前書き
畳み込みニューラルネットワーク(CNN)RetinaNetのアーキテクチャは、4つの主要な部分で構成され、それぞれに独自の目的があります。a
)バックボーン-入力画像から特徴を抽出するために使用される主要な(基本)ネットワーク。ネットワークのこの部分は可変であり、ResNet、VGG、EfficientNetなどの分類ニューラルネットワークが含まれる場合があります。
b)機能ピラミッドネット(FPN)-ピラミッドの形で構築された畳み込みニューラルネットワークで、ネットワークの下位レベルと上位レベルの機能マップの利点を組み合わせる役割を果たします。後者は反対です。
c)分類サブネット-FPNからオブジェクトクラスに関する情報を抽出し、分類問題を解決するサブネット。
d)回帰サブネット-FPNから画像内のオブジェクトの座標に関する情報を抽出し、回帰問題を解決するサブネット。
図では 1は、ResNetニューラルネットワークをバックボーンとするRetinaNetのアーキテクチャを示しています。
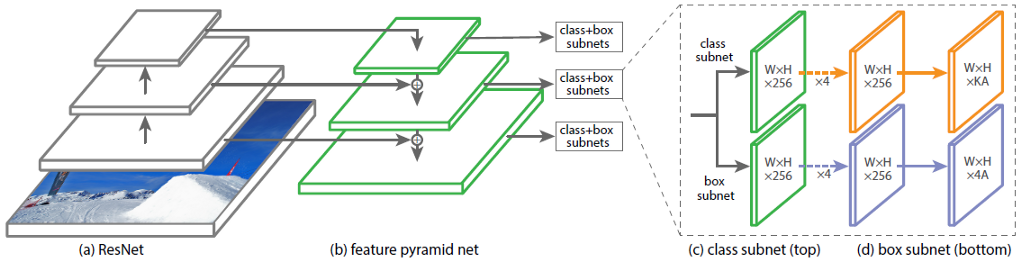
図1-ResNetバックボーンを備えたRetinaNetアーキテクチャー図1に
示されているRetinaNetの各部分を詳細に分析してみましょう。1。
バックボーンはRetinaNetネットワークの一部です
画像を入力として受け取り、重要な特徴を強調するRetinaNetアーキテクチャの部分は可変であり、この部分から抽出された情報は次の段階で処理されることを考えると、最適な結果を得るために適切なバックボーンネットワークを選択することが重要です。
CNN最適化に関する最近の研究により、以前に開発されたすべてのアーキテクチャよりも、ImageNetデータセットで最高の精度でパフォーマンスを10倍向上させる分類モデルが開発されました。これらのネットワークは、EfficientNet-B(0-7)と名付けられました。新しいネットワークのファミリーの指標を図1に示します。2.
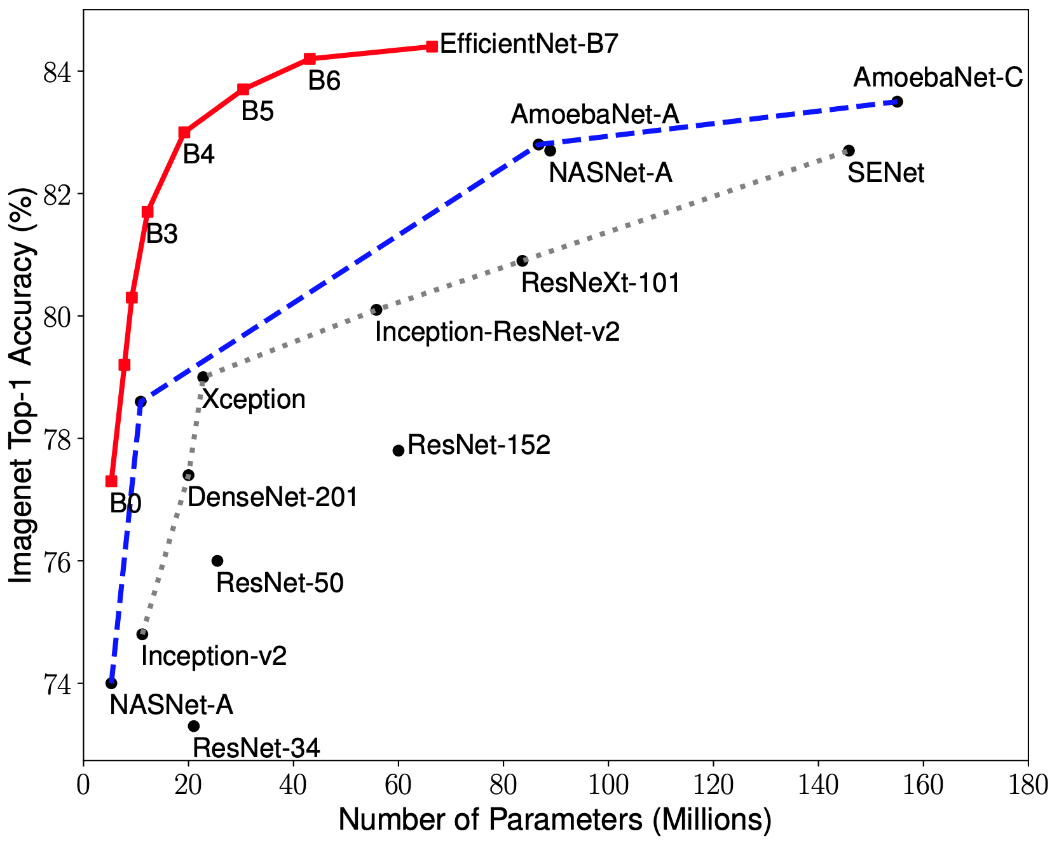
図2-さまざまなアーキテクチャーのネットワークの重みの数に対する最高精度のインジケーターの依存性のグラフ
標識のピラミッド
機能ピラミッドネットワークは、ボトムアップパスウェイ、トップダウンパスウェイ、横方向の接続という3つの主要な部分で構成されています。
上向きのパスは、一種の階層的な「ピラミッド」-私たちの場合、次元が減少する畳み込み層のシーケンス-バックボーンネットワークです。畳み込みネットワークの上位層はより意味論的意味を持っていますが、逆に解像度は低く、下位層は意味を持っています(図3)。ボトムアップパスには、特徴抽出に脆弱性があります。たとえば、バックグラウンドの小さいが重要なオブジェクトのノイズにより、オブジェクトに関する重要な情報が失われます。これは、ネットワークの終わりまでに、情報が高度に圧縮され、一般化されるためです。
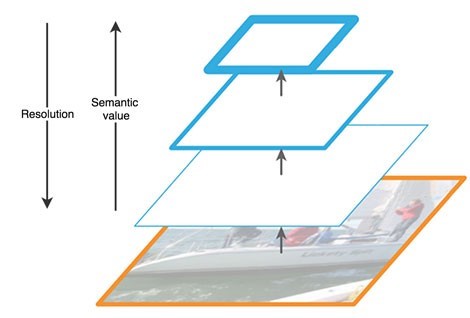
図3-ニューラルネットワークのさまざまなレベルでの機能マップの機能
下降経路も「ピラミッド」です。このピラミッドの最上層の特徴マップは、ボトムアップピラミッドの最上層の特徴マップのサイズを持ち、最近傍法(図4)によって下方向に2倍になっています。
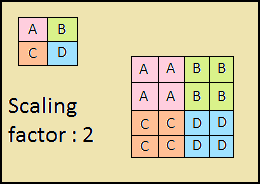
図4-最近傍法による画像解像度の
向上このように、トップダウンネットワークでは、上にあるレイヤーの各フィーチャマップが、下にあるマップのサイズまで増加します。さらに、FPNにはサイド接続が存在します。つまり、ピラミッドの対応するボトムアップレイヤーとトップダウンレイヤーのフィーチャマップが要素ごとに追加され、ボトムアップからのマップは1 * 1に折りたたまれます。このプロセスを図1に示します。 5.
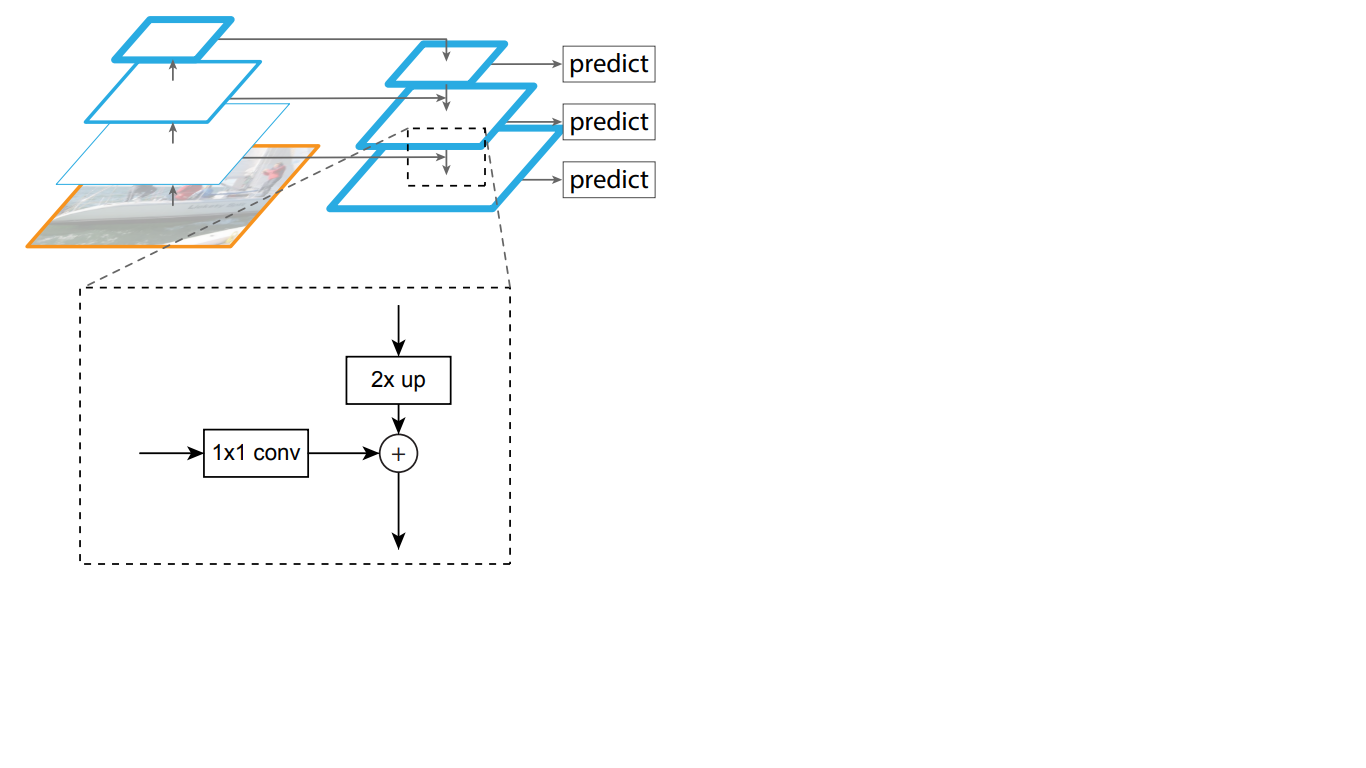
図5-標識のピラミッドの構造
横方向の接続は、レイヤーを通過する過程での重要な信号の減衰の問題を解決し、最初のピラミッドの終わりに受信した意味的に重要な情報と、その前に取得したより詳細な情報を組み合わせます。
さらに、トップダウンピラミッドの結果の各レイヤーは、2つのサブネットによって処理されます。
分類と回帰サブネット
RetinaNetアーキテクチャの3番目の部分は、分類と回帰の2つのサブネットです(図6)。これらのサブネットはそれぞれ、オブジェクトのクラスとイメージ上のその場所に関する応答を出力で形成します。それぞれがどのように機能するかを考えてみましょう。
図6-RetinaNetサブネット
考慮されるブロック(サブネット)の原則の違いは、最後のレイヤーまで変わりません。それらのそれぞれは、たたみ込みネットワークの4つの層で構成されています。レイヤーには256のフィーチャーマップが形成されます。 5番目のレイヤーでは、機能マップの数が変わります。回帰サブネットには4 * A機能マップがあり、分類サブネットにはK * A機能マップがあります。ここで、Aはアンカーフレームの数(次のサブセクションのアンカーフレームの詳細な説明)、Kはオブジェクトクラスの数です。
最後の6番目のレイヤーでは、各フィーチャマップが一連のベクトルに変換されます。出力の回帰モデルには、アンカーボックスごとに、アンカーボックスに対するグラウンドトゥルースボックスのオフセットを示す4つの値のベクトルがあります。分類モデルには、各アンカーフレームの出力に長さKのワンホットベクトルがあり、値1のインデックスは、ニューラルネットワークがオブジェクトに割り当てたクラス番号に対応します。
アンカーフレーム
前のセクションでは、アンカーフレームという用語を使用しました。アンカーボックスは、ニューラルネットワーク-検出器のハイパーパラメーターであり、ネットワークが動作する定義済みの境界矩形です。
ネットワークの出力に3 * 3の機能マップがあるとします。RetinaNetでは、各セルに9つのアンカーボックスがあり、それぞれサイズとアスペクト比が異なります(図7)。トレーニング中、アンカーフレームは各ターゲットフレームに一致します。IoU値の値が0.5の場合、アンカーフレームがターゲットとして割り当てられます。値が0.4未満の場合、背景と見なされます。それ以外の場合、アンカーフレームはトレーニングで無視されます。分類ネットワークは割り当てられた割り当て(オブジェクトクラスまたはバックグラウンド)に関連してトレーニングされ、回帰ネットワークはアンカーフレームの座標に関連してトレーニングされます(エラーはアンカーフレームに対して計算されますが、ターゲットフレームに対して計算されないことに注意することが重要です)。
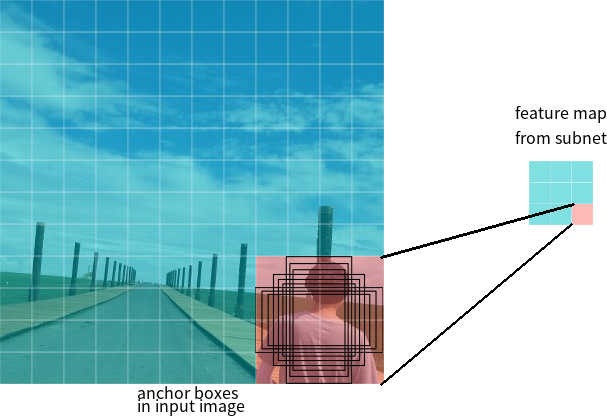
図7-サイズが3 * 3のフィーチャーマップの1つのセルのアンカーフレーム
損失関数
RetinaNetの損失は複合的であり、2つの値で構成されます:回帰またはローカリゼーションエラー(以下、Llocと呼びます)、および分類エラー(以下、Lclsと呼びます)。一般的な損失関数は次のように書くことができます:
ここで、λは2つの損失のバランスを制御するハイパーパラメーターです。
それぞれの損失の計算をより詳細に検討してみましょう。
前述のように、各ターゲットフレームにはアンカーが割り当てられます。これらのペアを(Ai、Gi)i = 1、... Nとして表します。ここで、Aはアンカーを表し、Gはターゲットフレーム、Nは一致したペアの数です。
アンカーごとに、回帰ネットワークは4つの数値を予測します。これはPi =(Pix、Piy、Piw、Pih)として表すことができます。最初の2つのペアは、アンカーAiとターゲットフレームGiの中心の座標間の予測差を表し、最後の2つのペアは、幅と高さの予測差を表します。したがって、ターゲットフレームごとに、Tiはアンカーフレームとターゲットフレームの差として計算されます。
ここで、smoothL1(x)は次の式で定義されます
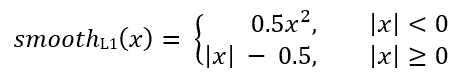
。RetinaNet分類の問題の損失は、Focal損失関数を使用して計算されます。
ここで、Kはクラスの数、yiはクラスのターゲット値、pはi番目のクラスを予測する確率、γはフォーカスパラメーター、αはバイアス係数です。この機能は、高度なクロスエントロピー機能です。違いは、クラスの不均衡の問題を解決するパラメーターγ∈(0、+∞)の追加にあります。トレーニング中、分類子によって処理されるオブジェクトのほとんどは、個別のクラスである背景です。したがって、ニューラルネットワークが背景を他のオブジェクトよりも適切に決定することを学習すると、問題が発生する可能性があります。新しいパラメーターの追加により、分類が容易なオブジェクトのエラー値を減らすことでこの問題を解決しました。フォーカルおよびクロスエントロピー関数のグラフを図8に示します。
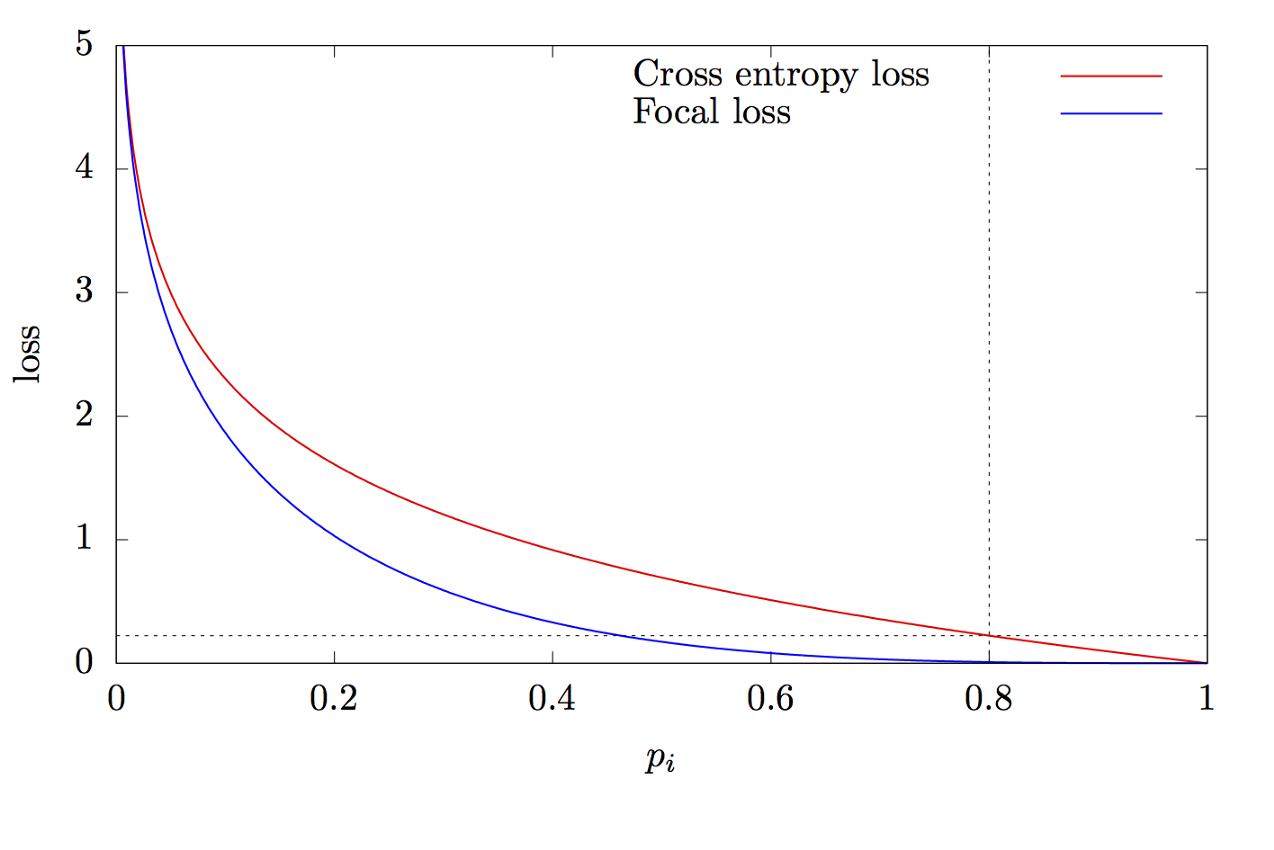
図8-焦点関数とクロスエントロピー関数のグラフ
この記事を読んでくれてありがとう!
ソースのリスト:
- Tan M., Le Q. V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 2019. URL: arxiv.org/abs/1905.11946
- Zeng N. RetinaNet Explained and Demystified [ ]. 2018 URL: blog.zenggyu.com/en/post/2018-12-05/retinanet-explained-and-demystified
- Review: RetinaNet — Focal Loss (Object Detection) [ ]. 2019 URL: towardsdatascience.com/review-retinanet-focal-loss-object-detection-38fba6afabe4
- Tsung-Yi Lin Focal Loss for Dense Object Detection. 2017. URL: arxiv.org/abs/1708.02002
- The intuition behind RetinaNet [ ]. 2018 URL: medium.com/@14prakash/the-intuition-behind-retinanet-eb636755607d