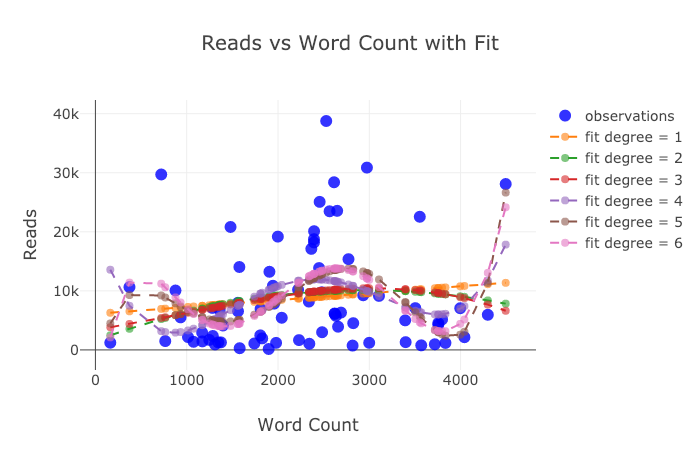
ここで述べたことにもかかわらず、ライブラリのすべての機能をまだ調べていません。さらに素晴らしいプロットについては、plotlyのドキュメントとカフリンクスのドキュメントの両方を参照することをお勧めします。
結論
過小評価されている誤解の最悪の部分は、あなたが辞めた後にどれだけの時間を無駄にしたかだけを理解していることです。幸いにも、私がmatploblibに長時間留まるという過ちを犯した今、あなたはそうする必要はありません!
プロットライブラリについて考えるとき、次のことが必要です。
- 迅速な探索のための単線グラフ
- インタラクティブなデータ置換/探索
- 必要に応じて詳細を掘り下げる機能
- 最終的なプレゼンテーションのための簡単なセットアップ
現時点では、Pythonでこれをすべて行うための最良のオプションは、陰謀です。Plotlyを使用すると、視覚化をすばやく行うことができ、双方向性を通じてデータをよりよく理解するのに役立ちます。さらに、正直なところ、グラフはデータサイエンスの最も優れた部分の1つである必要があります。他のライブラリでは、プロットは面倒な作業になりましたが、plotlyを使用すると、素晴らしい図を再び作成できるという喜びがあります。

SkillFactoryの有料オンラインコースを受講して、スキルと給与の注目の職業をゼロから取得する方法の詳細をご覧ください。
- データサイエンスの専門職をゼロからトレーニングする(12か月)
- 初心者レベルの分析職(9か月)
- 機械学習コース(12週間)
- «Python -» (9 )
- DevOps (12 )
- - (8 )